
NLP自然語言處理中英文分詞工具集錦與基本使用介紹
一、中文分詞工具
(1)Jieba

(2)snowNLP分詞工具

(3)thulac分詞工具

(4)pynlpir 分詞工具

(5)StanfordCoreNLP分詞工具
1.from stanfordcorenlp import StanfordCoreNLP
2.with StanfordCoreNLP(r'E:\Users\Eternal Sun\PycharmProjects\1\venv\Lib\stanford-corenlp-full-2018-10-05', lang='zh') as nlp:
3. print("stanfordcorenlp分詞:\n",nlp.word_tokenize(Chinese))
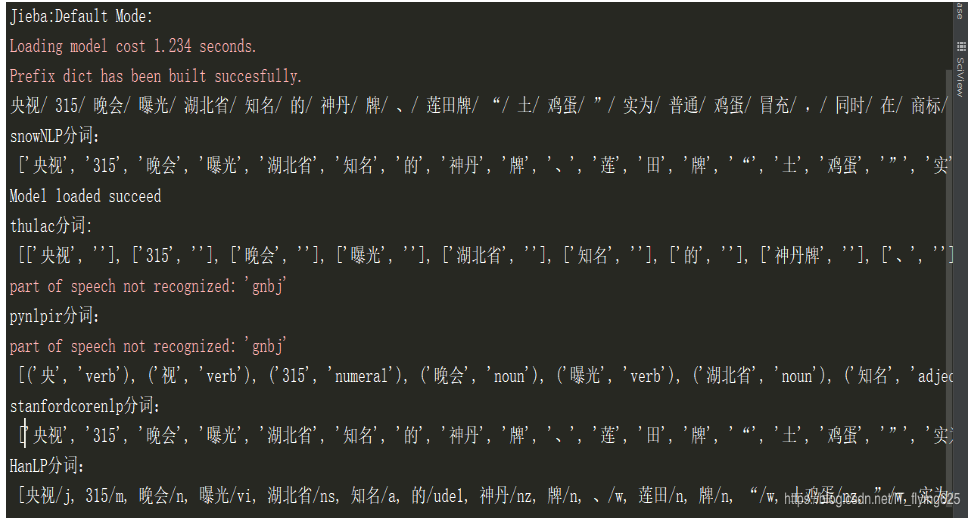
(6)Hanlp分詞工具

分詞結果如下:
二、英文分詞工具
1. NLTK:

二者之間的區別在於,如果先分句再分詞,那麼將保留句子的獨立性,即生成結果是一個二維列表,而對於直接分詞來說,生成的是一個直接的一維列表,結果如下:

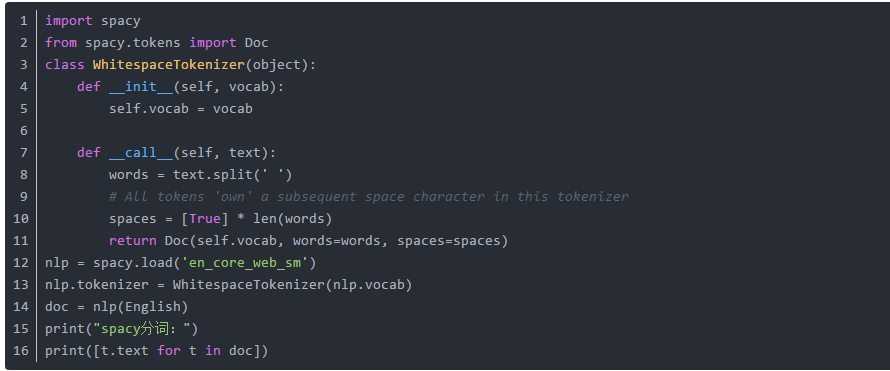
2. SpaCy:
3. StanfordCoreNLP:

分詞結果

相關推薦
NLP自然語言處理中英文分詞工具集錦與基本使用介紹
一、中文分詞工具 (1)Jieba (2)snowNLP分詞工具 (3)thulac分詞工具 (4)pynlp
自然語言處理——中文分詞原理及分詞工具介紹
本文首先介紹下中文分詞的基本原理,然後介紹下國內比較流行的中文分詞工具,如jieba、SnowNLP、THULAC、NLPIR,上述分詞工具都已經在github上開源,後續也會附上github連結,以供參考。 1.中文分詞原理介紹 1.1 中文分詞概述 中文分詞(Chinese Word Seg
自然語言處理之分詞、命名主體識別、詞性、語法分析-stanfordcorenlp-NER(二)
轉載請註明出處:https://blog.csdn.net/HHTNAN 在前面我們介紹了Stanford CoreNLP, 自然語言處理之命名實體識別-tanfordcorenlp-NER(一) 功能列表 工具以及對各種語言的支援如下表(英文和中文支援的最好),分別對應:
自然語言處理-中文分詞方法總結
中文分詞是中文文字處理的一個基礎步驟,也是中文人機自然語言互動的基礎模組。不同於英文的是,中文句子中沒有詞的界限,因此在進行中文自然語言處理時,通常需要先進行分詞,分詞效果將直接影響詞性、句法樹等模組的效果。當然分詞只是一個工具,場景不同,要求也不同。前人做的工
自然語言處理1 -- 分詞
1 概述 分詞是自然語言處理的基礎,分詞準確度直接決定了後面的詞性標註、句法分析、詞向量以及文字分析的質量。英文語句使用空格將單詞進行分隔,除了某些特定詞,如how many,New York等外,大部分情況下不需要考慮分詞問題。但中文不同,天然缺少分隔符,需
自然語言處理--中文分詞之機械分詞
說到自然語言處理,對於中文首當其衝的就是分詞。 和西方語言不同,中文句子中不像英語,每個單詞間有空格隔開,而是全部連在一起,詞間沒有明顯的界限。這就為我們的翻譯、檢索等等更高階的資訊處理帶來了不小的麻煩,怎樣將一句話中的關鍵詞提取出來,便成為了中文資訊處理首先要
自然語言處理之hanlp,Python呼叫與構建,分詞、關鍵詞提取、命名主體識別
HanLP是一系列模型與演算法組成的NLP工具包,由大快搜索主導並完全開源,目標是普及自然語言處理在生產環境中的應用。HanLP具備功能完善、效能高效、架構清晰、語料時新、可自定義的特點。在Python中一種是直接呼叫hanlp的介面pyhanlp.還有就是
[NLP自然語言處理]谷歌BERT模型深度解析
BERT模型程式碼已經發布,可以在我的github: NLP-BERT--Python3.6-pytorch 中下載,請記得start哦 目錄 一、前言 二、如何理解BERT模型 三、BERT模型解析 論文的核心:詳解BE
Python自然語言處理—停用詞詞典
一 過濾文字 去除停用詞典和錯詞檢錯都可以用詞典的形式完成,以停用詞為例,我使用的應該是知網提供的中文停用詞典。測試的資料集是小學生數學題。 print(text) # 列印未去除停用詞前版本 with open(r"C:\Users\BF\Desktop\NLTK\stopwords.
NLP自然語言處理例項:預測天氣冷暖
NLP:自然語言處理(Natural Language Processing)是人工智慧和語言學領域的分支學科。主要包括自然語言理解和生成,自然語言理解系統把自然語言轉化為計算機程式更易於處理的形式即讓電腦懂人類的語言。自然語言生成系統把計算機資料轉化自然語言。 處理過程:形式化描述->數
NLP自然語言處理常用的Python庫 及安裝方法
1、NLTK Natural Language Toolkit,自然語言處理工具包,在NLP領域中,最常使用的一個Python庫。 安裝:pip install nltk 2、Gensim 可以用來從文件中自勱提取語義主題。它包含了很多非監督學習演算法如:TF/IDF,潛在語義分
facebook NLP 自然語言處理框架 Pytext 簡介
自然語言處理(NLP)在現代深度學習生態中越來越常見。從流行的深度學習框架到雲端API的支援,例如Google雲、Azure、AWS或Bluemix,NLP是深度學習平臺不可或缺的部分。儘管已經取得了令人難以置信的進步,但構建大規模的NLP應用依然還有極大的挑戰,在學習研究和生產部署之間還存
自然語言處理中的詞袋模型
詞袋模型 from sklearn.feature_extraction.text import CountVectorizer import os import re import jieba.posseg as pseg # 載入停用詞表 stop_
Deep Learning及NLP(自然語言處理)雜談--第二部分
本雜談分為三個部分,此文為第二部分。 第二部分總結 這一部分主要講了四個對NLP方面效果比較好的模型:1.GRUs(Gated Feedback Recurrent Neural Networks) 2.LSTMs(Long Short-Term Memory]
NLP--自然語言處理與機器學習會議
整理至11月中旬在重慶參加的自然語言處理與機器學習會議,第一講為自然語言處理。 由基本理論到實際運用,整理了基本的框架。 1. 自然語言處理基礎 詞性標註(POS): 為句子中的每個詞語標註詞性,可看做是句法分析的關鍵任務,也可以看做是句法分析的最低層次.對後
NLP自然語言處理相關技術說明及樣例(附原始碼)
https://segmentfault.com/a/1190000010320214 1、簡單概述 1.1 NLP概念 NLP(Natural Language Processing),自然語言處理,又稱NLU(Natural Language Understan
Deep Learning及NLP(自然語言處理)雜談--第三部分
歡迎轉載,轉載請註明出處: 本雜談分為三個部分,此文為第一部分。 第一部分 第二部分 第三部分 第三部分 這一部分只介紹了一個model,就是在CV領域大名鼎鼎的CNN其他課程大多請的外賓過來講課,講得都是DL如何在實際情況下的應用。 CNN
自然語言處理中傳統詞向量表示VS深度學習語言模型(三):word2vec詞向量
在前面的部落格中,我們已經梳理過語言表示和語言模型,之所以將這兩部分內容進行梳理,主要是因為分散式的詞向量語言表示方式和使用神經網路語言模型來得到詞向量這兩部分,構成了後來的word2vec的發展,可以說是word2vec的基礎。1.什麼是詞向量
NLP自然語言處理庫系列教程——gensim庫
Gensim是一款開源的第三方Python工具包,用於從原始的非結構化的文字中,無監督地學習到文字隱層的主題向量表達。它支援包括TF-IDF,LSA,LDA,和word2vec在內的多種主題模型演算法,支援流式訓練,並提供了諸如相似度計算,資訊檢索等一些常用任務
NLP自然語言處理入門-- 文本預處理Pre-processing
檢查 bag 領域 影響 rds except clean numpy 我只 引言 自然語言處理NLP(nature language processing),顧名思義,就是使用計算機對語言文字進行處理的相關技術以及應用。在對文本做數據分析時,我們一大半的時間都會花在文本