
Caffe fine-tuning 微調網路
目前呢,caffe,theano,torch是當下比較流行的Deep Learning的深度學習框架,樓主最近也在做一些與此相關的事情。在這裡,我主要介紹一下如何在Caffe上微調網路,適應我們自己特定的新任務。一般來說我們自己需要做的方向,比如在一些特定的領域的識別分類中,我們很難拿到大量的資料。因為像在ImageNet上畢竟是一個千萬級的影象資料庫,通常我們可能只能拿到幾千張或者幾萬張某一特定領域的影象,比如識別衣服啊、標誌啊、生物種類等等。在這種情況下重新訓練一個新的網路是比較複雜的,而且引數不好調整,資料量也不夠,因此fine-tuning微調就是一個比較理想的選擇。
微調網路,通常我們有一個初始化的模型引數檔案,這裡是不同於training from scratch,scrachtch指的是我們訓練一個新的網路,在訓練過程中,這些引數都被隨機初始化,而fine-tuning,是我們可以在ImageNet上1000類分類訓練好的引數的基礎上,根據我們的分類識別任務進行特定的微調。
這裡我以一個車型的識別為例,假設我們有431種車型需要識別,我的任務物件是車,現在有ImageNet的模型引數檔案,在這裡使用的網路模型是CaffeNet,是一個小型的網路,其實別的網路如GoogleNet也是一樣的原理。那麼這個任務的變化可以表示為:
任務:分類
類別數目:1000(ImageNet上1000類的分類任務)------> 431(自己的特定資料集的分類任務431車型)那麼在網路的微調中,我們的整個流程分為以下幾步:
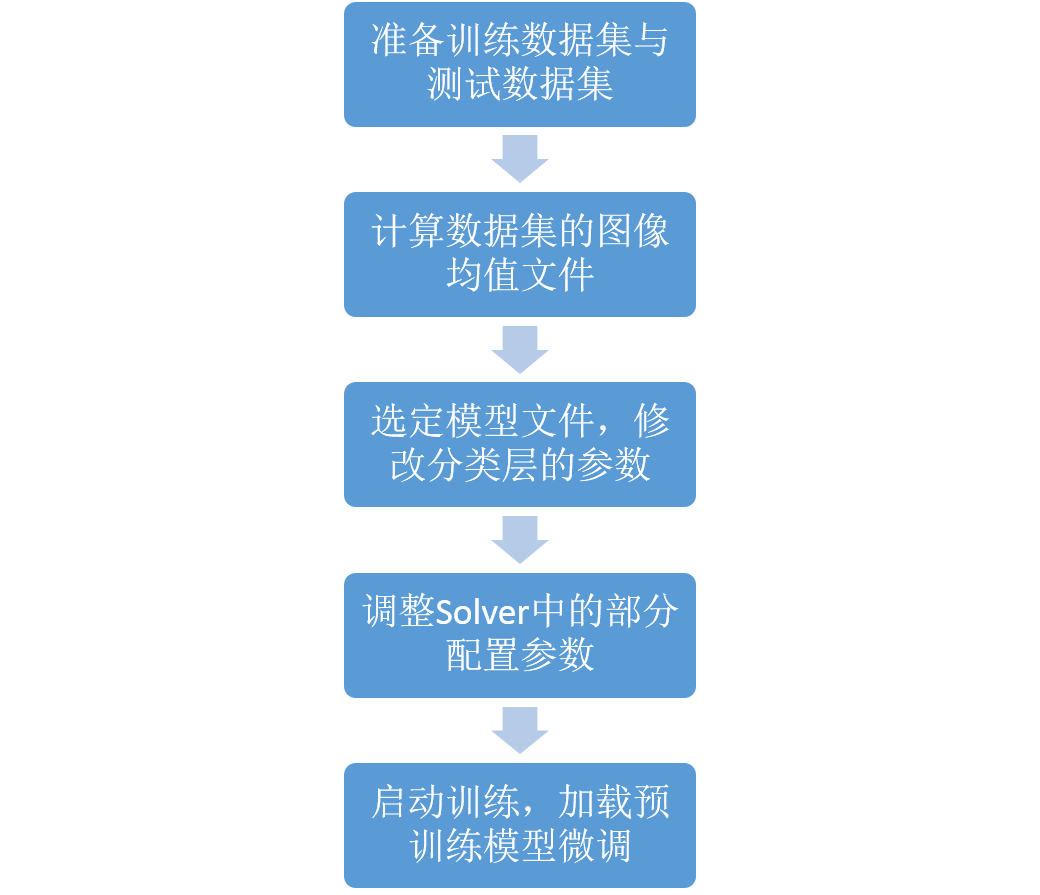
- 依然是準備好我們的訓練資料和測試資料
- 計算資料集的均值檔案,因為集中特定領域的影象均值檔案會跟ImageNet上比較General的資料的均值不太一樣
- 修改網路最後一層的輸出類別,並且需要加快最後一層的引數學習速率
- 調整Solver的配置引數,通常學習速率和步長,迭代次數都要適當減少
- 啟動訓練,並且需要載入pretrained模型的引數
簡單的用流程圖示意一下:
1.準備資料集
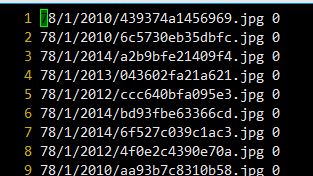
這一點就不用說了,準備兩個txt檔案,放成list的形式,可以參考caffe下的example,影象路徑之後一個空格之後跟著類別的ID,如下,這裡記住ID必須從0開始,要連續,否則會出錯,loss不下降,按照要求寫就OK。
這個是訓練的影象label,測試的也同理
2.計算資料集的均值檔案
使用caffe下的convert_imageset工具
具體命令是
/home/chenjie/louyihang/caffe/build/tools/convert_imageset /home/chenjie/DataSet/CompCars/data/cropped_image/ ../train_test_split/classification/train_model431_label_start0.txt ../intermediate_data/train_model431_lmdb -resize_width=227 -resize_height=227 -check_size -shuffle true
其中第一個引數是基地址路徑用來拼接的,第二個是label的檔案,第三個是生成的資料庫檔案支援leveldb或者lmdb,接著是resize的大小,最後是否隨機圖片順序
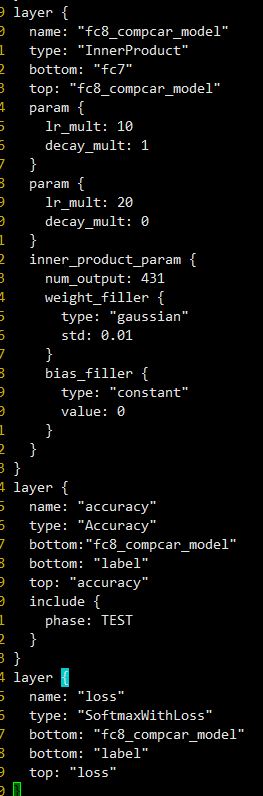
3.調整網路層引數
參照Caffe上的例程,我用的是CaffeNet,首先在輸入層data層,修改我們的source 和 meanfile, 根據之前生成的lmdb 和mean.binaryproto修改即可
最後輸出層是fc8,
1.首先修改名字,這樣預訓練模型賦值的時候這裡就會因為名字不匹配從而重新訓練,也就達成了我們適應新任務的目的。
1.調整學習速率,因為最後一層是重新學習,因此需要有更快的學習速率相比較其他層,因此我們將,weight和bias的學習速率加快10倍。
原來是fc8,記得把跟fc8連線的名字都要修改掉,修改後如下
4.修改Solver引數
原來的引數是用來training from scratch,從原始資料進行訓練的,因此一般來說學習速率、步長、迭代次數都比較大,在fine-tuning 微調呢,也正如它的名字,只需要微微調整,以下是兩個對比圖
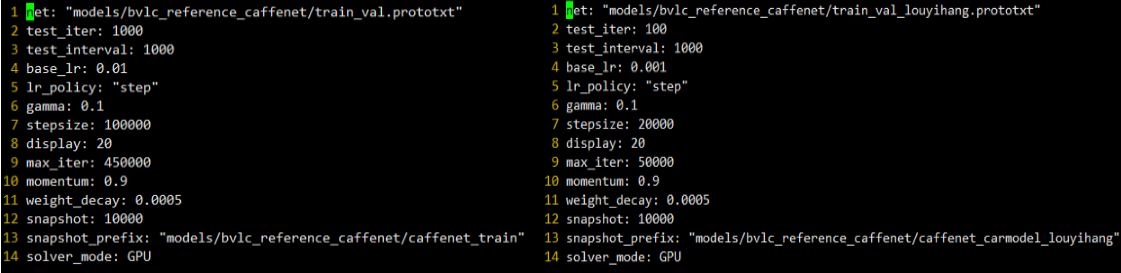
主要的調整有:test_iter從1000改為了100,因為資料量減少了,base_lr從0.01變成了0.001,這個很重要,微調時的基本學習速率不能太大,學習策略沒有改變,步長從原來的100000變成了20000,最大的迭代次數也從450000變成了50000,動量和權重衰減項都沒有修改,依然是GPU模型,網路模型檔案和快照的路徑根據自己修改
5.開始訓練!
首先你要從caffe zoo裡面下載一下CaffeNet網路用語ImageNet1000類分類訓練好的模型檔案,名字是bvlc_reference_caffenet.caffemodel
訓練的命令如下:

OK,最後達到的效能還不錯accuray 是0.9,loss降的很低,這是我的caffe初次體驗,希望能幫到大家!
相關推薦
Caffe fine-tuning 微調網路
目前呢,caffe,theano,torch是當下比較流行的Deep Learning的深度學習框架,樓主最近也在做一些與此相關的事情。在這裡,我主要介紹一下如何在Caffe上微調網路,適應我們自己特定的新任務。一般來說我們自己需要做的方向,比如在一些特定的領域的識別分類中,我們很難拿到大量的資料。因為像在
深度學習之模型fine-tuning(微調網路)
目前呢,caffe,theano,torch是當下比較流行的Deep Learning的深度學習框架,樓主最近也在做一些與此相關的事情。在這裡,我主要介紹一下如何在Caffe上微調網路,適應我們自己特定的新任務。一般來說我們自己需要做的方向,比如在一些特定的領域的識別分類中,我們很難拿到大量的資料。因為像在
caffe微調網路時的注意事項(持續更新中)
轉載請註明出處,樓燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ 目前呢,caffe,theano,torch是當下比較流行的Deep Learning的深度學習框架,樓主最近也在做一些與
SSD+caffe︱Single Shot MultiBox Detector 目標檢測+fine-tuning(二)
承接上一篇SSD介紹:SSD+caffe︱Single Shot MultiBox Detector 目標檢測(一) 如果自己要訓練SSD模型呢,關鍵的就是LMDB格式生成,從官方教程weiliu89/caffe來看,寥寥幾行code,但是前面的資料
caffe 教程 Fine-tuning a Pretrained Network for Style Recognition下載資料
問題:執行python examples/finetune_flickr_style/assemble_data.py --workers=1 --images=2000 --seed 831486命令下載Flickr Style資料,然而提示:Writing
實驗——基於pytorch的超分和去噪網路聯合fine tuning
本博文是本人實現超分和去噪網路聯合訓練與fine tuning的實驗筆記 先基於之前博文《基於pytorch的噪聲估計網路》處理的噪聲圖片,進行bicubic downsample的操作(應該先bicubic再加噪) 進入對應子目錄下,執行 $ matlab -nodes
caffe學習筆記17-find-tuning微調學習
find-tuning: 對已有模型進行find-tuning(softmax層的變動,只需要微調),比如我們現在有一個1000類的分類模型,但目前我們的需求僅是20類,此時我們不需要重新訓練一個模型,只需要將最後一層換成20類的softmax層,然後使用
單通道灰度圖片fine-tune訓練網路與caffe批量分類測試
1. 轉imdb灰度圖資料 一定要加上--gray,否則訓練時報如下錯誤: GLOG_logtostderr=1 $TOOLS/convert_imageset \ --resize_height=$RESIZE_HEIGHT \ --resize_w
caffe學習筆記2:Fine-tuning一個類別識別的預處理的網
Fine-tuning一個預處理的網用於型別識別(Fine-tuning a Pretrained Network for Style Recognition) 本文原文地址here 在這個實驗中,我們我們探索一個通用的方法,這個方法在現實世界的應用中非常的
caffe中fine-tuning的那些事
caffe是一個深度學習框架,在建立好神經網路模型之後,使用大量的資料進行迭代調引數獲取到一個擬合的深度學習模型caffemodel,使用這個模型可以實現我們需要的任務。 如果對caffe並不是特別熟悉的話,從頭開始訓練一個模型會花費很多時間和精力,需要對整
Windows下caffe用fine-tuning訓練好的caffemodel來進行影象分類
小菜準備了幾張驗證的圖片存放路徑為caffe根目錄下的 examples/images/, 如果我們想用一個微調訓練好的caffemodel來對這張圖片進行分類,那該怎麼辦呢?下面小菜來詳細介紹一下這一任務的步驟。一般可以同兩種方式進行測試,分別是基於c++介
Windows平臺基於Caffe框架的LeNet網路訓練
在Windows平臺下使用Caffe的確不如Linux來的方便,至少人家把Shell都已經寫好了。但是像我這種VS重度依賴者,還是離不開微軟大腿呀…廢話不多說,一步步來吧 0. 為了後續檔案路徑訪問的便利,我們先將$CAFFE_ROOT根目錄新增到作業系統環境變數PATH中,
Caffe訓練深度學習網路的暫停與繼續
Caffe訓練深度學習網路的暫停與繼續 博主在訓練Caffe模型的過程中,遇到了如何暫停訓練並斷點繼續訓練的問題。在此記錄下有關這個問題的幾種解決方案。更新於2018.10.27。 方法1:臨時暫停 這種方法是用於臨時暫停Caffe訓練,暫停後可以以完全相同的配置從斷點處繼續
如何fine tuning
為什麼要fine-tuning?### 我們有自己的影象識別任務,然而我們的資料集太小,直接進行訓練很容易出現過擬合現象 所以比較好的解決方案是先在一個大資料集中訓練以提取比較準確的淺層特徵,然後再針對這個訓練過的網路利用我們的資料集進行訓練,那麼效果就會好很多。這個過程就是fine-t
在caffe中固定某些網路引數,只訓練某些層
實現的關鍵變數是:propagate_down 含義:表示當前層的梯度是否向前傳播 比如有4個全連線層A->B->C->D a. 你希望C層的引數不會改變,C前面的AB層的引數也不會改變,這種情況也就是D層的梯度不往前反向傳播到D層的輸入bl
Caffe學習筆記1:linux下建立自己的資料庫訓練和測試caffe中已有網路
本文是基於薛開宇 《學習筆記3:基於自己的資料訓練和測試“caffeNet”》基礎上,從頭到尾把實驗跑了一遍~對該文中不清楚的地方做了更正和說明。 主要工作如下: 1、下載圖片建立資料庫 2、將圖片轉化為256*256的lmdb格式 3、計算影象均值 4、定義網路修改部分引
Fine-tuning Approaches -- OpenAI GPT 學習筆記
1、Fine-tuning Approaches 從語言模型轉移學習的一個趨勢是,在監督的下游任務中相同模型的微調之前,一個語言模型目標上預訓練一些模型體系結構。這些方法的優點是幾乎沒有什麼引數需要從頭學習。至少部分由於這一優勢,OpenAI GPT在GLUE
使用pycaffe進行的fine-tuning的過程
最近在進行caffe的fine-tuning的實驗,在此做個簡單地介紹和總結,方便以後的查詢。 pre-trainning 與 fine-tuning 簡單介紹 在使用大型網路的時候,經常是自己的資料集有限,為此常常會使用現已成熟的網路結構,如:alexnet,Google
【佔坑】Pre-train 與 Fine-tuning
Pre-train的model: 就是指之前被訓練好的Model, 比如很大很耗時間的model, 你又不想從頭training一遍。這時候可以直接download別人訓練好的model, 裡面儲存
Keras —— 遷移學習fine-tuning
該程式演示將一個預訓練好的模型在新資料集上重新fine-tuning的過程。我們凍結卷積層,只調整全連線層。 在MNIST資料集上使用前五個數字[0…4]訓練一個卷積網路。 在後五個數字[5…9]用