
轉:《七週成為資料分析師》總結
百日計劃第一週總結
1. 計劃
1.徹底結束之前預定暑假完成的天善學院課程《七週資料分析師》
2.總結《七週資料分析師》。
2. 完成情況
1.完成《七週成為資料分析師》任務
2.周總結與《七週資料分析師》一起完成。
《七週資料分析師》總結
第一週:資料分析思維
1.核心資料分析思維
- 結構化
- 公式化
- 業務化
2.資料分析思維七大技巧
- 象限法
- 多維法
- 假設法
- 指數法
- 80/20法則(帕累托法則)
- 對比法
- 漏斗法
3.資料分析思維鍛鍊方法
- 好奇心!
- 案例分析
- 啤酒與尿布
- 去思考生活中商業案例的表現,背後的原理、擺放方法和資料差異
- 生活中的練習
- 例如夜市,一天的人流量?一人的流量?營業額?資料的分析方式?
- 換做你是商家,如何提高店面的利潤?
- 工作中的練習
- 為什麼領導和同事不認可?
- 如果我職位更高,我會怎麼分析?
- 覆盤,對於一個月,一年前等等的案例進行對比。需要,每個案例有記筆記的習慣,效果更好
- 歷史分析,用這三種分析思維,分析更多的事情。結構化,公式化,業務化。
4.總結
- 核心思維為重點!結合案例理解了,這三種思維的重要性,運用範圍極廣,對於問題的思考都可以從這三方面開展。
- 七大技巧,展示了具體的分析技巧,但是需要配合分析工具如Python、excel中去實現他,需要記住特點,在需要時運用到資料分析中
- 資料分析思維的鍛鍊,來自於長期的思考習慣,從生活、案例和工作中日積月累的思考與積累,通過自己真正“思考”出來的結果,才是“真正”理解的思維。
第二週:業務篇-指標
1.為什麼業務重要
唯有理解業務,才能建立完整的一套體系,簡稱業務資料模型。
想進入某個行業的資料分析,儘量需要一些業務知識,敲門磚。
2.經典的業務分析指標
模型未動,指標先行。
如果你不能衡量它,你就不能無法增長它
運用第一週的核心思維:結構化、公式化和業務化,形成指標。

指標建立的要點:
- 核心指標(公司和部門都認同的大目標,根據實際公司情況而認定)
- 好的指標應該是比率
- 好的指標能帶來顯著效果
- 好的指標不應該虛榮(如投入的錢很多,新增使用者量大)
- 好的指標不應該複雜
3.市場營銷指標
市場營銷領域:
1.客戶/使用者生命週期
- 企業/產品和消費者再整個業務關係階段的週期。
- 不同業務劃分的階段不同。傳統營銷中,分為潛在使用者,興趣使用者,新客戶,老客戶,流失客戶。
2.使用者價值
- 業務領域千千萬萬,怎樣定義最有效使用者?
- 使用者貢獻=產出量/投入量*100%
- 使用者價值=貢獻1+貢獻2+…
- 金融行業的使用者價值,大概可以為存款+貸款+信用卡+年費+…-風險
RFM模型
具體看業務背景,確立RFM模型中的重心,進行更改和修正。
使用者分群,營銷矩陣
提取使用者的幾個核心維度,例如RFM,用象限法將其歸納和分類

3. 產品運營指標
AARRR框架
使用者獲取,使用者活躍,使用者留存,營收,傳播
1.使用者獲取
- 渠道到達量:俗稱曝光量。有多少人看到產品推廣相關的線索。
- 渠道轉換率:有多少使用者因為曝光而心動Cost Per,包含CPM、CPC、CPS、CPD和CPT等。
- 渠道ROI:推廣營銷的熟悉KPI,投資回報率,利潤/投資* 100
- 日應用下載量:App的下載量,這裡指點選下載,不代表下載完成。
- 日新增使用者數:以使用者註冊提交資料為基準
- 獲客成本:為獲取一位使用者需要支付的成本
- 一次會話使用者數佔比:指新使用者下載完App,僅開啟過產品一次,且該次使用時長在2分鐘以內。(衡量渠道可靠程度)
2.使用者活躍
- 日/周/月活躍使用者應用下載量:活躍標準是使用者用過的產品,廣義上,網頁遊覽內容算用,公眾號下單算用,不限於開啟APP。
- 活躍使用者佔比:活躍使用者數再總使用者數的比例,衡量的是產品健康程度
- 使用者會話session次數:使用者開啟產品操作和使用,直到推出產品的整個週期。5分鐘無操作,預設結束
- 使用者訪問時長:一次會話的持續時間。
- 使用者平均訪問次數:一段時間內的使用者平均產生會話次數。
3.使用者留存
使用者在某段時間內使用產品,過了一段時間後仍舊繼續使用的使用者。
4.營收
- 付費使用者數:花了錢的
- 付費使用者數佔比:每日付費使用者佔活躍使用者數比,也可以計算總付費使用者佔總使用者數比
- ARPU:某個時間段內,每位使用者平均收入
- ARPPU:某時間段內每位付費使用者平均收入,排除了未付費。
- 客單價:每一位使用者平均購買商品的金額。銷量總額/顧客總數
- LTV:使用者生命價值週期,和市場營銷的客戶價值接近,經常用在遊戲運營電商運營中。
- LTV(經驗公式):ARPU*1/流失率(比如說,一月份有一百個使用者,這個月使用者流失率0.3,那麼1/流失率=3.3,那麼一月份這批客戶在3.3個月後流失光,這段時間的LTV=ARPU(使用者的平均消費100元) *3.3 =330元),適合敏捷專案
5.傳播
- K因子:每一個使用者能夠帶來幾個新使用者
- K因子=使用者數平均邀請人=人數邀請轉換率
- 使用者分享率:某功能/介面中,分享使用者數佔遊覽頁面人數佔比
- 活動/邀請曝光量:線上傳播活動中,該活動被曝光的次數
4. 使用者行為指標
1.使用者行為
- 沒有特別重要的框架,主要在於理解與應用。
- 功能使用率:使用某功能的使用者佔活動總活躍數之比。(比如點贊、評論、收藏、搜尋等等)
- 使用者會話:會話(session),是使用者在一次訪問過程中,從開始到結束的整個過程。在網頁端,30分鐘內沒有操作,預設會話操作結束
2.使用者路徑
路徑圖:使用者在一次會話的過程中,其訪問產品內部的遊覽軌跡,通過此,可以加工出關鍵路徑轉換率。

全產品路徑如上,但是關注關鍵路徑才重要。比如下單的路徑,觀察各個路徑的情況,進行優化。
5.電子商務指標
購物籃分析
- 筆單價:使用者每次購買支付的金額,即每筆訂單的支出,對應客單價
- 件單價:商品的平均價格
- 成交率:支付成功的使用者在總的客流量中的佔比
- 購物籃係數:平均每筆訂單中,賣出了多少商品,與商品關聯規則有關。
- 復購率:一段時間內多次消費的使用者佔到總消費使用者數之比(忠誠度)
- 回購率:一段時間內消費過的使用者,在下一段時間內仍然有消費行為的佔比(消費慾望)
6. 流量指標
1.遊覽量和訪客量
PV:遊覽次數。以發起請求次數來判定
UV:一定時間內訪問網頁的人數,UV會通過cookie或IP的訪問次數來判定次數
微信中的網頁,UV是不準確的,微信不會儲存cookies。
2.訪客行為
- 新老客戶佔比:衡量網站的生命力(適宜就好,過高過低就不行)
- 訪客時間:衡量內容質量,不是看內容的UV,而是內容的訪問時間。
- 訪客平均訪問頁數:衡量網站對訪客的吸引力,是訪問的深度
來源:與多維分析相關,訪客從哪裡來,遊覽方式?手機機型?通過來源網站的引數提取。
退出率:從該頁退出的頁面訪問數/進入該頁的訪問數(衡量網頁產品結構)
- 跳出率:遊覽單頁即退出的次數/訪問次數(衡量落地頁、營銷頁)
7.怎麼生存指標
組合!
- 訪客訪問時長+UV=重度訪問使用者佔比(遊覽時間五分鐘以上的使用者佔比)
- 使用者會話次數+成交率=有效消費會話佔比(使用者在所有的會話中,其中有多少次有消費?)
- 機器學習,PCA學習,指數法,生成指標。(偏應用)
8.總結
- 通過三大核心思維,分解-理解-尋找,得到重要的指標。
- 根據不同行業,運用不同合適的模型
- 公司在不同時期、階段和模式都有不同的指標,需要有根據目的,從更高層次去尋找有效的指標。
第二週:業務篇-框架與模型
1.業務的分析框架
- 從第一週資料分析思維,核心技巧,工具,都為了這部分做鋪墊。
- 讓指標形成閉環,成為真正靠譜的模型
從三個角度出發
- 從指標的角度出發
- 從業務的角度出發
- 從流程的角度出發
2.市場營銷模型

本質是樹形結構,從樹形思維導圖演變而來,但是加入閉環的迴圈結構。
3.AARRR模型

- 核心是形成閉環。
- 例子:餓了嗎紅包。
- 二次啟用:推送啟用率、有效推送到達率、使用者開啟率、不用推送的轉化率(可以使用漏斗圖)
4.使用者行為模型(內容平臺)

- 例如,知乎。完整閉環,各個環節都能進行分析
- 點贊/評論/收藏分析:點贊/評論/收藏使用者活躍佔比、內容指數等等
5.電子商務模型

遇到結構外的分析內容,在外面額外新增就行,如右上角。
分析各個節點,得到指標。例如,購物車分析:
- 不用商品類別的佔比(對比法)
- 不同價格檔次的佔比(象限法)
- 不同商品的下單支付率(漏斗法)
6.流量模型

指標結構框架如上,分析各個要點。
分析搜尋流量:

有些指標在其他模型也有,模型之間沒有嚴格界限,可以共同使用相同指標
怎麼從空白資料分析需求開始?
- 設立核心指標
- 經過三種核心思維
- 聚合成樹形圖
- 形成大量指標
- 將指標變成分析框架,閉環模型圖,例如上面案例
- 每個節點都能分析,利用上週的七大分析工具。
7.如何應對各類業務場景
新手,面對資料分析依然是沒有思路進行分析?
練習
重點,在於練習。參考上面,如何鍛鍊資料分析思維。
例如,出門的夜市商鋪、京東的電商產品框架、閱讀資訊軟體。
熟悉業務
從熟悉的入手培養業務sense
應用三種核心思維
開啟Xmind思維導圖,開始畫畫。
歸納和整理出指標
對於基本完整的思維導圖,提煉出,復購率、活躍度和使用者行為等等基本指標結合。
畫出框架
PPT,等等其他軟體。
檢查、應用、修正
沒有框架是完美的,在時間維度上需要檢查。
應用和迭代
在工作中應用,先從小問題開始,再把各個小問題組合成大問題。
8.如何應對業務場景(實踐測試)

以科賽資料分析平臺為例子,參考視訊,設計了一個分析體系。
9. 資料管理
- 30%資料統計,70%資料管理
- 資料管理,重中之重。一直銘記,以後一定會在資料這條路上走的更遠。
10.總結
- 框架,在某種程度上,是思維之下最高的體現。
- 框架儘量先形成閉環(樹形圖為核心),再逐點分析突破
- 通過設計框架,運用合適的指標,形成模型,實現最終的業務目標。
第三週:Excel篇
Excel常用於敏捷,快速,需要短時間相應的場景下是非常便捷的資料處理工具。
相對於語言類例如python和R等則用於常規的,規律的場景中應用,便於形成日常規則統計分析。
對於學習的路徑:Excel函式—>SQL函式——>python
必知必會內容:保證使用版本是2013+;培養好的資料表格習慣;主動性的搜尋;多練習
Excel常見函式
1.文字函式
- 查詢文字位置:find(“字元”,位置),常與left()提取所需要的位數組合使用。
- 文字拼接函式:concatenate
- 文字替換函式:replace
- 刪除字串中多餘的(前後的)空格:trim
- 文字長度:len()
2.關聯匹配函式
LOOKUP
VLOOKUP
INDEX:相當於陣列定位
MATCH:查詢資料在陣列中的位置
OFFSET:偏移函式
ROW
COLUMN
HYPERLINK:去掉超連結
3.邏輯運算函式
- ture—-1 false—–0 判斷是真是假
- 通常配合其他函式進行判斷,相加判斷滿足條件的個數
- if函式
- is系列函式
4.計算統計函式
- sum
- sumproduct:特殊用法—-直接累加對應相乘
- count
- max / min
- rank:查詢排名
- rand randbetween
- average
- quartile:分位數,第幾分位數
- stdev
- substotal:功能豐富,號稱“瑞士軍刀”
- int:向下取整函式
- round:四捨五入取整函式(可在小數點位置取整數)
rand:隨機數字,用來隨機抽樣使用
多條件就和和多條件計數的情況下是非常多的,所以countifs和sumifs用的是非常的多,基本能搞定所有的統計報表,達到實時統計。缺點就是資料量達到一定程度後,Excel執行會比較慢
5.時間序列
時間的本質是數字
周函式中,中國的習慣方式引數常選擇2
常用時間序列函式有:
- year
- month
- day
- date
- weekday
- now
- weeknum
- today
6.Excel使用常見技巧
快捷鍵
- ctrl+方向鍵,游標快速移動
- ctrl+shift+方向鍵,快速框選
- ctrl+空格鍵,選定整列
- shift+空格鍵,選定整行
- ctrl+A 選擇整張表
- alt+enter 換行
功能
- 分裂功能;查詢替換;資料條(視覺化);資料透視表(水晶表);凍結首行;
7.Excel常見工具
資料切片:進行快速篩選(一般和多維分析關聯在一起的),可以和作圖工具進行相關聯
應用場景:做統計報表和儀表盤的統計篩選功能
資料分析:直接對多想進行描述性統計
自定義名稱:再次使用可對其直接引用
刪除重複值:
下拉列表:
迷你圖:
8.總結
個人覺得主要還是在於實踐當中的靈活運用,作為學習,掌握有什麼樣的函式用來做什麼就可以了,工作中遇到的時候可能忘了怎麼拼,但是能直接搜尋把函式找出來用知道在哪裡面找就好。當然,記得更多的函式好處就是能迅速的通過函式的用法把函式靈活的組合去解決問題。其實最重要的也是通過邏輯關係把各種函式進行組合去解決問題。
第四周:資料視覺化
1.有用的圖表
對於資料視覺化,大多數人下意識是要好看,下意識的去追求美感,覺得高大尚。其實,美麗的圖表應該是有用的圖表。
資料視覺化的目的是讓資料更高效,讓讀者更高效的進行閱讀,而不是自己使用。好的視覺化能突出背後的規律,突出重要的因素,最後才是美觀。
資料視覺化的最終目的:資料作用的最大化。
2.常見的圖表
1.散點圖
核心:展現資料之間的規律

呈現出一定規律的散點圖可增加趨勢線,並通過選項將規律用公式表示出來。
改進圖:
- 氣泡圖:散點圖的變種,引入第三個度量單位作為氣泡的大小
- 單軸散點圖

2.折線圖

3.柱形圖

4.餅形圖

用面積區分大小,很多情況下肉眼是很難區分的,上圖為玫瑰圖—餅圖的變種
5.漏斗圖

6.雷達圖

3.高階圖表
1.樹形圖
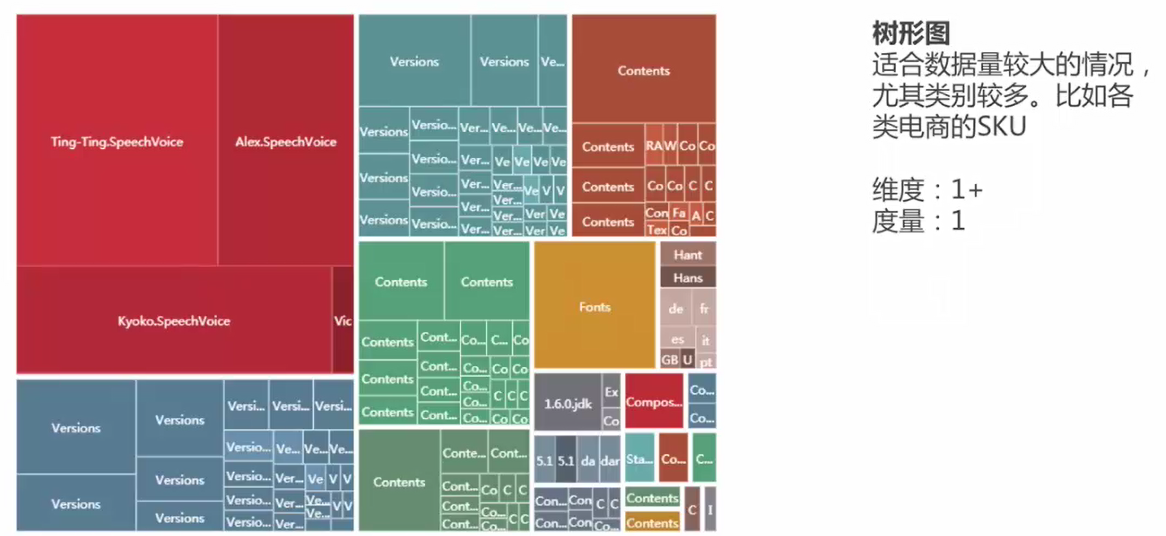
資料量較大、資料類別較多時,能更好的體現資料分類情況。
2.桑基圖
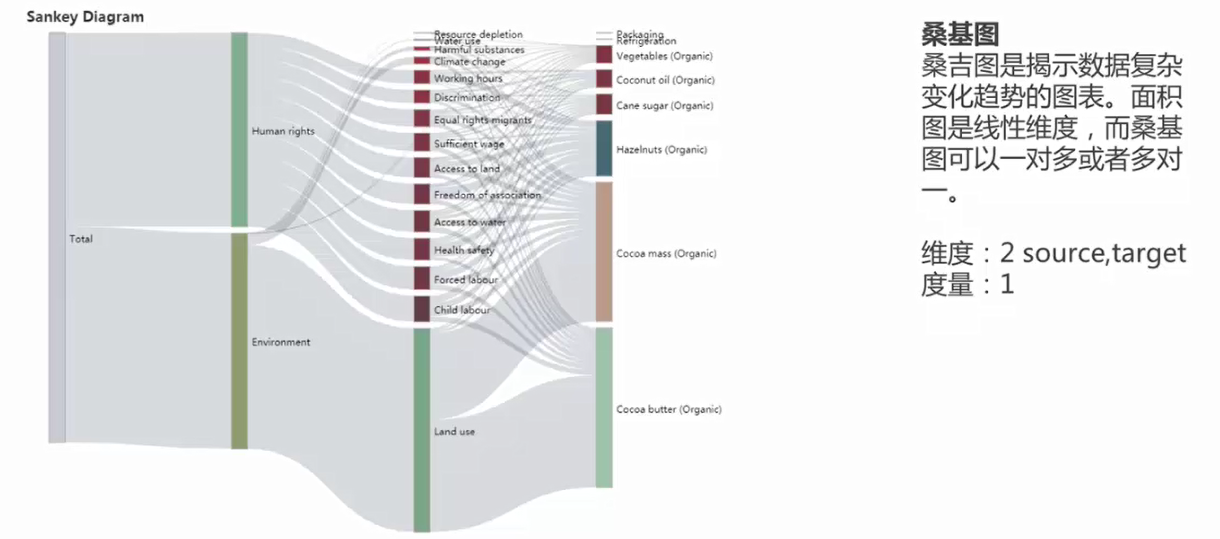
繪製流量變動最開始,網站的流量,監視使用者的行為分析,表示使用者在網站上的行為軌跡,一對多或多對一的關係
3.熱力圖
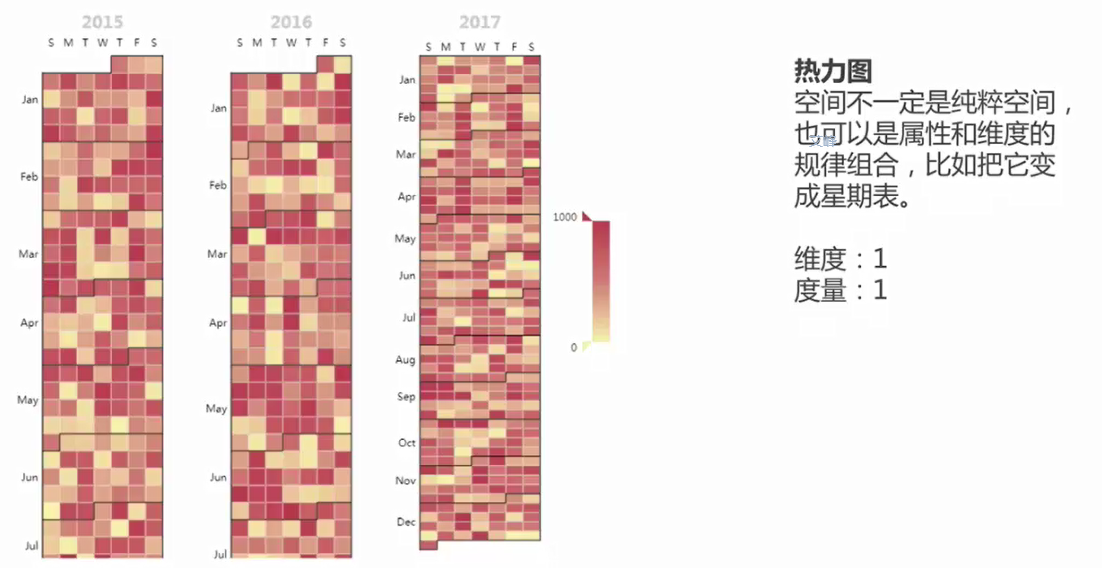
資料上下波動可用折線圖觀察,但是中間的某種關係展示揭示特殊關係使用熱力圖則可看出來。
4.關係圖
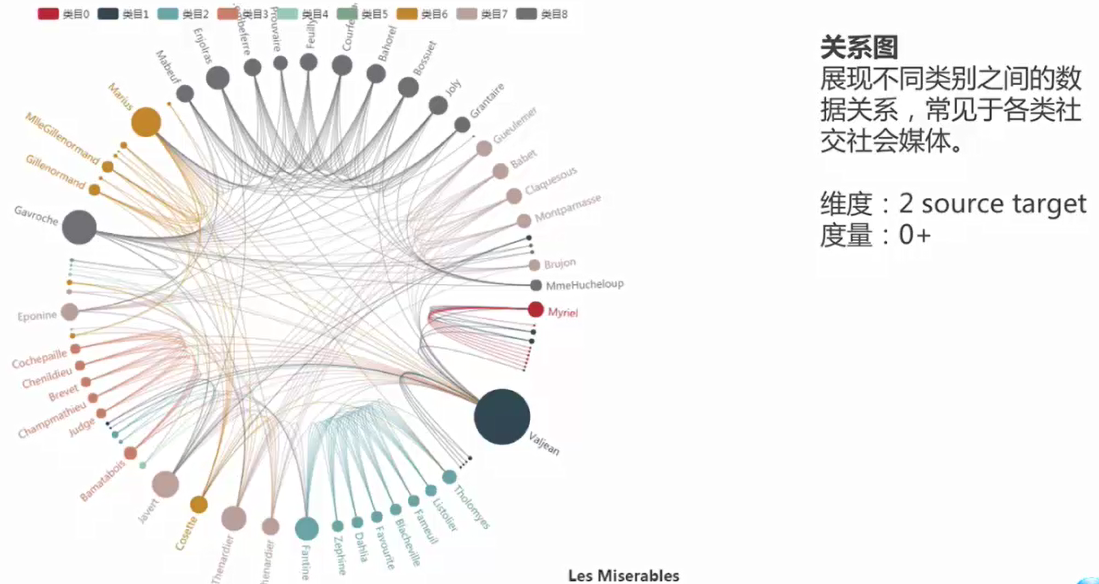
社交,社會媒體,微博的傳播,使用者和使用者之間的關注等
5.箱線圖

揭示資料的分佈情況
6.標靶圖

7.詞雲圖

8.地理圖
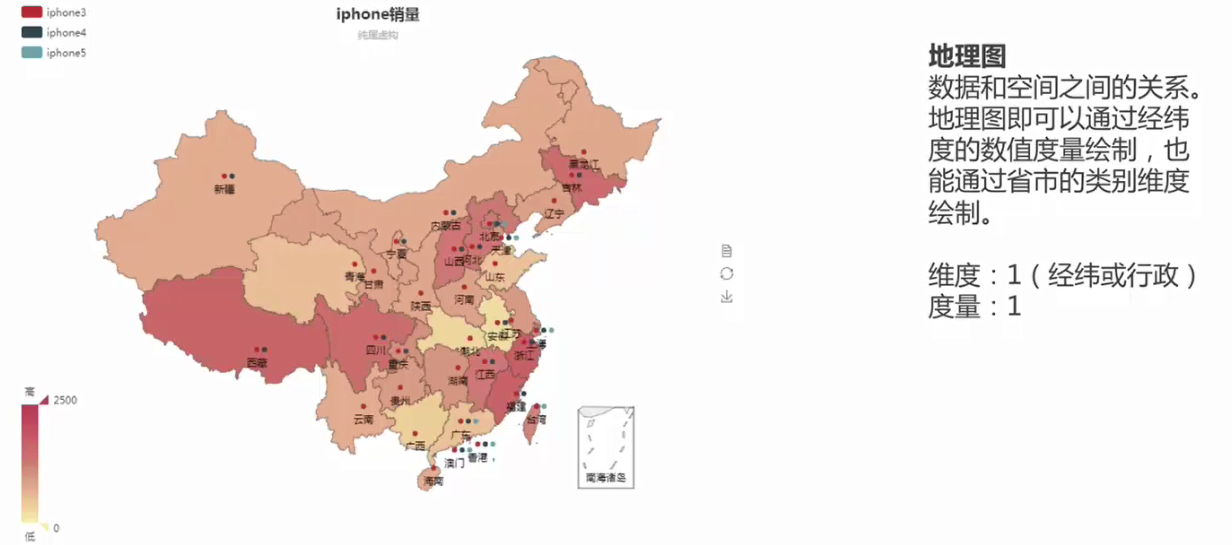
資料和空間的關係
4.圖表繪製工具與技巧
1.繪製工具
- 初級—Excel
- 中高階—程式設計python、R和BI工具
2.繪製技巧
1.顏色搭配
color.adobe.com上有多種主流顏色搭配
2.顏色搭配原則
- 把需要聚焦的資料進行顏色凸顯
- 去掉多餘沒有用的元素
- 橫縱輔助線如果對肉眼觀察無幫助則去掉
- 在報告中,內容交給單元格來解決
- 有設計規範
3.次座標軸的使用,使得資料能體現更多細節。
3.杜邦分析法

5.Power BI
1.BI基本功能要素
- 單一圖表沒有意義,三表成虎,通過多表多因素展現分析。注意設計的表格揭示的是現象?還是原因?
- BI中,power BI和Tableau是最著名的BI軟體。其中,Power BI免費易用適合新手入門。

BI中的資料鏈接,最好直接連線資料庫或者CSV檔案,儘量不要xls檔案。
power BI 的功能特點:
- 製作的圖表可以進行聯動
- 多對對的關係不能進行關聯
- power BI內的函式使用與Excel的函式應用基本一致,不建議話太多的精力去學power BI裡面的函式。
- 建議使用Excel將資料進行清洗後,再已.csv的形式匯入BI內進行操作。
- power BI可以引入第三方的一些高階功能(80%都是微軟自己的)來滿足使用者需求,例如新增更多的圖表形式,詞雲圖等等。
2.Dashbord
- 佈局和設計要素:主次分明+貼合場景+指標結構
- 建議先自己規劃好(自己用草稿紙動手去畫,思路會更好的捋順清楚)
1.場景案例


- 考慮是誰在使用?
- 使用者的目的是什麼?
- 是希望進行監控?還是希望分析?
- 使用者怎麼使用?
- 怎麼改善BI?很多BI是有監控的,看使用人都幹什麼,使用那些報表,會使用後臺監控日誌去調整改善BI的佈局
2.指標結構案例

Dashbord是一個不斷迭代的設計過程,需要根據目的,不斷進化。
第五週:Mysql
遇到不會的內容,可以再進行查詢複習。
1.資料庫的概念
- Mysql是最流行的關係型資料庫管理系統
- 資料庫(Database)是按照資料結構來組織、儲存和管理資料的倉庫,
- RDBMS即關係資料庫管理系統(Relational Database Management System)的特點:
- 1.資料以表格的形式出現
- 2.每行為各種記錄名稱
- 3.每列為記錄名稱所對應的資料域
- 4.許多的行和列組成一張表單
- 5.若干的表單組成database
- 資料庫的基本型別:char–文字 int–整數 float–小數 date–日期 timestamp–秒或者毫秒
2.基本語法
- 以下是基本通用的select語法:
SELECT column_name,column_name
FROM table_name
[WHERE Clause]
[LIMIT N][ OFFSET M]- 1
- 2
- 3
- 4
select*form data.表名稱 *,為萬用字元,代表全部
limit 20,限制搜尋結果
order by,排序依據,可以設定多個依據。
where,對搜尋結果進行一次過濾。其中可使用各種邏輯判斷條件。模糊查詢“%京%”
跨表分析,需要利用子查詢。join可以用來跨表整合,join left常用

對於資料型別的改變,可以在select一行進行設定。
3.總結
- 對於SQL語法,可能是個人記性或者SQL太過生疏,2倍速度看過的視訊,回頭總結時語法都忘記了。
- 加上其他人的經驗,SQL應該是需要到實踐中去記憶與進步。
第六週:統計學
1.描述性統計學
- 分類資料的描述性統計:單純計數就可以
- 資料描述統計:
- 統計度量:平均數–資料分佈比較均勻的情況下進行,中位數,眾數,分位數(4分位、10分位、百分位)
- 圖形:
- 權重預估(分位數)
- 資料分佈(波動情況,標準差,方差)
- 資料標準化:

在實際用用的時候,有很多情況量綱不一致(即資料單位不一樣)導致差異很大無法進行比較
用資料標準化將資料進行一定範圍的壓縮,得到的結果與資料業務意義無關,純粹是資料上的波動達到可進行對比。
xi:資料的具體值
u:平均值
σ:標準差
標準化之後一般都是在0上下直接按波動的數字,就可以反應原始資料的典型特徵進行分析。
但是,標準化的辦法還需要根據實際資料型別確認,不同標準化辦法的實際標準化意義不同。
關於銷量等特徵與時間的關係,需要從多個時間維度去分析才能得到更多結論。如,週期、月份和年份。
- 切比雪夫定理是一個經驗定理,可以用來排除大部分異常值。資料量越大,精確度更高。

2.描述統計視覺化
1.箱線圖:描述一組資料的分佈情況。

Excel中能直接對資料進行作圖,並且還能新增許多對比條件。
2.直方圖:數值資料分佈的精確圖形表示

標準型:分佈均勻,出現在大多數場景下。
陡壁型:比較容易出現在收費領域
- 鋸齒型:說明資料不夠穩定
- 孤島型:要研究分析孤島產生的原因
- 偏峰型:銷售資料一般會產生偏鋒,一般會出現長尾(或左或右)
- 雙峰型:兩者資料混合一般會形成雙峰
直方圖引出另外一個概念:偏度,統計資料分佈偏斜方向和程度的度量
正態分佈:也稱“常態分佈”

以上公式成立是,有標準正態分佈。


可以用來進行異常值排查,或者假設的資料分佈。
3.概率推斷統計
統計推斷(statistical inference),指根據帶隨機性的觀測資料(樣本)以及問題的條件和假定(模型),而對未知事物作出的,以概率形式表述的推斷。

重要概念:貝葉斯定理

在知道結果A已經發生,想要推匯出各種原因發生的可能性情況。
貝葉斯分析的思路對於由證據的積累來推測一個事物發生的概率具有重大作用, 它告訴我們當我們要預測一個事物, 我們需要的是首先根據已有的經驗和知識推斷一個先驗概率, 然後在新證據不斷積累的情況下調整這個概率。整個通過積累證據來得到一個事件發生概率的過程我們稱為貝葉斯分析。
第七週:Python
1.Python基本功能
1.利用Python寫指令碼
2.excel視覺化有效能瓶頸,需要Python來實現。
3.Python安裝與資料分析相關如下
- Python的資料科學環境
- Python基礎
- Numpy和Pandas
- 資料視覺化
- 資料分析案例
- 資料分析平臺(輕量級BI)
2.Numpy和pandas
1.Python groupby
mysql不支援分組排序
2.concat和merge
concat是強行耦合
merge,是有共同名,優先表進行耦合
3.多重索引
4.文字函式

填充空值,None需要用np.nan,c語言形式的控制
pd.dropna()去除所有還有空值的行

5.Python pandas apply

6.聚合 apply

7。pandas資料透視


輸出結果
7.python連線資料庫
Pandas中讀取資料庫:
conn=pymysql.connect(
host='localhost',
user='root',
password='123456',
db='data_kejilie',
port=3306,
charset='utf8'
)
def reader(query,db):
sql=query
engine=create_engine('mysql+pymysql://root:[email protected]/{0}?charset=utf8').format(db))
df=pd.read_sql(sql,engine)
return df
reader
cur.execute('select * from article_link ')
data=cur.fetchall()
cur.close()
conn.commit()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3.資料視覺化
視覺化課程沒有進行記錄,詳情可以參照
中的視覺化程式碼展示。
4.案例實戰分析
利用課程提供的資料集,簡單分析練手了一下。
5.資料分析平臺
本次使用的是Python中的superset庫,基於web的資料分析平臺。
嚴重提示:安裝這個庫一定要新建一個虛擬環境後再進行pip安裝,不然會使得依賴庫和Anaconda中的部分庫衝突,使得原環境的庫無法正常呼叫
使用邏輯:
- 先載入資料庫或者資料檔案
- 寫好sql語法,進行一定編輯資料集。
- 在silces裡面對於資料集,進行一個個圖的繪畫與調整
- Dashboard裡進行最後圖表的匯合。

詳情安裝可以參考這篇文章:
總結
《七週成為資料分析師》課程終於學習完,整理、總結並且回顧了一遍,寫下這一篇文章。課程整體偏向整體性的介紹,對常用部分才做一個實現與技巧的具體講解,整體有輕有重,對於完成的新手來說還是比較不錯的課程進行入門瞭解與基礎學習。
前兩週的內容,個人認為是比較重要的,資料分析的思維在每一週的學習中都能有所體現。前面兩週,我是按照正常速度進行觀看,並且做一定筆記。但是,在到了Excel部分後發現視訊的節奏有些慢,自己的耐心也有了一些降低,後來自己嘗試將視訊播放速度調整至兩倍,對於學習的注意力集中起到了不錯的效果,推薦各位可以嘗試使用這種方法。
《七週成為資料分析師》這個課程從寒假2月份就決定要學,計劃3月5號即開學前完成,但是直到3-11開學後一週才徹底完成。對於計劃的執行情況不好,需要在以後學習中繼續調整規劃策略,端正態度。但是,最後還是把規劃完成了!還是給自己點個贊,哈哈。
寫成總結文章也是希望有需要的人能通過此得到些幫助,自己也能從中總結與整理知識。本文會發布在個人公眾號:資料路(shuju_lu),知乎:無小意丶,部落格:無小意。以後也會繼續在這些平臺上,輸出更多有價值的內容,歡迎討論與學習。

相關推薦
轉:《七週成為資料分析師》總結
百日計劃第一週總結 1. 計劃 1.徹底結束之前預定暑假完成的天善學院課程《七週資料分析師》 2.總結《七週資料分析師》。 2. 完成情況 1.完成《七週成為資料分析師》任務 2.周總結與《七週資料分析師》一起完成。 《七週資料分析師》總結 第一週:資料分析思維
如何七週成為資料分析師
寫這個系列,是希望在當初知乎某一個回答的基礎上,單獨完善出針對網際網路產品和運營們的教程。不論對資料分析或資料運營,我都希望它是一篇足夠好的教材。 得承認我有標題黨之嫌,更準確說,這是一份七週的網際網路資料分析能力養成提綱。 我會按照提綱針對性的增加網際網路側的內
最新七週成為資料分析師完整版分享
明星講師。資深資料分析師,資料化運營專家秦路老師,潛心磨劍打造精品課程; 規劃全面。涵蓋基礎、業務、思維、工具、方法等方方面面,提綱挈領,為資料分析師之路奠定堅實基礎; 循序漸進。環節緊湊,積跬步以至千里,七週為期,煥發不一樣的職業通道; 精品質量。教學方式活潑生動、易於
轉:七個受用一生的心理寓言
(一)成長的寓言:做一棵永遠成長的蘋果樹 一棵蘋果樹,終於結果了。 第一年,它結了10個蘋果,9個被拿走,自己得到 1個。對此,蘋果樹憤憤不平,於是自斷經脈,拒絕成長。第二年,它結了5個蘋果,4個被拿走,自己得到1個。“哈哈,去年我得到了10%,今年得到 20%
轉:關於C++ const 的全面總結
C++中的const關鍵字的用法非常靈活,而使用const將大大改善程式的健壯性,本人根據各方面查到的資料進行總結如下,期望對朋友們有所幫助。 Const 是C++中常用的型別修飾符,常型別是指使用型別修飾符const說明的型別,常型別的變數或物件的值是不能被更新的。 一、Const作用 如下表所
轉:用MapReduce進行資料密集型文字處理 – 本地聚合(上)
因為最近忙於Coursera提供 的一些課程,我已經有一段時間沒有寫部落格了。這些課程非常有意思,值得一看。我買了一本書《Data-Intensive Processing with MapReduce》,作者是Jimmy和Chris Dyer。書裡以偽碼形式總結了
《七週資料分析師》第七週:Python學習筆記
Python作用: 1.利用Python寫指令碼 2.excel視覺化有效能瓶頸,需要Python來實現。 第七週所有環節: Python的資料科學環境 Python基礎 Numpy和Pandas 資料視覺化 資料分析案例 資料分析平臺(輕量級BI)
轉: 【Java並發編程】之十七:深入Java內存模型—內存操作規則總結
tle 沒有 article 類型 javase 感知 執行引擎 要求 lock 轉載請註明出處:http://blog.csdn.net/ns_code/article/details/17377197 主內存與工作內存 Java內存模型的主要目標是定義程序中
20172302 《Java軟體結構與資料結構》第七週學習總結
2018年學習總結部落格總目錄:第一週 第二週 第三週 第四周 第五週 第六週 第七週 教材學習內容總結 第11章 二叉查詢樹 1.二叉查詢樹是一種含有附加屬性的二叉樹,該屬性即其左孩子小於父節點,而父節點又小於等於其右孩子。二叉查詢樹的一個示意圖: 在二叉查詢樹中: &nbs
20172323 2018-2019-1 《程式設計與資料結構》第七週學習總結
20172323 2018-2019-1 《程式設計與資料結構》第七週學習總結 教材學習內容總結 本週學習了第11章二叉查詢樹 11.1概述 二叉查詢樹的左孩子小於父結點,而父結點又小於或等於其右孩子 二叉查詢樹的定義是二叉樹定義的擴充套件
20172324 2018-2019-1 《程式設計與資料結構》第七週學習總結
20172324 2018-2019-1 《程式設計與資料結構》第七週學習總結 教材學習內容總結 概述 二叉查詢樹是一種含有附加屬性的二叉樹,即其左孩子小於父節點,而父節點又小於等於其右孩子。 它是特殊的二叉樹:對於二叉樹,假設x為二叉樹中的任意一個結點,x節點包含關鍵字key,節點x的key值記
20172308 《程式設計與資料結構》第七週學習總結
教材學習內容總結 第 十一 章 二叉查詢樹 一、概述 二叉查詢樹是一種含有附加屬性的二叉樹,即其左孩子小於父結點,父結點小於或等於右孩子 (二叉查詢樹的定義是二叉樹定義的擴充套件) 二、 用連結串列實現二叉查詢樹 addElement操作: addElement方法根據給定元素的值,在樹中的恰當位
20172314 2018-2019-1《程式設計與資料結構》第七週學習總結
教材學習內容總結 概述 二叉查詢樹:是含附加屬性的二叉樹,即其左孩子小於父節點,而父節點又小於或等於右孩子。 二叉查詢樹的定義是二叉樹定義的擴充套件。 二叉查詢樹的各種操作 用連結串列實現二叉查詢樹 每個BinaryTreeNode物件要維護一個指向結點所儲存元素的引用,另外
20172315 2018-2019-2 《程式設計與資料結構》第七週學習總結
20172315 2018-2019-2 《程式設計與資料結構》第七週學習總結 教材學習內容總結 二又查詢樹是一種含有附加屬性的二又樹,即其左孩子小於父結點,而父結點又小於或等於右孩子。 每個BinaryTreeNode物件要維護一個指向結點所儲存元素的引用,另外還要維護指向結點的每個孩子
20172319 《程式設計與資料結構》 第七週學習總結
20172319 2018.10.27-11.02 《程式設計與資料結構》第7周學習總結 目錄 教材學習內容總結 教材學習中的問題和解決過程 程式碼除錯中的問題和解決過程 程式碼託管 上週考試錯題總結 結對及互評 學習進度條
2018-2019-20172329 《Java軟體結構與資料結構》第七週學習總結
2018-2019-20172329 《Java軟體結構與資料結構》第七週學習總結 教材學習內容總結 《Java軟體結構與資料結構》第十一章-二叉查詢樹 一、概述 1、什麼是二叉查詢樹:二叉查詢樹是一種帶有附加屬性的二叉樹,即對樹中的每個結點,其左孩子都要小於其父結點,而父結點又小於或等於其右孩
20172311《程式設計與資料結構》第七週學習總結
20172311《程式設計與資料結構》第七週學習總結 教材學習內容總結 第十一章 二叉查詢樹 樹是一種非線性結構,其中的元素被組織成一個層次結構 含有m個元素的平衡n元樹具有的高度為lognm 樹的陣列實現之計算策略: 如果我們儲存的樹不是完全的或者只是相對完全的,則該陣列
20172322 《程式設計與資料結構》第七週學習總結
20172322 《程式設計與資料結構》第七週學習總結 教材學習內容總結 本章的內容主要講二叉查詢樹,二叉查詢樹是對於二叉樹的一種拓展,這意味著上一章中對於二叉樹的操作對於二叉查詢樹同樣適用,同時它也是一種帶有附加屬性的二叉樹。這種附加屬性即:對樹中的每個結點,它的左孩子都要小於其父結點,而父結點又小於或
20172306 2018-2019-2 《Java程式設計與資料結構》第七週學習總結
20172306 2018-2019-2 《Java程式設計與資料結構》第七週學習總結 教材學習內容總結 概述 二叉查詢樹是一種含有附加屬性的二叉樹,即其左孩子小於父結點,而父結點又小於或等於右孩子。 二叉查詢樹的定義是二叉樹定義的擴充套件。 二叉查詢樹的各種操作:a