
【模式識別】感知器 Perceptron
基本概念
線性可分:在特徵空間中可以用一個線性分介面正確無誤地分開兩 類樣本;採用增廣樣本向量,即存 在合適的增廣權向量 a 使得:

則稱樣本是線性可分的。如下圖中左圖線性可分,右圖不可分。所有滿足條件的權向量稱為解向量。權值空間中所有解向量組成的區域稱為解區。

通常對解區限制:引入餘量b,要求解向量滿足:
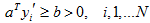
使解更可靠(推廣性更強),防止優化演算法收斂到解區的邊界。
感知準則函式及求解
對於權向量a,如果某個樣本yk被錯誤分類,則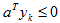
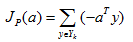
其中Yk是被a錯分的樣本集合。當且僅當JP(a*) = min JP(a) = 0 時,a*是解向量。這就是Rosenblatt提出的感知器(Perceptron)準則函式
感知器準則函式的最小化可以使用梯度下降迭代演算法求解:
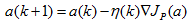
其中,k為迭代次數,η為調整的步長。即下一次迭代的權向量是把當前時刻的權向量向目標函式的負梯度方向調整一個修正量。
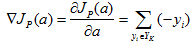
因此,迭代修正的公式為:
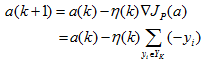
即在每一步迭代時把錯分的樣本按照某個係數疊加到權向量上。
通常情況,一次將所有錯誤樣本進行修正不是效率最高的做法,更常用是每次只修正一個樣本或一批樣本的固定增量法:


收斂性討論:可以證明,對於線性可分的樣本集,採用這種梯度下降的迭代演算法:
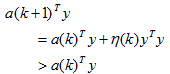
經過有限次修正後一定會收斂到一個解向量。
理論結論:只要訓練樣本集是線性可分的,對於任意的初值 a(1) ,經過有限次疊代,演算法必定收斂。
感知器是最簡單可以“學習”的機器,可以解決線性可分的問題。當樣本線性不可分時,感知器演算法不會收斂。實際應用中直接使用感知器的場合並不多,但他是很多複雜演算法的基礎。
相關推薦
【模式識別】感知器 Perceptron
基本概念線性可分:在特徵空間中可以用一個線性分介面正確無誤地分開兩 類樣本;採用增廣樣本向量,即存 在合適的增廣權向量 a 使得:則稱樣本是線性可分的。如下圖中左圖線性可分,右圖不可分。所有滿足條件的權向量稱為解向量。權值空間中所有解向量組成的區域稱為解區。通常對解區限制:引
【Python-ML】感知器學習演算法(perceptron)
1、數學模型 2、權值訓練 3、Python程式碼 感知器收斂的前提是兩個類別必須是線性可分的,且學習速率足夠小。如果兩個類別無法通過一個線性決策邊界進行劃分,要為模型在訓練集上的學習迭代次數設定一個最大值,或者設定一個允許錯誤分類樣本數量的閾值,否則感知器
【模式識別】SVM核函式
以下是幾種常用的核函式表示:線性核(Linear Kernel)多項式核(Polynomial Kernel)徑向基核函式(Radial Basis Function)也叫高斯核(Gaussian Kernel),因為可以看成如下核函式的領一個種形式:徑向基函式是指取值僅僅依
【模式識別】Fisher線性判別
Fisher是一種將高維空間對映到低維空間降維後進行分類的方法 1.投影: 對xn→的分量作線性組合可得標量 yn=w⃗ Txn→ 什麼樣的對映方法是好的,我們需要設計一個定量的標準去找w⃗ 來
【模式識別】Boosting
Boosting簡介分類中通常使用將多個弱分類器組合成強分類器進行分類的方法,統稱為整合分類方法(Ensemble Method)。比較簡單的如在Boosting之前出現Bagging的方法,首先從從整體樣本集合中抽樣採取不同的訓練集訓練弱分類器,然後使用多個弱分類器進行vo
【模式識別】模式識別的概述(一)
本節主要內容: 模式和模式識別的概念模式識別的發展簡史和應用模式識別的主要方法模式識別的系統和例項幾個相關的數學概念1、模式和模式識別的概念 什麼是模式(Pattern)? 廣義地說,存在於時間和空間中可觀察的事物,如果我們可以區別他們是否相同或是否相似,都可以稱之為
【模式識別】K-近鄰分類演算法KNN
K-近鄰(K-Nearest Neighbors, KNN)是一種很好理解的分類演算法,簡單說來就是從訓練樣本中找出K個與其最相近的樣本,然後看這K個樣本中哪個類別的樣本多,則待判定的值(或說抽樣)就屬於這個類別。KNN演算法的步驟計算已知類別資料集中每個點與當前點的距離;選
【模式識別】MPL,MIL和MCL
Multi-Instance Learning (MIL) 和Multi-Pose Learning (MPL)是CV的大牛Boris Babenko at UC San Diego提出來的,其思想可以用下面一幅圖概況。MIL是指一個物件的學習例項可能有很多種情況,學習的時候
模式識別:感知器的實現
在之前的模式識別研究中,判別函式J(.)的引數是已知的,即假設概率密度函式的引數形式已知。本節不考慮概率密度函式的確切形式,使用非引數化的方法來求解判別函式。由於線性判別函式具有許多優良的特性,因此這裡
【模式識別與機器學習】——判別式和產生式模型
(1)判別式模型(Discriminative Model)是直接對條件概率p(y|x;θ)建模。常見的判別式模型有線性迴歸模型、線性判別分析、支援向量機SVM、神經網路、boosting、條件隨機場等。 舉例:要確定一個羊是山羊還是綿羊,用判別模型的方法是從歷史資料中學習到模型,然後通過提取這隻羊的特
【模式識別與機器學習】——3.9勢函式法:一種確定性的非線性分類方法
目的 用勢函式的概念來確定判別函式和劃分類別介面。 基本思想 假設要劃分屬於兩種類別ω1和ω2的模式樣本,這些樣本可看成是分佈在n維模式空間中的點xk。 把屬於ω1的點比擬為某種能源點,在點上,電位達到峰值。 隨著與該點距離的增大,電位分佈迅速減小,即把樣本xk附近空間x點上的電位分佈,看
【模式識別與機器學習】——PCA主成分分析
基本思想 其基本思想就是設法提取資料的主成分(或者說是主要資訊),然後摒棄冗餘資訊(或次要資訊),從而達到壓縮的目的。本文將從更深的層次上討論PCA的原理,以及Kernel化的PCA。 引子 首先我們來考察一下,這裡的資訊冗餘是如何體現的。如下圖所示,我們有一組二維資料點,從圖上不難發現
【模式識別與機器學習】——PCA與Kernel PCA介紹與對比
PCA與Kernel PCA介紹與對比 1. 理論介紹 PCA:是常用的提取資料的手段,其功能為提取主成分(主要資訊),摒棄冗餘資訊(次要資訊),從而得到壓縮後的資料,實現維度的下降。其設想通過投影矩陣將高維資訊轉換到另一個座標系下,並通過平移將資料均值變為零。PCA認為,在變換過後的
【模式識別與機器學習】——最大似然估計 (MLE) 最大後驗概率(MAP)
1) 極/最大似然估計 MLE 給定一堆資料,假如我們知道它是從某一種分佈中隨機取出來的,可是我們並不知道這個分佈具體的參,即“模型已定,引數未知”。例如,我們知道這個分佈是正態分佈,但是不知道均值和方差;或者是二項分佈,但是不知道均值。 最大似然估計(MLE,Maximum Likelihood Esti
基於開源專案OpenCV的人臉識別Demo版整理(不僅可以識別人臉,還可以識別眼睛鼻子嘴等)【模式識別中的翹楚】
最近對人臉識別的程式非常感興趣,但是苦於沒有選修多媒體方向,看了幾篇關於人臉識別的論文,大概也沒看懂多少,什麼灰度處理啊,切割識別啊,雲裡霧裡,傻傻看不明白啊。各種苦惱。 於是就在網上找找,看有木有神馬開原始碼啊,要是有個現成的原始碼就更好了,百度it ,那些原始碼都憂傷的躲在CSDN中,老衲還
【國內動態】服務器列表
淮南 重慶 鹹寧 湖南長沙 廣東 深圳 江蘇 佛山 河北 北京聯通:bjlt01.adslip.cc北京聯通:bjlt02.adslip.cc 上海電信:sh01.adslip.cc上海電信:sh02.adslip.cc 廣州電信:gz01.adslip.cc廣東陽江電信:
【全國動態】服務器列表
服務器 牡丹江 西安 昆明 陜西 安徽 鹹寧 河北 浙江 北京聯通:297.9966.org北京市聯通:044.9966.org北京市聯通:046.9966.org北京市聯通:217.9966.org北京市聯通:224.9966.org北京市聯通:266.9966.org北
PHP PC端微信掃碼支付【模式二】詳細教程-附帶源碼(轉)
idt class pid 方法 按鈕 -c 商戶 開源 玩意兒 博主寫這破玩意兒的時候花了大概快兩天時間才整體的弄懂邏輯,考慮了一下~還是把所有代碼都放出來給大家~抱著開源大無私的精神!誰叫我擅長拍黃片呢?同時也感謝我剛入行時候那些無私幫過我的程序員們! 首先還是
【高速動態】服務器列表
珠海 寧夏 浙江湖州 江西 保定 山東 電信 lns 廣西 北京北京北京聯通bj3.niumoip.com 天津天津天津電信tj1.niumoip.com 河北河北邢臺聯通hbxt.niumoip.com河北保定電信hbbd.niumoip.com 遼寧遼寧撫順電信lnfs
【工程實踐】服務器數據解析
something 時間比較 數據訪問 shu 成員 字段值 ear 計時 日誌 本文來自網易雲社區作者:孫建順在客戶端開發過程中一個重點內容就是解析服務器數據,關於這個話題也許大家首先會去思考的問題是用哪個json解析庫。是的,目前通過json格式進行數據傳輸是主流的方式