
【模式識別】MPL,MIL和MCL
Multi-Instance Learning (MIL) 和Multi-Pose Learning (MPL)是CV的大牛Boris Babenko at UC San Diego提出來的,其思想可以用下面一幅圖概況。MIL是指一個物件的學習例項可能有很多種情況,學習的時候不是用一個精確的標註物件來學習,而是用一個物件的多個例項組成的“包”來學習;而MPL是指一個物件會有多個姿態(Pose),學習的時候用一個分類器常常難以達到很好的效果,所以可以訓練多個分類器來分別學習不同的Pose。其描述的都是對一個物件多種情況的同時學習和對齊的策略,也就是MIL是“adjusting training samples so they lie in correspondence”,而MPL是“separating the data into coherent groups and training separate classifiers for each”。
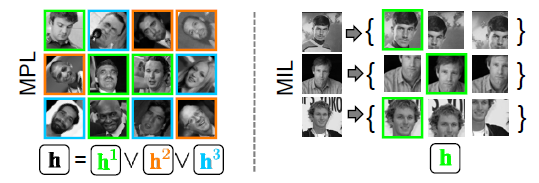
上圖中右邊為MIL的學習情況,每一行為一個物件的學習資料;左邊為MPL的學習情況,每行為一個物件的不同pose學習資料,而每種顏色的框為訓練的一個class。MIL被提出以後應用很廣,而貌似MPL只有為數不多的引用,一篇《Multi-Cue Onboard Pedestrian Detection》應用的MPL但也沒有具體的公式。MPL與傳統的Boost方法的不同就是使用如下組合的y代替傳統的y,其中k表示多個class,也就是有一個class識別為1,則判斷結果為1。
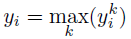
其迭代訓練的步驟也是大致相同,除了複雜度上多一個層每個yk的訓練,另外相應的更新公式也不同:

之後劍橋提出Multi-Class Learning (MCL),也是訓練多個class,除了不是用的max(yk)而是用的諸如下面:
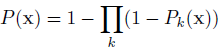
Noisy-OR的概率模型,整體思想感覺和MPL是一樣的。但MCL的迭代更新方法寫的要明朗許多,其權重wki(k表示每個class,i表示樣本)更新使用如下方法:
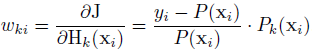
注意P二類模型中常用的-1~1,而是0~1,所以當某個class判斷為一定不是此類的時候,此樣本在下一次的訓練中就會被去掉,而相應的判斷為是的class中權重加大。而在具體的某一類k的class中,判斷錯誤的樣本權重會相應加大,這點又契合了傳統的Boost訓練方法。MCL的文章是用在資料分類上邊:
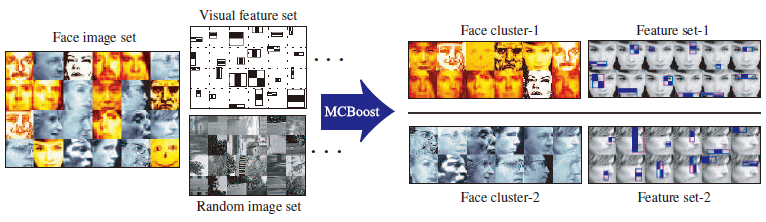
效果看上去很美味~
參考文獻:
[1] Boris Babenko, Piotr Doll´ar, Zhuowen Tu, Serge Belongie. Simultaneous Learning and Alignment: Multi-Instance and Multi-Pose Learning.
[2] Christian Wojek, Stefan Walk, Bernt Schiele. Multi-Cue Onboard Pedestrian Detection
[3] Tae-Kyun Kim, Roberto Cipolla. MCBoost: Multiple Classifier Boosting for Perceptual Co-clustering of Images and Visual Features