
《機器學習實戰》支援向量機的數學理解及程式實現
一、 引言
最近在機器學習課上,學到的《機器學習實戰》第六章的支援向量機,這部分內容非常多,不僅要會程式設計和測試,還要理解它的數學基礎,這裡對這部分的學習進行一些總結。
二、 SVM的數學原理
從一個簡單的二分問題開始說吧:
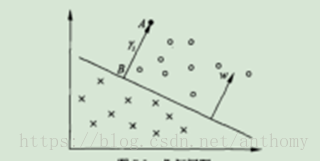
我們要把這兩類不同的點區分開,那麼在這個二維平面上就是找條直線,儘量使得這些點更好的分隔開,那麼這條直線可以表示為AX+BY+C=0.
在資料集中自然是多種屬性的,這時候就可以看成是n維空間,這個時候要區分這些資料,我們的目標是需要找到一個n-1維的超平面,這個超平面可以將資料分成兩類,, 可以表示為W1X1+W2X2+…+WnXn+b=0(等價於 
還是以二維平面為例,假設距離區分直線的兩條直線分別為d1和d2,支援向量機找最優權值的策略即使,先到最邊上的點,再找到這兩個距離之和D=d1+d2,然後求解D的最大值.
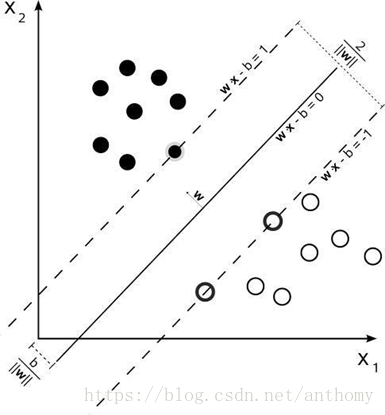
分介面
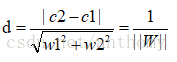
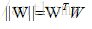
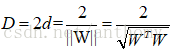
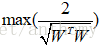
為了方便後續的計算,我們可以引入其對偶問題,這樣優化問題變成了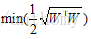


分介面以上的點有

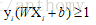
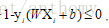


所以最終的優化問題變成了 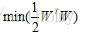
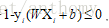
而上下邊界上的點就是支援向量,這些點很關鍵,這也是”支援向量機“命名的由來。
概括來說SVM的核心思想就是找到不同類別之間的分介面,使得兩類樣本儘量落在面的兩邊,而且離分介面儘量遠。
這裡再介紹一下KKT條件和拉格朗日乘子法。
通常情況下我們要求解的最優化問題可以分為三類情況:
<1>無約束的優化問題
Min(f(x))或Max(f(x))
<2>有等式約束的優化問題
Min(f(x))或Max(f(x))

<3>有不等式約束的優化問題
Min(f(x))或Max(f(x))
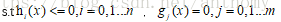
對於第一類問題的求解,在高數上我們已經學習過,就是先求f(x)的導數,然後令其為零,可以求得候選最優值,再在這些值中進行驗證,如果是凸函式,就可以保證最優解。
對於第二類問題,一般使用的是拉格朗日乘子法,就是把目標函式和約束條件乘以一個係數寫成一個式子,這個式子稱為拉格朗日函式,係數稱為拉格朗日乘子。即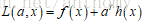
再通過拉格朗日函式對各個變數Xi 求偏導,令其為零,求得候選值得集合,再通過驗證得到最優值。
對於第三類優化問題,一般使用的方法KKT條件,同樣地,我們把所有的等式、不等式約束與f(x)寫為一個式子,也叫拉格朗日函式,係數也稱拉格朗日乘子,即

通過一些條件,可以求出最優值的必要條件,這個條件稱為KKT條件。
這些條件表示為:
<1>L(a,b,x)對x求導為零;
<2>g(x)=0;
<3>
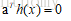
因為約束條件h(x)<=0,如果要滿足這個等式,必須有a=0或者h(x)=0,這個是SVM很多性質的來源,如支援向量的概念。
再回到我們上面提到的SVM分類器,從我們分析的結果

1. 求一個最優化問題

2. 存在不等式約束

3. 目標函式是凸函式
這個也是滿足的。
所以引入拉格朗日乘子法,優化的目標改變為:
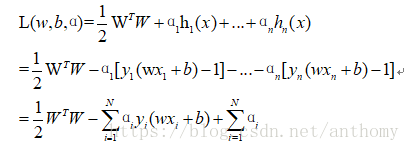
接下來求偏導,令其等於零:

這時候再帶回L中,把w和b消掉

求解最開始的函式的最小值等價到現在就是求解W的最大值。現在的問題變成了:

其中
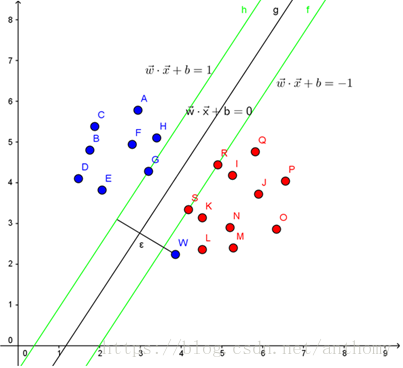
我們可以發現點w是一個異常點,,這在資料中是非常常見的,屬性上與其附近的點很相近,但標籤卻截然不同,為了解決這個這個問題,我們引入了鬆弛變數
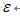
修改之後的約束條件為 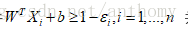

運用拉格朗日乘子法之後的公式就變成了:

我們在優化的時候,儘可能使得鬆弛變數之和最小,常數C是決定鬆弛變數之和對優化問題的影響程度,越大表明影響越嚴重,C是一個大於零的值。
現在把所有問題綜合起來:
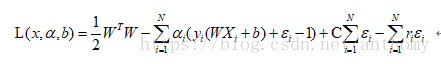
然後對 w,b,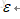
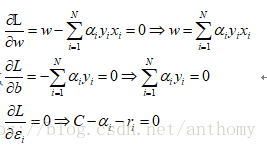
因為 

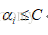


將上述條件代入目標函式中消掉w,b,r,最終得到:
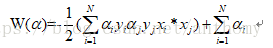
發現 也一起消掉了,並且目標函式也變成了沒加鬆弛變數之前的一樣,但是相比之前添加了新的條件

最終的優化問題就變成了

接下來就是要去找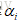
這裡就用的到SMO演算法了。
1996年,John Platt釋出了一個稱為SMO的強大演算法,用於訓練SVM。SMO表示序列最小優化(Sequential Minimal Optimization)。SMO是將大優化問題分解為多個小優化問題來求解,小優化問題一般很容易求解,並且對他們進行順序求解的結果與將他們作為整體來求得結果是完全一樣的,而且這樣求解的時間會短很多。
SMO方法:
概要:SMO方法的中心思想是每次取一對αi和αj,調整這兩個值。增大其中一個,同時減小另外一個, αi和αj是具有一定函式關係的,所以說只有一個引數而已,得到了這些 ,就很容易計算出權重向量w了,並得到相應的超平面。
演算法過程:
1.初始化α為0;
2.在每次迭代中(小於等於最大迭代數),找到第一個不滿足KKT條件的訓練資料,對應的αi,在其它不滿足KKT條件的訓練資料中,找到誤差最大的x,對應的index的αj,αi和αj組成了一對,根據約束條件調αi, αj。
不滿足KKT條件的公式

演算法過程的數學表達:

最後來提一下核函式的概念。
再回到我們上面提到構造,都是基於資料完全線性可分,支援向量機(SVM)是一個二分類器,是一個線性的分類器
我們在之前所述是線上性問題的基礎上構造的,那如果是非線性問題呢,比如說之前提到的分界線,如果變成是一個曲線呢,怎麼得到這個曲線方程呢,在多維空間中就很更麻煩。但是數學家們提供瞭解決方法,非線性問題對映到高緯度後,會變成一個線性問題了。
比如:二維下的一個點<x1,x2><x1,x2>, 可以對映到一個5維空間,這個空間的5個維度分別是:x1,x2,x1x2,x12,x22x1,x2,x1x2,x12,x22。
對映到高維度,有兩個問題:一個是如何對映?另外一個問題是計算變得更復雜了。
我們可以使用核函式(Kernel function)來解決這個問題
從上述演算法過程的數學表達我們不難看出,關於向量X的計算,總是在計算兩個向量的內積K(x1,x2)= <x1,x2>,所以在高緯空間裡,公式的變化只有計算低維空間下的內積<x1,x2>變成了計算高緯空間下的內積<x1’,x2’>,核函式提供的方法就是通過原始空間的向量值計算高緯空間的內積,而不去管這個對映的方式。
核函式有很多種,一般使用的是高斯核(徑向基函式(radial basisfunction))

可以通過調節σ來匹配維度的大小,σ越大,維度越低。
三、 程式除錯
1.開啟testSet.txt檔案,得到每行的類標籤和整個資料矩陣,類標籤中的-1改用0代替,為了方便後續的處理

2.簡化版的SMO
虛擬碼大致如下:(不同層次的迴圈用顏色匹配)
建立一個alpha向量並將其初始化為0向量,當迭代次數小於最大迭代次數(外迴圈),對資料集中每個資料向量(內迴圈),
如果該資料向量可以被優化:隨機選擇另外一個數據向量,同時優化這個向量
如果兩個向量都不能被優化,退出內迴圈
如果所有向量都未被優化,增加迭代數,進入下次迴圈。
2.1 、檢查alpha[j]是否改變,退出for迴圈,alpha[i]和alpha[j]進行同樣大小的改變,一個增加,一個減小,進行優化之後設定常數項b.

2.2、觀察alpha矩陣,去除掉其中的零元素
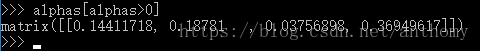
2.3、檢視那些資料點是支援向量,非零的alpha值是支援向量

簡化版SMO對於小規模資料集可用,但對於大規模資料,執行速度會變慢。
完整的SMO演算法通過一個外迴圈來選擇alpha值,選擇過程在兩種方式之間交替:
1-在所有資料集上進行單遍掃描; 2-在非邊界(不等於邊界0/C的值)alpha中實現單遍掃描。實現非邊界值的掃描時,需要建立alpha列表,然後對錶進行遍歷,跳過那些已知不會改變的alpha值。
選擇第一個alpha後,通過內迴圈來選擇第二個alpha,優化過程中選擇最大步長的方式獲取第二個alpha。
完整的Platt SMO演算法包括以下三個部分,對應的程式大家可以到《機器學習實戰》第六章找到。
<1>用於清理程式碼的資料結構和3個用對E快取的輔助函式。
<2>優化過程:(選擇第二個alpha)與之前簡化版SMO差別不大,不過添加了自己的資料結構,在oS中傳遞,使用selectJ代替selectJrand來選擇則第二個alpha,alpha改變時更新Ecache值
<3>外迴圈(包含了kernel函式-高斯核)
經過迭代得到權值W。

3.對資料進行分類的驗證(對第一個資料點分類,得到的值如果大於零,則屬於1類,如果小於零則屬於-1類,並通過命令得到其原始的標籤驗證分類結果的正確性)再對第二個、第三個資料點進行驗證。

4.觀察k1=1.3測試錯誤率,訓練錯誤率,支援向量個數。

5.手寫識別問題
流程
(1)收集資料:提供原始資料的文字檔案
(2)準備資料:基於手寫二值影象構造向量
(3)分析資料:對影象向量進行目測
(4)訓練演算法:採用兩種不同的核函式,並對徑向基核函式採用不同設定來執行SMO演算法
(5)測試演算法:編寫測試函式來測試不同核函式並計算error rate
匯入資料進行測試:kTup=('rbf', 10)

有50個支援向量,測試資料錯誤率為1.6%
四、總結
演算法的實現來源於數學,數學是一個非常強大的工具,深刻了解到數學上的邏輯性,會幫助我們理解程式每一個步驟,在程式設計時更加的有效率。
這次只是實現了一些對簡單問題的分類,接下來有時間的話,想去尋找一些有意思的一些資料集,希望在上面運用支援向量機的方法,再對比一些其他的分類方法,看看支援向量機的優勢與不足。
非常感謝閱讀!如有不足之處,請留下您的評價和問題。
參考文獻
【1】 深入理解拉格朗日乘子法(LagrangeMultiplier) 和KKT條件
【2】 解密SVM系列(三):SMO演算法原理與實戰求解
【3】 機器學習實戰 - 讀書筆記(06) – SVM支援向量機
https://www.cnblogs.com/steven-yang/p/5658362.html
【4】 《機器學習實戰》-PeterHarrington
【5】 《統計學習方法》-李航
相關推薦
【機器學習】支援向量機SVM原理及推導
參考:http://blog.csdn.net/ajianyingxiaoqinghan/article/details/72897399 部分圖片來自於上面部落格。 0 由來 在二分類問題中,我們可以計算資料代入模型後得到的結果,如果這個結果有明顯的區別,
《機器學習實戰》支援向量機的數學理解及程式實現
一、 引言最近在機器學習課上,學到的《機器學習實戰》第六章的支援向量機,這部分內容非常多,不僅要會程式設計和測試,還要理解它的數學基礎,這裡對這部分的學習進行一些總結。二、 SVM的數學原理從一個簡單的二分問題開始說吧:我們要把這兩類不同的點區分開,那麼在這個二維平面上就是找
機器學習14-支援向量機大邊界的數學原理
在本篇博文中,我將介紹一些大邊界分類背後的數學原理。你將對支援向量機中的優化問題,以及如何得到大邊界分類器,產生更好的直觀理解。 首先,讓我來給大家複習一下關於向量內積的知識。假設我有兩個向量,u 和 v 我將它們寫在這裡。兩個都是二維向量,我們看一下,
[機器學習]svm支援向量機介紹
1 什麼是支援向量機 支援向量機是一種分類器,之所以稱為 機 是因為它會產生一個二值決策結果,即它是一個決策機。 Support Vector Machine, 一個普通的SVM就是一條直線罷了,用來完美劃分linearly separable的兩類。但這又不是一條
機器學習之支援向量機(四)
引言: SVM是一種常見的分類器,在很長一段時間起到了統治地位。而目前來講SVM依然是一種非常好用的分類器,在處理少量資料的時候有非常出色的表現。SVM是一個非常常見的分類器,在真正瞭解他的原理之前我們多多少少都有接觸過他。本文將會詳細的介紹SVM的原理、目標以及計算過程和演算法步驟。我們針對線性可分資
機器學習筆記——支援向量機
一,線性可分支援向量機與硬間隔最大化 1.1 間隔與支援向量 在樣本空間中,劃分超平面可通過如下線性方程來描述: 其中,w = (w1;w2;...;wd)為法向量,決定了超平面的方向;b為位移項,決定了超平面與原點之間的距離。 我們將超平面記為(w,b).樣本空間中任意點x到
[四]機器學習之支援向量機SVM
4.1 實驗資料 本資料集來源於UCI的Adult資料集,並對其進行處理得到的。資料集下載地址:http://archive.ics.uci.edu/ml/datasets/Adult。本實驗使用LIBSVM包對該資料進行分類。 原始資料集每條資料有14個特徵,分別為age,workc
機器學習5---支援向量機
1. 線性可分的支援向量機 1.1 支援向量機(SVM)基本型 對於給定的在樣本空間中線性可分的訓練集,我們有多重辦法對其進行劃分,以二分類問題為例,如圖: 紅線和黑線(超平面)都能將兩類樣本很好的劃分開,但是當新樣本進入時,黑線比紅線更加有可能正確劃分新的樣本,換句話說:越位
機器學習 --- 線性支援向量機
支援向量機是一種二分類模型,目的是尋找一個超平面對樣本進行劃分,其基本模型定義為特徵空間上的間隔最大的線性分類器。 一、線性支援向量機的直觀理解 給定訓練樣本集 , ,模型旨在能基於訓練集在樣本空間中找到一個合適的劃分超平面。 在下圖
機器學習演算法——支援向量機svm,實現過程
初學使用python語言來實現支援向量機演算法對資料進行處理的全過程。 from sklearn.datasets import load_iris #匯入資料集模組 from sklearn.model_selection import train_test_spli
機器學習---演算法---支援向量機---線性SVM--第一部分
轉自:https://cuijiahua.com/blog/2017/11/ml_8_svm_1.html 什麼是SVM? SVM的英文全稱是Support Vector Machines,我們叫它支援向量機。支援向量機是我們用於分類的一種演算法。讓我們以一個小故事的形式,開啟我們的SVM之旅吧。 在很
吳恩達機器學習13--支援向量機(Support Vector Machines)
第13章 支援向量機(Support Vector Machines) 一,優化目標(Optimization objective) SVM也是廣泛的應用於工業界和學術界的監督學習演算法。 類似於logistic的代價函式,SVM的代價函式如圖是斜直線加上平直線
機器學習之支援向量機(Support Vector Machines)
支援向量機(Support Vector Machines, SVM)是一種二分類模型,其基本模型是定義在特徵空間上的間隔最大的線性分類器。支援向量機的學習策略就是間隔最大化。 間隔最大化的直觀解釋是:對訓練資料集找到幾何間隔最大的超平面意味著以充分大的卻確信度對訓練資料進
機器學習4-支援向量機
目錄 支援向量機(SVM) 原理 引數 不同核函式的分類效果 線性核函式:linear 多項式核函式:poly 徑向基核函式:rbf 樣本類別均衡化 置信概率 網格
人工智障學習筆記——機器學習(4)支援向量機
一.概念 支援向量機(Support Vector Machine),簡稱SVM。是常見的一種判別方法。在機器學習領域,是一個有監督的學習模型,通常用來進行模式識別、分類以及迴歸分析。 SVM的主要思想可以概括為兩點: 1.它是針對線性可分情況進行分析,對於線性不可分的情況
機器學習:支援向量機SVM和人工神經網路ANN的比較
在統計學習理論中發展起來的支援向量機(Support Vector Machines, SVM)方法是一種新的通用學習方法,表現出理論和實踐上的優勢。SVM在非線性分類、函式逼近、模式識別等應用中有非常好的推廣能力,擺脫了長期以來形成的從生物仿生學的角度構建學習機器的束縛。
機器學習筆記——支援向量機(SVM)
支援向量機 除了之前講的機器學習的方法,還有一種常用的方法叫做支援向量機。我們將logistic迴歸的假設函式以及代價函式稍加更改就可以得到支援向量機的模型 另外還有不同的是SVM的輸出並不是一個概率值,而是0或1 大間隔 我們說SVM是一種大間隔演算法,意思是我們
機器學習:支援向量機(SVM)
1. 理論 概述: 利用訓練集在特徵空間中求出一個分類超平面(w,b)把樣本切割開,依靠該超平面對新樣本進行分類。如果訓練集在當前的特徵空間中無法分割,則用核技術的對映函式把原特徵空間對映到高緯或
機器學習之支援向量機SVM Support Vector Machine (五) scikit-learn演算法庫
一、scikit-learn SVM演算法庫概述 scikit-learn中SVM的演算法庫分為兩類,一類是分類演算法庫,包括SVC、 NuSVC和LinearSVC三個類。另一類是迴歸演算法庫,包括SVR、NuSVR和LinearSVR三個類。相關的
機器學習模型-支援向量機(SVM)
Machine Learning - SVC 一.基本原理 二.程式碼實現 import numpy as np from sklearn import datasets from sklearn.model_selection import train_test_spli