
Torch7深度學習教程(七)
這一章主要分享預測的基本操作,並且先將前面分享的內容總結下,完整地實現CNN影象分類的例項
require 'paths';
require 'nn';
---Load TrainSet
paths.filep("/home/ubuntu64/cifar10torchsmall.zip");
trainset = torch.load('cifar10-train.t7');
testset = torch.load('cifar10-train.t7');
classes = {'airplane', 'automobile', 'bird', 'cat',
'deer' 資料的預處理
net = nn.Sequential()
--change 1 channel to 3 channels
--net:add(nn.SpatialConvolution(1, 6, 5, 5))
net:add(nn.SpatialConvolution(3, 6, 5, 5))
net:add(nn.ReLU())
net:add(nn.SpatialMaxPooling(2,2,2,2))
net:add(nn.SpatialConvolution(6, 16, 5, 5))
net:add(nn.ReLU())
net:add(nn.SpatialMaxPooling(2,2,2,2))
net:add(nn.View(16*5*5))
net:add(nn.Linear(16*5*5, 120))
net:add(nn.ReLU())
net:add(nn.Linear(120, 84))
net:add(nn.ReLU())
net:add(nn.Linear(84, 10))
net:add(nn.LogSoftMax())
與之前建立好的網路有一點不同是將原來的1通道變為3通道,輸入的資料集是3通道的彩色影象
criterion = nn.ClassNLLCriterion();
trainer = nn.StochasticGradient(net, criterion)
trainer.learningRate = 0.001
trainer.maxIteration = 5
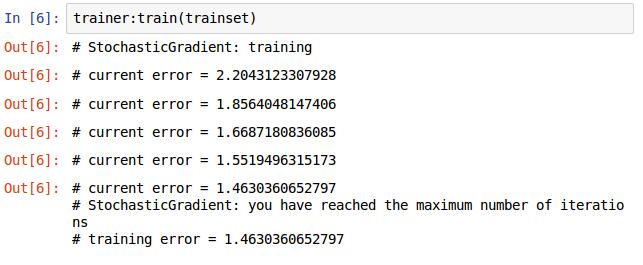
trainer:train(trainset)訓練的過程與前面一樣,再重複下,加深印象。
定義損失函式,選擇優化的方法,將網路和損失函式傳入,設定學習率和最大迭代次數,開始訓練,結果如下圖。
現在我們的CNN網路已經訓練完了,迭代次數可以多一些,效果不一樣,讓我測試下看看效果如何。

將測試的影象資料用先前的平均值和方差進行同訓練集一樣的中心化和歸一化。
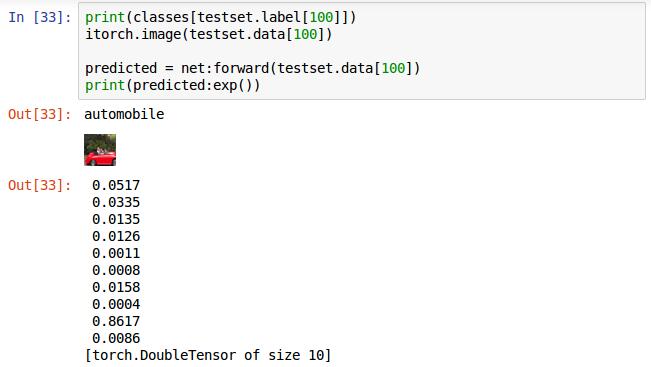
選取第100張圖片輸入,前兩行分別為列印其對應的標籤和顯示圖片,第三行,執行網路的前向傳播演算法,返回值賦值給predicted。直接列印predicted給出的不是概率而是對數概率。在這十個概率中值最大的為識別的結果,這個是倒數第二個值最大,對應label標籤為9,即這張圖片被識別成了ship
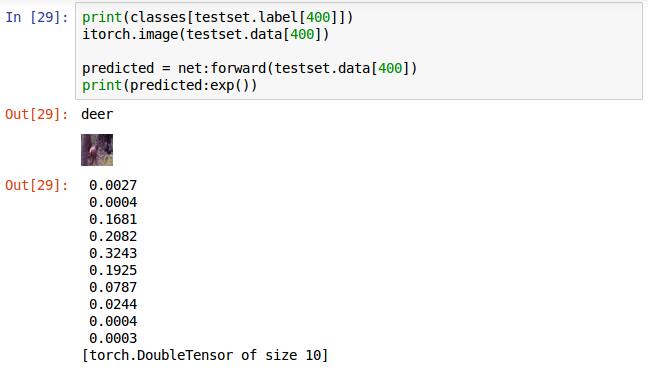
這張最大的是第5個值,即label對應的5,為deer識別正確。

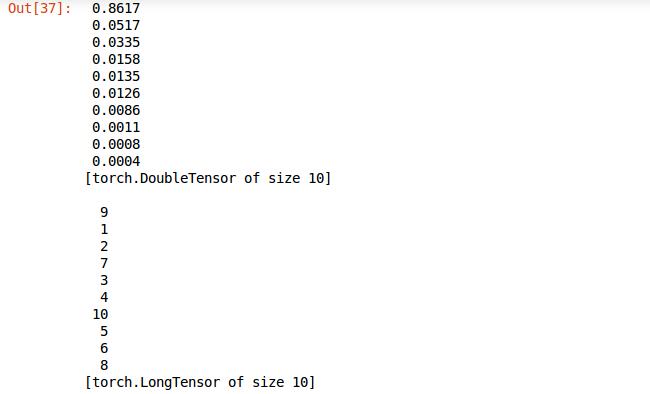
前面的輸出的格式還是有些不好,利用torch的sort排序方法將結果排序,返回值中confidences是屬於各類的可信度從大到小的排序結果,indices是可信度對應的類的標籤,看下列印結果圖,一目瞭然。


再進一步完善格式,只選取張量的第一個元素列印,並且利用先前定義的classes陣列輸出名字。
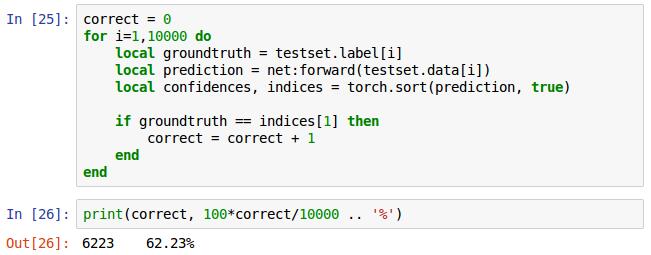
最後是驗證總的識別率,for迴圈,提取測試集中每張照片的標籤,每張測試集使用網路net的前向傳播forward獲得預測結果,將預測結果排序,true表示按遞減排序,對比預測結果同真是標籤,正確計數器correct加1,將correct除以測試總數10000乘以100得出百分比,這是我迭代10次的正確率為62.23%。

這是統計每類對應的正確率,宣告一個數組計數器,用來記錄每一類正確識別的個數,改動if語句裡面的賦值語句即可完成計數,其他同上。
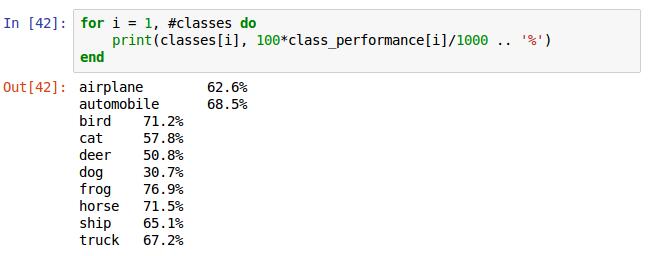
for迴圈1到classes的陣列長度,即10。class_performance[i]裡儲存的是第i個類的真確識別個數,由於每類有1000張,除以1000,列印結果。
預測的原始碼
--normalize test data
testset.data = testset.data:double();
for i = 1,3 do
testset.data[{ {}, {i}, {}, {} }]:add(-mean[i])
testset.data[{ {}, {i}, {}, {} }]:div(stdv[i])
end
--predict test and print confidences
print(classes[testset.label[400]])
itorch.image(testset.data[400])
predicted = net:forward(testset.data[400])
print(predicted:exp())
--sort confidence and print predicted result
confidences, indices = torch.sort(predicted, true)
print(confidences[1])
print(indices[1])
print(classes[indices[1]])
--correct rate in total
correct = 0
for i=1,10000 do
local groundtruth = testset.label[i]
local prediction = net:forward(testset.data[i])
local confidences, indices = torch.sort(prediction, true)
if groundtruth == indices[1] then
correct = correct + 1
end
end
print(correct, 100*correct/10000 .. '%')
--correct rate every class
class_performance = {0,0,0,0,0,0,0,0,0,0}
for i = 1,10000 do
local groundtruth = testset.label[i]
local prediction = net:forward(testset.data[i])
local confidences, indices = torch.sort(prediction, true)
if groundtruth == indices[1] then
class_performance[groundtruth] = class_performance[groundtruth] + 1
end
end
for i = 1, #classes do
print(classes[i], 100*class_performance[i]/1000 .. '%')
end
如果想利用GPU訓練該例項用下面的程式碼替代上文中的訓練部分即可
require 'cunn'
net = net:cuda()
criterion = criterion:cuda()
trainset.data = trainset.data:cuda()
trainset.label = trainset.label:cuda()
修改這些就可以使用GPU程式設計。
相關推薦
Torch7深度學習教程(七)
這一章主要分享預測的基本操作,並且先將前面分享的內容總結下,完整地實現CNN影象分類的例項 require 'paths'; require 'nn'; ---Load TrainSet paths.filep("/home/ubuntu64/c
Torch7深度學習教程(五)
這一節先介紹一些基本操作,然後再對我們前面建立的網路進行訓練 神經網路的前向傳播和反向傳播 隨即生產一張照片,1通道,32x32畫素的。為了直觀像是,匯入image包,然後用itorch.image()方法顯示生成的圖片,就是隨即的一些點
Torch7深度學習教程(二)
Torch裡非常重要的結構Tensor(張量),類似於Python用的Numpy 宣告Tensor的格式如12行,列印a可以得到一個5x3的矩陣,這裡的沒有賦初值,但是Torch也會隨即賦值的,具體的就跟c++裡面的生命了變數雖沒有初始化,但是還是會
吳恩達深度學習筆記(七) —— Batch Normalization
學習 bat 中括號 和平 一個 內容 batch 可能 加權 主要內容: 一.Batch Norm簡介 二.歸一化網絡的激活函數 三.Batch Norm擬合進神經網絡 四.測試時的Batch Norm 一.Batch Norm簡介 1.在機器學習中,我們一般
深度學習方法(七):最新SqueezeNet 模型詳解,CNN模型引數降低50倍,壓縮461倍!
歡迎轉載,轉載請註明:本文出自Bin的專欄blog.csdn.net/xbinworld。 技術交流QQ群:433250724,歡迎對演算法、技術感興趣的同學加入。 本文講一下最新由UC Berkeley和Stanford研究人員一起完成的Sque
深度學習基礎(七)—— Activation Function
1. Sigmoid 函式定義: f(x)=11+e−xf(x)=11+e−x 對應的影象是: 優點: Sigmoid函式的輸出對映在(0,1)之間,單調連續,輸出範圍有限,優化穩定,可以用作輸出層。 求導容易。 缺點: si
深度學習系列(七):自編碼網路與PCA特徵學習的分類對比實驗
上節我們看到自編碼網路額隱含層可以用於原始資料的降維(其實也可以升維,不過把隱含層的單元設定的比輸入維度還要多),換而言之就是特徵學習,那麼學習到的這些特徵就可以用於分類了,本節主要試驗下這些特徵用於分類的效果。 先以最簡單的三層自編碼網路為例,先訓練自編碼網
TensorFlow:實戰Google深度學習框架(七)迴圈神經網路
RNN網路確實可以解決和時間序列有關係的問題,但是,在實際的應用過程中,我們可以看到效能並不是很好。RNN記住了以前輸入的所有資訊,但是有時候並不需要記住以前時刻的所有資訊,增加了很多的系統記憶體負擔;有時候我們的確需要記住很長時間以前資訊,但是又容易出現梯度爆炸或者梯度消失的問題。針對於這個問題,人們開
基於PyTorch的深度學習入門教程(七)——PyTorch重點綜合實踐
前言 PyTorch提供了兩個主要特性: (1) 一個n維的Tensor,與numpy相似但是支援GPU運算。 (2) 搭建和訓練神經網路的自動微分功能。 我們將會使用一個全連線的ReLU網路作為例項。該網路有一個隱含層,使用梯度下降來訓練,目標是最小化
python基礎教程(第三版)學習筆記(七)
第七章 再談抽象 自定義`類和物件 7.1 物件魔法 多型:可對不同型別的物件執行相同的操作,而這些操作就像“被施了魔法”一樣能夠正常執行。 封裝:對外部隱藏有關物件工作原理的細節。 繼承:可基於通用類創建出專用類。 7.1.1 多型 大致意味著即便你不知道變數指向的是哪種物件,也能夠對其執行操作,
GPU(CUDA)學習日記(七)------ Parallel Nsight 雙機除錯經驗 以及 一些比較基礎的教程
1,聯通兩臺電腦:準備兩臺電腦,分別稱為主機和除錯機,在主機端執行vs2010,在除錯機上進行除錯,其中至少除錯機應支援CUDA,使兩臺機器在同一個區域網,或直接將兩臺電腦用網線連線起來; 2,在主機端設定除錯機的IP:在vs2010的解決方案資源管理器中,右鍵vs2
設計模式學習總結(七)適配器模式(Adapter)
實現接口 國外 手機 額外 sed ges program ebe 通過 適配器模式主要是通過適配器來實現接口的統一,如要實現國內手機在國外充電,則需要在不同的國家采用不同的適配器來進行兼容! 一、示例展示: 以下例子主要通過給筆記本電腦添加類似手機打電話和發短
mysql學習筆記(七)—— MySQL內連接和外連接
聚集函數 信息 _id left tro 做了 學習 作用 group MySQL內連接(inner join on) MySQL的內連接使用inner join on,它的效果跟使用where是一樣的,如果聯結的是兩個表,那麽需要左右的條件或者說字段是
Spring 學習筆記(七)—— 切入點表達式
service string 出現 targe || 參數 public 例如 語法 為了能夠靈活定義切入點位置,Spring AOP提供了多種切入點指示符。 execution———用來匹配執行方法的連接點
Nhibernate學習教程(2)-- 第一個NHibernate程序
collect 單元測試框架 文件映射 deb color rtu etc erb session管理 NHibernate之旅(2):第一個NHibernate程序 本節內容 開始使用NHibernate 1.獲取NHibernate 2.建立數據庫表 3.創建C#類庫
EF學習筆記(七):讀取關聯數據
取數據 microsoft image zha 手動 模型 取數 foreach ret 總目錄:ASP.NET MVC5 及 EF6 學習筆記 - (目錄整理) 本篇參考原文鏈接:Reading Related Data 本章主要講述加載顯示關聯數據; 數據加載分為以下三
python基礎教程(七)
如果 too import 初始 默認參數 hang zha lba 通過 本章介紹如何將語句組織成函數,這樣,可以告訴計算機如何做事。 下面編寫一小段代碼計算婓波那契數列(前兩個數的和是第三個數) fibs = [0,1] # 定義一個列表,初始內容是0,1
JavaScript學習日誌(七):表單腳本
prev 調用 don 表單 rip 如果 html image 集合 一,基礎知識 1,取得<form>元素引用的方式,常用的是通過id,其次可以通過document.forms可以取得頁面中所有的表單,在這個集合中,可以通過數值索引或name值來取得特定的表
深度學習筆記(九)感受野計算
lds 時有 輸入 計算 ret name %d have imsi 1 感受野的概念 在卷積神經網絡中,感受野的定義是 卷積神經網絡每一層輸出的特征圖(feature map)上的像素點在原始圖像上映射的區域大小。一般感受野大小是目標大小的兩倍左右最合適!
Java語言基礎學習筆記(七)
day tez lec mdk abd err .com mar mdm 烈7A茨諳9m繁5暗MChttp://www.zcool.com.cn/collection/ZMTg3NzE1Njg=.html 3馗iC蓖17握WM啦http://www.zcool.com.cn