
經典的文字資料預處理流程
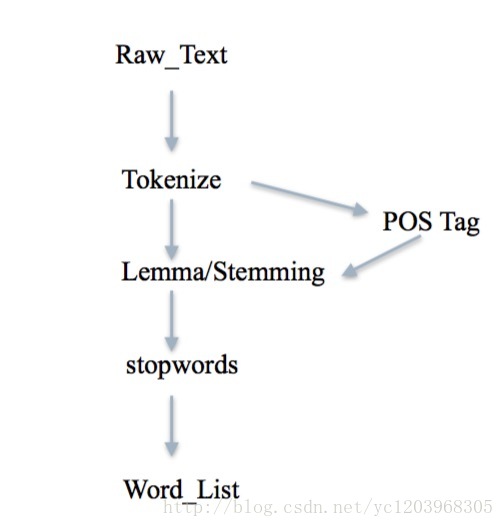
首先對文字進行分詞,因為可以直接用NLTK的分詞器,中文的可以用結巴分詞
在英文中,往往還需要對單詞進行詞幹提取和詞形歸一化。在詞形歸一的過程中如果結合POS Tag可以更好的進行詞形歸一。
去除停用詞,得到最終的詞列表
相關推薦
經典的文字資料預處理流程
首先對文字進行分詞,因為可以直接用NLTK的分詞器,中文的可以用結巴分詞 在英文中,往往還需要對單詞進行詞幹提取和詞形歸一化。在詞形歸一的過程中如果結合POS Tag可以更好的進行詞形歸一。 去除
幾種簡單的文字資料預處理方法
將開頭和結尾的一些資訊去掉,使得開頭如下: One morning, when Gregor Samsa woke from troubled dreams, he found himself transformed in his bed into a horrib
乾貨 | 自然語言處理(5)之英文文字挖掘預處理流程
前言原文連結:http://www.cnblogs.com/pinard/p/6756534.h
【處理流程01】資料預處理
參考文獻: 1.sklearn文件 2.部落格 1.標準化(也稱去均值和方差按比例縮放) (1)原因: 資料集的標準化對scikit-learn中實現的大多數機器學習演算法來說是常見的要求 。 如果個別特徵或多或少看起來不是很像標準正態分佈(具有零均值和單位方差),那麼它們的表現
資料探勘-資料預處理的簡單流程
此流程是一種簡單的寫法,在其他具體問題分析時,需有自己的分析方法,具體情況具體分析。 檢視train_data與test_data 的個特徵列的直方圖分佈情況,去掉分佈特差的特徵(分佈特別不一致的那種)。 # 標準化後資料視覺化 for col in data_minmax.
文字內容分析和智慧反饋(2)- 資料預處理和按緯度統計
書接上文,考慮4個核心功能的實現,先考慮:資料預處理和按緯度統計。 1、資料預處理 1.1、基本原則 首先,考慮資料的格式。 業務資料是儲存在關係型資料庫中的。資料分析的部分,我們將使用Weka,雖然Weka習慣ARFF格式,為了實現資料分析和提取的
文字挖掘預處理的流程總結(轉)
最近半年一直忙於專案,部落格也很少更新咯。有幾個專案做了不少JS相關的工作,基本都可以利用現成的開源方案,諸如angularJs、requireJs、bootstrap、knockoutJs、TypeScript、Jquery等等;之後也有專案是無UI的,純後端
資料預處理之抽取文字資訊(2)
摘要:大資料技術與我們日常生活越來越緊密,要做大資料,首要解決資料問題。原始資料存在大量不完整、不一致、有異常的資料,嚴重影響到資料建模的執行效率,甚至可能導致模型結果的偏差,因此要資料預處。資料預處理主要是將原始資料經過文字抽取、資料清理、資料整合、資料處理、資料變換、資料降維等處理後,不
NLP文字解析資料預處理的方法
假設我們現在有一個文字的多標籤的分類任務。其資料集的格式為w9410 w305 w1893 w307 w3259 w4480 w1718 w5700 w18973 w346 w11 w855 w1038 w12475 w146978 w11 w1076 w25 w7512 w
One_Hot資料預處理
在很多機器學習任務中,特徵並不總是連續值,而有可能是分類值 資料預處理之One-Hot 0.說在前面 1.什麼是One_Hot? 2.One
字串型別資料預處理的一個簡單小方法
今天開始試著去做kaggle上的入門競賽House Prices,因為資料集有81列,即81個特徵,一列一列處理資料很頭疼,於是想自己寫幾個方法 先寫了一個簡單的,可以自動把字串型別的特徵按數字順序編碼,如果資料中含有NAN或空元素就填入0,方便之後的處理 寫出來之後發現執行效率很低,處理一
【ADNI】資料預處理(6)ADNI_slice_dataloader ||| show image
ADNI Series 1、【ADNI】資料預處理(1)SPM,CAT12 2、【ADNI】資料預處理(2)獲取 subject slices 3、【ADNI】資料預處理(3)CNNs 4、【ADNI】資料預處理(4)Get top k slices according to CNN
【ADNI】資料預處理(5)Get top k slices (pMCI_sMCI) according to CNNs
ADNI Series 1、【ADNI】資料預處理(1)SPM,CAT12 2、【ADNI】資料預處理(2)獲取 subject slices 3、【ADNI】資料預處理(3)CNNs 4、【ADNI】資料預處理(4)Get top k slices according to CNN
【ADNI】資料預處理(4)Get top k slices according to CNNs
ADNI Series 1、【ADNI】資料預處理(1)SPM,CAT12 2、【ADNI】資料預處理(2)獲取 subject slices 3、【ADNI】資料預處理(3)CNNs 4、【ADNI】資料預處理(4)Get top k slices according to CNN
【ADNI】資料預處理(3)CNNs
ADNI Series 1、【ADNI】資料預處理(1)SPM,CAT12 2、【ADNI】資料預處理(2)獲取 subject slices 3、【ADNI】資料預處理(3)CNNs 4、【ADNI】資料預處理(4)Get top k slices according to CNN
【ADNI】資料預處理(2)獲取 subject slices
ADNI Series 1、【ADNI】資料預處理(1)SPM,CAT12 2、【ADNI】資料預處理(2)獲取 subject slices 3、【ADNI】資料預處理(3)CNNs 4、【ADNI】資料預處理(4)Get top k slices according to CNN
【ADNI】資料預處理(1)SPM,CAT12
ADNI Series 1、【ADNI】資料預處理(1)SPM,CAT12 2、【ADNI】資料預處理(2)獲取 subject slices 3、【ADNI】資料預處理(3)CNNs 4、【ADNI】資料預處理(4)Get top k slices according to CNN
Intel daal資料預處理
https://software.intel.com/en-us/daal-programming-guide-datasource-featureextraction-py # file: datasource_featureextraction.py #==============
資料預處理——標準化、歸一化、正則化
三者都是對資料進行預處理的方式,目的都是為了讓資料便於計算或者獲得更加泛化的結果,但是不改變問題的本質。 標準化(Standardization) 歸一化(normalization) 正則化(regularization) 歸一化 我們在對資料進行分析的時候,往往會遇到單個數據的各個維度量綱不同的
資料預處理案例
最近在做資料處理的一些事情,寫一下自己的一些處理方式,可能會比較low, 我這份資料是關於售賣房屋的方面的資料:從資料庫轉存的csv檔案,有三百多列,也就是有300多個特徵,並且資料的缺失值特別嚴重,拿到這樣一份殘缺不全的資料我也是很苦惱, 先看一下我的處理方式, 我進行資料處理用的是pa