
【處理流程01】資料預處理
1.標準化(也稱去均值和方差按比例縮放)
(1)原因:
資料集的標準化對scikit-learn中實現的大多數機器學習演算法來說是常見的要求 。
如果個別特徵或多或少看起來不是很像標準正態分佈(具有零均值和單位方差),那麼它們的表現力可能會較差。在實際情況中,我們經常忽略特徵的分佈形狀,直接經過去均值來對某個特徵進行中心化,再通過除以非常量特徵(non-constant features)的標準差進行縮放。
具體原因可以歸納為:去量綱、縮小差別加快收斂
(2)實現:(基於preprocessing模組,scale方法)
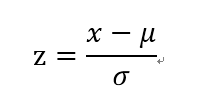
自己實現的話,可以基於上面的標準化公式:z= sklearn提供了專門的解決方法scale:
from sklearn import preprocessing
import StandarScaler方法能夠允許我們進行fit,從而儲存我們的模型,然後進行transform轉換:
from sklearn import preprocessing
scaler = preprocessing.StandardScaler().fit(X_train) 以模型形式實現標準化方法的儲存,便於用在測試集上
print(scaler. 2.將結果縮放到一個區間內
(1)原因:
這種方法也稱為0-1標準化,使用這個縮放的情況包括:增強極小方差的值還有保留稀疏樣本中的零值。
這種也很常見,可以實現將資料值縮放到[-1,1]區間,。這種情況適合在均值在0附近的值,或者稀疏矩陣。
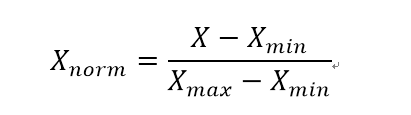
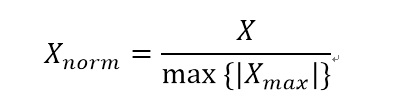
(2)實現:(基於 MinMaxScaler 和 MaxAbsScaler 方法)
基於 MinMaxScaler方法的實現
import numpy as np
from sklearn import preprocessing
X_train = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]])
min_max_sacler = preprocessing.MinMaxScaler()
min_max_sacler.fit(X_train)
print(min_max_sacler.transform(X_train))
基於 MaxAbsScaler 方法的實現:
import numpy as np
from sklearn import preprocessing
X_train = np.array([[ -4., -2., 2.],[ -5., 0., 0.],[ 0., 1., 6.],[10, 2, 3]])
max_abs_sacler = preprocessing.MaxAbsScaler()
max_abs_sacler.fit(X_train)
print(max_abs_sacler.transform(X_train))
附:
特殊資料縮放:
【1】縮放稀疏資料: 使用MaxAbsScaler可以進行稀疏資料的縮放;
【2】縮放異常點較多的資料: 使用robust_scale 或者RobustScaler;
3.非線性轉換–分位數轉換
(1)原因:
分位數轉換的目的也是把特徵資料轉換到一定的範圍內,或者讓他們符合一定的分佈。
分位數轉換利用的是資料的分位數資訊進行變換。它能夠平滑那些異常分佈,對於存在異常點的資料也很適合。
但是它會破壞原來資料的相關性和距離資訊。
(2)實現:(基於QantitleTransformer方法)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn import preprocessing
import numpy as np
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
quantile_transformer = preprocessing.QuantileTransformer(random_state=0)
X_train_trans = quantile_transformer.fit_transform(X_train)
X_test_trans = quantile_transformer.fit_transform(X_test)
#檢視分位數資訊,經過轉換以後,分位數的資訊基本不變
print(np.percentile(X_train[:, 0], [0, 25, 50, 75, 100]))
print(np.percentile(X_train_trans[:, 0], [0, 25, 50, 75, 100]))
4.歸一化
(1)原因:
需要說明是,這裡的歸一化不是對一列的特徵進行操作,而是對一行的樣本(記錄)進行操作!
歸一化適用於這樣的場景:需要使用點積,或者有的模型需要對樣本的相似性進行度量。
(2)實現:(基於normalize方法)
normalize方法裡面有個引數叫norm,可以實現L1、L2、max這三種計算
L1範數公式:
L2範數公式:
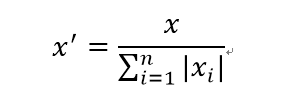
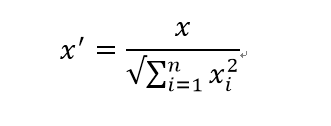
from sklearn import preprocessing
X = [[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.],
[ 3., 4., 5.]]
X1_normalized = preprocessing.normalize(X, norm='l1')
X2_normalized = preprocessing.normalize(X, norm='l2')
print(X1_normalized)
print(X2_normalized)
5.二值化
(1)原因:
特徵二值化是將數值特徵用閾值過濾得到布林值 的過程。(就是基於閾值做個判斷)
這對於下游的概率型模型是有用的,它們假設輸入資料是多值 伯努利分佈(Bernoulli distribution) 。
(2)實現:
X = [[ 1., -1., 2.],[ 2., 0., 0.],[ 0., 1., -1.]]
binarizer = preprocessing.Binarizer().fit(X) # fit does nothing
>>> binarizer
Binarizer(copy=True, threshold=0.0)
>>> binarizer.transform(X)
array([[ 1., 0., 1.],
[ 1., 0., 0.],
[ 0., 1., 0.]])
當然也可以手動指定閾值
binarizer = preprocessing.Binarizer(threshold=1.1)
>>> binarizer.transform(X)
array([[ 0., 0., 1.],
[ 1., 0., 0.],
[ 0., 0., 0.]])
6.分類特徵編碼
6.1序號編碼(就是按1,2,3順序這樣編碼)(基於LabelEncoder()方法)
這個的整數特徵表示並不能在scikit-learn的估計器中直接使用,因為這樣的連續輸入,估計器會認為類別之間是有序的,
但實際卻是無序的。
>>> le = preprocessing.LabelEncoder()
>>> le.fit(["paris", "paris", "tokyo", "amsterdam"])
LabelEncoder()
>>> list(le.classes_)
['amsterdam', 'paris', 'tokyo']
>>> le.transform(["tokyo", "tokyo", "paris"])
array([2, 2, 1]...)
>>> list(le.inverse_transform([2, 2, 1]))
['tokyo', 'tokyo', 'paris']
6.2One-Hot編碼(基於OneHotEncoder()方法)
One-Hot編碼針對的是希望將轉換後的結果直接能夠在後續估計器中使用的情況。本質上相當於破壞了上面連續序號編碼所造成的不存在的數值關係。
OneHotEncoder方法將分類特徵轉換為能夠被scikit-learn中模型使用的編碼。這種編碼只有對應位置有一個1,其餘位置都是0,以示區分。這樣顯然數值間就不存在1,2,3這樣產生的數值關係了。
>>> enc = preprocessing.OneHotEncoder()
>>> enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
OneHotEncoder(categorical_features='all', dtype=<... 'numpy.float64'>,
handle_unknown='error', n_values='auto', sparse=True)
>>> enc.transform([[0, 1, 3]]).toarray()
array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]])
6.3二進位制編碼
主要分兩步:1.先用序號編碼給每個類別賦予一個類別ID;2.然後將類別ID對應的二進位制編碼作為結果。
(其實就是用序號編碼的結果做一個十進位制轉二進位制的轉換)
7.缺失值的填補
基於Imputer方法,可以用均值、最值等形式進行填充
>>> import numpy as np
>>> from sklearn.preprocessing import Imputer
>>> imp = Imputer(missing_values='NaN', strategy='mean', axis=0)
>>> imp.fit([[1, 2], [np.nan, 3], [7, 6]])
Imputer(axis=0, copy=True, missing_values='NaN', strategy='mean', verbose=0)
>>> X = [[np.nan, 2], [6, np.nan], [7, 6]]
>>> print(imp.transform(X))
[[ 4. 2. ]
[ 6. 3.666...]
[ 7. 6. ]]
8.生成多項式特徵
(1)原因:
在機器學習中,通過增加一些輸入資料的非線性特徵來增加模型的複雜度通常是有效的。一個簡單通用的辦法是使用多項式特徵,這可以獲得特徵的更高維度和互相間關係的項。
(2)實現:基於 PolynomialFeatures方法
>>> import numpy as np
>>> from sklearn.preprocessing import PolynomialFeatures
>>> X = np.arange(6).reshape(3, 2)
>>> X
array([[0, 1],
[2, 3],
[4, 5]])
>>> poly = PolynomialFeatures(2) 比較容易,直接給定多項式冪次即可自動組合
>>> poly.fit_transform(X)
array([[ 1., 0., 1., 0., 0., 1.],
[ 1., 2., 3., 4., 6., 9.],
[ 1., 4., 5., 16., 20., 25.]])
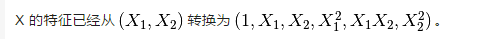
>>> X = np.arange(9).reshape(3, 3)
>>> X
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> poly = PolynomialFeatures(degree=3, interaction_only=True)
>>> poly.fit_transform(X)
array([[ 1., 0., 1., 2., 0., 0., 2., 0.],
[ 1., 3., 4., 5., 12., 15., 20., 60.],
[ 1., 6., 7., 8., 42., 48., 56., 336.]])
這種是指定只要特徵互動項的情況,利用interaction_only=True來指定。
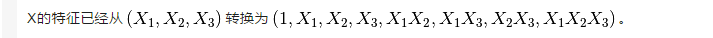
9.自定義轉換
基於FunctionTransformer方法
>>> import numpy as np
>>> from sklearn.preprocessing import FunctionTransformer
>>> transformer = FunctionTransformer(np.log1p)
>>> X = np.array([[0, 1], [2, 3]])
>>> transformer.transform(X)
array([[ 0. , 0.69314718],
[ 1.09861229, 1.38629436]])