
使用基於Apache Spark的隨機森林方法預測貸款風險
在本文中,我將向大家介紹如何使用Apache Spark的spark.ml庫中的隨機森林演算法來對銀行信用貸款的風險做分類預測。Spark的spark.ml庫基於DataFrame,它提供了大量的介面,幫助使用者建立和調優機器學習工作流。結合dataframe使用spark.ml,能夠實現模型的智慧優化,從而提升模型效果。
分類演算法
分類演算法是一類監督式機器學習演算法,它根據已知標籤的樣本(如已經明確交易是否存在欺詐)來預測其它樣本所屬的類別(如是否屬於欺詐性的交易)。分類問題需要一個已經標記過的資料集和預先設計好的特徵,然後基於這些資訊來學習給新樣本打標籤。所謂的特徵即是一些“是與否”的問題。標籤就是這些問題的答案。在下面這個例子裡,如果某個動物的行走姿態、游泳姿勢和叫聲都像鴨子,那麼就給它打上“鴨子”的標籤。

我們來看一個銀行信貸的信用風險例子:
- 我們需要預測什麼?
- 某個人是否會按時還款
- 這就是標籤:此人的信用度
- 你用來預測的“是與否”問題或者屬性是什麼?
- 申請人的基本資訊和社會身份資訊:職業,年齡,存款儲蓄,婚姻狀態等等……
- 這些就是特徵,用來構建一個分類模型,你從中提取出對分類有幫助的特徵資訊。
決策樹模型
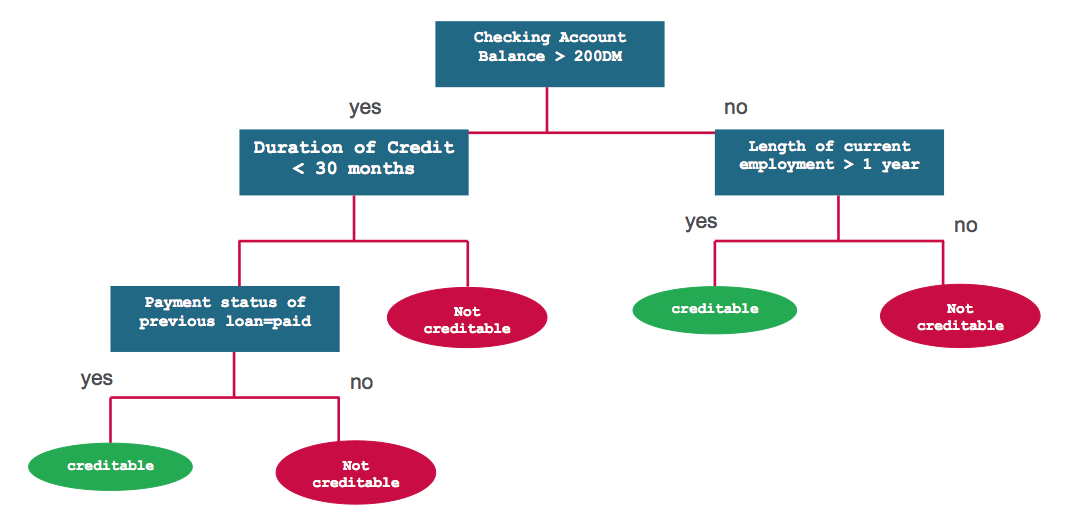
決策樹是一種基於輸入特徵來預測類別或是標籤的分類模型。決策樹的工作原理是這樣的,它在每個節點都需要計算特徵在該節點的表示式值,然後基於運算結果選擇一個分支通往下一個節點。下圖展示了一種用來預測信用風險的決策樹模型。每個決策問題就是模型的一個節點,“是”或者“否”的答案是通往子節點的分支。
- 問題1:賬戶餘額是否大於200元?
- 否
- 問題2:當前就職時間是否超過1年?
- 否
- 不可信賴
隨機森林模型
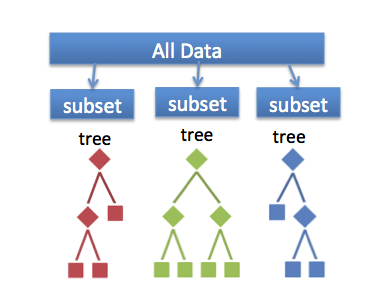
融合學習演算法結合了多個機器學習的演算法,從而得到了效果更好的模型。隨機森林是分類和迴歸問題中一類常用的融合學習方法。此演算法基於訓練資料的不同子集構建多棵決策樹,組合成一個新的模型。預測結果是所有決策樹輸出的組合,這樣能夠減少波動,並且提高預測的準確度。對於隨機森林分類模型,每棵樹的預測結果都視為一張投票。獲得投票數最多的類別就是預測的類別。
基於Spark機器學習工具來分析信用風險問題
我們使用德國人信用度資料集,它按照一系列特徵屬性將人分為信用風險好和壞兩類。我們可以獲得每個銀行貸款申請者的以下資訊:
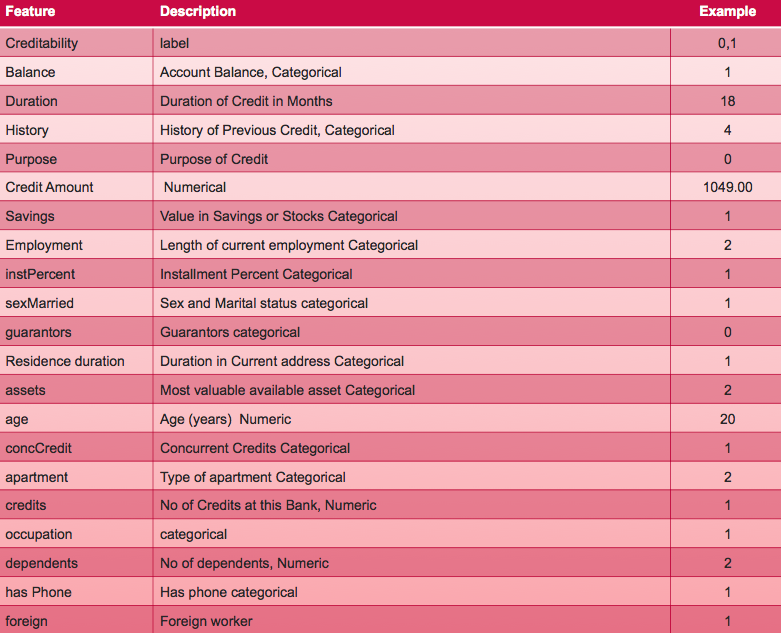
存放德國人信用資料的csv檔案格式如下:
1,1,18,4,2,1049,1,2,4,2,1,4,2,21,3,1,1,3,1,1,1
1,1,9,4,0,2799,1,3,2,3,1,2,1,36,3,1,2,3,2,1,1
1,2,12,2,9,841,2,4,2,2,1,4,1,23,3,1,1,2,1,1,1
在這個背景下,我們會構建一個由決策樹組成的隨機森林模型來預測是否守信用的標籤/類別,基於以下特徵:
- 標籤 -> 守信用或者不守信用(1或者0)
- 特徵 -> {存款餘額,信用歷史,貸款目的等等}
軟體
本教程將使用Spark 1.6.1
按照教程指示,登入MapR沙箱,使用者名稱為user01,密碼為mapr。將樣本資料檔案複製到你的沙箱主目錄下/user/user01 using scp。(注意,你可能需要先更新Spark的版本)開啟spark shell:
$spark-shell --master local[1]
載入並解析csv資料檔案
首先,我們需要引入機器學習相關的包。
import org.apache.spark.ml.classification.RandomForestClassifier
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.feature.VectorAssembler
import sqlContext.implicits._
import sqlContext._
import org.apache.spark.ml.tuning.{ ParamGridBuilder, CrossValidator }
import org.apache.spark.ml.{ Pipeline, PipelineStage }
我們用一個Scala的case類來定義Credit的屬性,對應於csv檔案中的一行。
// define the Credit Schema
case class Credit(
creditability: Double,
balance: Double, duration: Double, history: Double, purpose: Double, amount: Double,
savings: Double, employment: Double, instPercent: Double, sexMarried: Double, guarantors: Double,
residenceDuration: Double, assets: Double, age: Double, concCredit: Double, apartment: Double,
credits: Double, occupation: Double, dependents: Double, hasPhone: Double, foreign: Double
)下面的函式解析一行資料檔案,將值存入Credit類中。類別的索引值減去了1,因此起始索引值為0.
// function to create a Credit class from an Array of Double
def parseCredit(line: Array[Double]): Credit = {
Credit(
line(0),
line(1) - 1, line(2), line(3), line(4) , line(5),
line(6) - 1, line(7) - 1, line(8), line(9) - 1, line(10) - 1,
line(11) - 1, line(12) - 1, line(13), line(14) - 1, line(15) - 1,
line(16) - 1, line(17) - 1, line(18) - 1, line(19) - 1, line(20) - 1
)
}
// function to transform an RDD of Strings into an RDD of Double
def parseRDD(rdd: RDD[String]): RDD[Array[Double]] = {
rdd.map(_.split(",")).map(_.map(_.toDouble))
}接下去,我們匯入germancredit.csv檔案中的資料,存為一個String型別的RDD。然後我們對RDD做map操作,將RDD中的每個字串經過ParseRDDR函式的對映,轉換為一個Double型別的陣列。緊接著是另一個map操作,使用ParseCredit函式,將每個Double型別的RDD轉換為Credit物件。toDF()函式將Array[[Credit]]型別的RDD轉為一個Credit類的Dataframe。
// load the data into a RDD
val creditDF= parseRDD(sc.textFile("germancredit.csv")).map(parseCredit).toDF().cache()
creditDF.registerTempTable("credit")
DataFrame的printSchema()函式將各個欄位含義以樹狀的形式列印到控制檯輸出。
// Return the schema of this DataFrame
creditDF.printSchema
root
|-- creditability: double (nullable = false)
|-- balance: double (nullable = false)
|-- duration: double (nullable = false)
|-- history: double (nullable = false)
|-- purpose: double (nullable = false)
|-- amount: double (nullable = false)
|-- savings: double (nullable = false)
|-- employment: double (nullable = false)
|-- instPercent: double (nullable = false)
|-- sexMarried: double (nullable = false)
|-- guarantors: double (nullable = false)
|-- residenceDuration: double (nullable = false)
|-- assets: double (nullable = false)
|-- age: double (nullable = false)
|-- concCredit: double (nullable = false)
|-- apartment: double (nullable = false)
|-- credits: double (nullable = false)
|-- occupation: double (nullable = false)
|-- dependents: double (nullable = false)
|-- hasPhone: double (nullable = false)
|-- foreign: double (nullable = false)
// Display the top 20 rows of DataFrame
creditDF.show
+-------------+-------+--------+-------+-------+------+-------+----------+-----------+----------+----------+-----------------+------+----+----------+---------+-------+----------+----------+--------+-------+
|creditability|balance|duration|history|purpose|amount|savings|employment|instPercent|sexMarried|guarantors|residenceDuration|assets| age|concCredit|apartment|credits|occupation|dependents|hasPhone|foreign|
+-------------+-------+--------+-------+-------+------+-------+----------+-----------+----------+----------+-----------------+------+----+----------+---------+-------+----------+----------+--------+-------+
| 1.0| 0.0| 18.0| 4.0| 2.0|1049.0| 0.0| 1.0| 4.0| 1.0| 0.0| 3.0| 1.0|21.0| 2.0| 0.0| 0.0| 2.0| 0.0| 0.0| 0.0|
| 1.0| 0.0| 9.0| 4.0| 0.0|2799.0| 0.0| 2.0| 2.0| 2.0| 0.0| 1.0| 0.0|36.0| 2.0| 0.0| 1.0| 2.0| 1.0| 0.0| 0.0|
| 1.0| 1.0| 12.0| 2.0| 9.0| 841.0| 1.0| 3.0| 2.0| 1.0| 0.0| 3.0| 0.0|23.0| 2.0| 0.0| 0.0| 1.0| 0.0| 0.0| 0.0|
| 1.0| 0.0| 12.0| 4.0| 0.0|2122.0| 0.0| 2.0| 3.0| 2.0| 0.0| 1.0| 0.0|39.0| 2.0| 0.0| 1.0| 1.0| 1.0| 0.0| 1.0|
| 1.0| 0.0| 12.0| 4.0| 0.0|2171.0| 0.0| 2.0| 4.0| 2.0| 0.0| 3.0| 1.0|38.0| 0.0| 1.0| 1.0| 1.0| 0.0| 0.0| 1.0|
| 1.0| 0.0| 10.0| 4.0| 0.0|2241.0| 0.0| 1.0| 1.0| 2.0| 0.0| 2.0| 0.0|48.0| 2.0| 0.0| 1.0| 1.0| 1.0| 0.0| 1.0|
| 1.0| 0.0| 8.0| 4.0| 0.0|3398.0| 0.0| 3.0| 1.0| 2.0| 0.0| 3.0| 0.0|39.0| 2.0| 1.0| 1.0| 1.0| 0.0| 0.0| 1.0|
| 1.0| 0.0| 6.0| 4.0| 0.0|1361.0| 0.0| 1.0| 2.0| 2.0| 0.0| 3.0| 0.0|40.0| 2.0| 1.0| 0.0| 1.0| 1.0| 0.0| 1.0|
| 1.0| 3.0| 18.0| 4.0| 3.0|1098.0| 0.0| 0.0| 4.0| 1.0| 0.0| 3.0| 2.0|65.0| 2.0| 1.0| 1.0| 0.0| 0.0| 0.0| 0.0|
| 1.0| 1.0| 24.0| 2.0| 3.0|3758.0| 2.0| 0.0| 1.0| 1.0| 0.0| 3.0| 3.0|23.0| 2.0| 0.0| 0.0| 0.0| 0.0| 0.0| 0.0|
| 1.0| 0.0| 11.0| 4.0| 0.0|3905.0| 0.0| 2.0| 2.0| 2.0| 0.0| 1.0| 0.0|36.0| 2.0| 0.0| 1.0| 2.0| 1.0| 0.0| 0.0|
| 1.0| 0.0| 30.0| 4.0| 1.0|6187.0| 1.0| 3.0| 1.0| 3.0| 0.0| 3.0| 2.0|24.0| 2.0| 0.0| 1.0| 2.0| 0.0| 0.0| 0.0|
| 1.0| 0.0| 6.0| 4.0| 3.0|1957.0| 0.0| 3.0| 1.0| 1.0| 0.0| 3.0| 2.0|31.0| 2.0| 1.0| 0.0| 2.0| 0.0| 0.0| 0.0|
| 1.0| 1.0| 48.0| 3.0| 10.0|7582.0| 1.0| 0.0| 2.0| 2.0| 0.0| 3.0| 3.0|31.0| 2.0| 1.0| 0.0| 3.0| 0.0| 1.0| 0.0|
| 1.0| 0.0| 18.0| 2.0| 3.0|1936.0| 4.0| 3.0| 2.0| 3.0| 0.0| 3.0| 2.0|23.0| 2.0| 0.0| 1.0| 1.0| 0.0| 0.0| 0.0|
| 1.0| 0.0| 6.0| 2.0| 3.0|2647.0| 2.0| 2.0| 2.0| 2.0| 0.0| 2.0| 0.0|44.0| 2.0| 0.0| 0.0| 2.0| 1.0| 0.0| 0.0|
| 1.0| 0.0| 11.0| 4.0| 0.0|3939.0| 0.0| 2.0| 1.0| 2.0| 0.0| 1.0| 0.0|40.0| 2.0| 1.0| 1.0| 1.0| 1.0| 0.0| 0.0|
| 1.0| 1.0| 18.0| 2.0| 3.0|3213.0| 2.0| 1.0| 1.0| 3.0| 0.0| 2.0| 0.0|25.0| 2.0| 0.0| 0.0| 2.0| 0.0| 0.0| 0.0|
| 1.0| 1.0| 36.0| 4.0| 3.0|2337.0| 0.0| 4.0| 4.0| 2.0| 0.0| 3.0| 0.0|36.0| 2.0| 1.0| 0.0| 2.0| 0.0| 0.0| 0.0|
| 1.0| 3.0| 11.0| 4.0| 0.0|7228.0| 0.0| 2.0| 1.0| 2.0| 0.0| 3.0| 1.0|39.0| 2.0| 1.0| 1.0| 1.0| 0.0| 0.0| 0.0|
+-------------+-------+--------+-------+-------+------+-------+----------+-----------+----------+----------+-----------------+------+----+----------+---------+-------+----------+----------+--------+-------+ dataframe初始化之後,你可以用SQL命令查詢資料了。下面是一些使用Scala DataFrame介面查詢資料的例子:
計算數值型資料的統計資訊,包括計數、均值、標準差、最小值和最大值。
// computes statistics for balance
creditDF.describe("balance").show
+-------+-----------------+
|summary| balance|
+-------+-----------------+
| count| 1000|
| mean| 1.577|
| stddev|1.257637727110893|
| min| 0.0|
| max| 3.0|
+-------+-----------------+
// compute the avg balance by creditability (the label)
creditDF.groupBy("creditability").avg("balance").show
+-------------+------------------+
|creditability| avg(balance)|
+-------------+------------------+
| 1.0|1.8657142857142857|
| 0.0|0.9033333333333333|
+-------------+------------------+你可以用某個表名將DataFrame註冊為一張臨時表,然後用SQLContext提供的sql方法執行SQL命令。下面是幾個用sqlContext查詢的例子:
sqlContext.sql("SELECT creditability, avg(balance) as avgbalance, avg(amount) as avgamt, avg(duration) as avgdur FROM credit GROUP BY creditability ").show
+-------------+------------------+------------------+------------------+
|creditability| avgbalance| avgamt| avgdur|
+-------------+------------------+------------------+------------------+
| 1.0|1.8657142857142857| 2985.442857142857|19.207142857142856|
| 0.0|0.9033333333333333|3938.1266666666666| 24.86|
+-------------+------------------+------------------+------------------+提取特徵
為了構建一個分類模型,你首先需要提取對分類最有幫助的特徵。在德國人信用度的資料集裡,每條樣本用兩個類別來標記——1(可信)和0(不可信)。
每個樣本的特徵包括以下的欄位:
- 標籤 -> 是否可信:0或者1
- 特徵 -> {“存款”,“期限”,“歷史記錄”,“目的”,“數額”,“儲蓄”,“是否在職”,“婚姻”,“擔保人”,“居住時間”,“資產”,“年齡”,“歷史信用”,“居住公寓”,“貸款”,“職業”,“監護人”,“是否有電話”,“外籍”}
定義特徵陣列
為了在機器學習演算法中使用這些特徵,這些特徵經過了變換,存入特徵向量中,即一組表示各個維度特徵值的數值向量。
下圖中,用VectorAssembler方法將每個維度的特徵都做變換,返回一個新的dataframe。
//define the feature columns to put in the feature vector
val featureCols = Array("balance", "duration", "history", "purpose", "amount",
"savings", "employment", "instPercent", "sexMarried", "guarantors",
"residenceDuration", "assets", "age", "concCredit", "apartment",
"credits", "occupation", "dependents", "hasPhone", "foreign" )
//set the input and output column names
val assembler = new VectorAssembler().setInputCols(featureCols).setOutputCol("features")
//return a dataframe with all of the feature columns in a vector column
val df2 = assembler.transform( creditDF)
// the transform method produced a new column: features.
df2.show
+-------------+-------+--------+-------+-------+------+-------+----------+-----------+----------+----------+-----------------+------+----+----------+---------+-------+----------+----------+--------+-------+--------------------+
|creditability|balance|duration|history|purpose|amount|savings|employment|instPercent|sexMarried|guarantors|residenceDuration|assets| age|concCredit|apartment|credits|occupation|dependents|hasPhone|foreign| features|
+-------------+-------+--------+-------+-------+------+-------+----------+-----------+----------+----------+-----------------+------+----+----------+---------+-------+----------+----------+--------+-------+--------------------+
| 1.0| 0.0| 18.0| 4.0| 2.0|1049.0| 0.0| 1.0| 4.0| 1.0| 0.0| 3.0| 1.0|21.0| 2.0| 0.0| 0.0| 2.0| 0.0| 0.0| 0.0|(20,[1,2,