
【從傳統方法到深度學習】影象分類
1. 問題
Kaggle上有一個影象分類比賽Digit Recognizer,資料集是大名鼎鼎的MNIST——圖片是已分割 (image segmented)過的28*28的灰度圖,手寫數字部分對應的是0~255的灰度值,背景部分為0。
from keras.datasets import mnist (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train[0] # .shape = 28*28 """ [[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0] ... [ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136 175 26 166 255 247 127 0 0 0 0] [ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253 225 172 253 242 195 64 0 0 0 0] ... [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]] """
手寫數字圖片是長這樣的:

import matplotlib.pyplot as plt
plt.subplot(1, 3, 1)
plt.imshow(x_train[0], cmap='gray')
plt.subplot(1, 3, 2)
plt.imshow(x_train[1], cmap='gray')
plt.subplot(1, 3, 3)
plt.imshow(x_train[2], cmap='gray')
plt.show()手寫數字識別可以看做是一個影象分類問題——對二維向量的灰度圖進行分類。
2. 識別
Rodrigo Benenson給出50種方法在MNIST的錯誤率。本文將從傳統方法過渡到深度學習,對比準確率來看。以下程式碼基於Python 3.6 + sklearn 0.18.1 + keras 2.0.4。
傳統方法
kNN
思路比較簡單:將二維向量拉直成一個一維向量,基於距離度量以判斷向量間的相似性。顯而易見,這種不帶特徵提取的樸素辦法,丟掉了二維向量中最重要的四周相鄰畫素的資訊。在比較乾淨的資料集MNIST還有不錯的表現,準確率為96.927%。此外,kNN模型訓練慢。
from sklearn import neighbors from sklearn.metrics import precision_score num_pixels = x_train[0].shape[0] * x_train[0].shape[1] x_train = x_train.reshape((x_train.shape[0], num_pixels)) x_test = x_test.reshape((x_test.shape[0], num_pixels)) knn = neighbors.KNeighborsClassifier() knn.fit(x_train, y_train) pred = knn.predict(x_test) precision_score(y_test, pred, average='macro') # 0.96927533865705706
MLP
多層感知器MLP (Multi Layer Perceptron)亦即三層的前饋神經網路,所採用的特徵與kNN方法類似——每一個畫素點的灰度值對應於輸入層的一個神經元,隱藏層的神經元數為700(一般介於輸入層與輸出層的數量之間)。sklearn的MLPClassifier實現MLP分類,下面給出基於keras的MLP實現。沒怎麼細緻地調參,準確率大概在98.530%左右。
from keras.layers import Dense
from keras.models import Sequential
from keras.utils import np_utils
# normalization
num_pixels = 28 * 28
x_train = x_train.reshape(x_train.shape[0], num_pixels).astype('float32') / 255
x_test = x_test.reshape(x_test.shape[0], num_pixels).astype('float32') / 255
# one-hot enconder for class
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_train.shape[1]
model = Sequential([
Dense(700, input_dim=num_pixels, activation='relu', kernel_initializer='normal'), # hidden layer
Dense(num_classes, activation='softmax', kernel_initializer='normal') # output layer
])
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=600, batch_size=200, verbose=2)
model.evaluate(x_test, y_test, verbose=0) # [0.10381294689745164, 0.98529999999999995]深度學習
LeCun早在1989年發表的論文 [1]中提出了用CNN (Convolutional Neural Networks)來做手寫數字識別,後來 [2]又改進到Lenet-5,其網路結構如下圖所示:
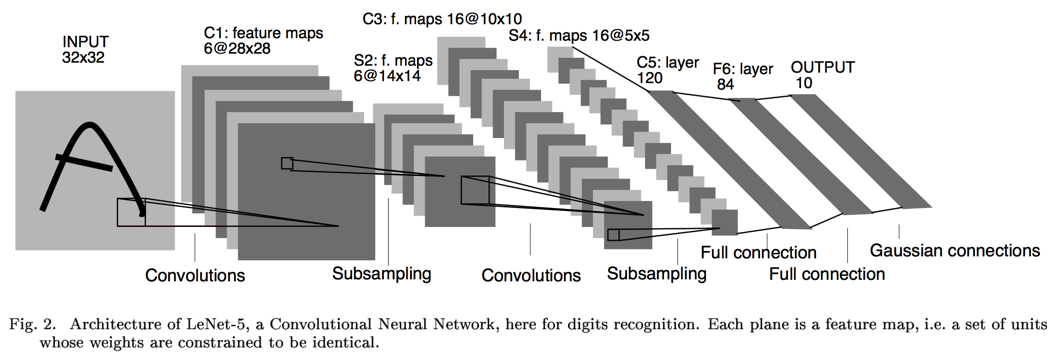
卷積、池化、卷積、池化,然後套2個全連線層,最後接個Guassian連線層。眾所周知,CNN自帶特徵提取功能,不需要刻意地設計特徵提取器。基於keras,Lenet-5 非正式實現如下:
import keras
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Dense, Dropout, Flatten, Activation
from keras.models import Sequential
from keras.utils import np_utils
img_rows, img_cols = 28, 28
# TensorFlow backend: image_data_format() == 'channels_last'
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1).astype('float32') / 255
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1).astype('float32') / 255
# one-hot code for class
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
num_classes = y_train.shape[1]
model = Sequential()
model.add(Conv2D(filters=6, kernel_size=(5, 5), padding='valid', input_shape=(28, 28, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Activation("sigmoid"))
model.add(Conv2D(16, kernel_size=(5, 5), padding='valid'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Activation("sigmoid"))
model.add(Dropout(0.25))
# full connection
model.add(Conv2D(120, kernel_size=(1, 1), padding='valid'))
model.add(Flatten())
# full connection
model.add(Dense(84, activation='sigmoid'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.SGD(lr=0.08, momentum=0.9),
metrics=['accuracy'])
model.summary()
model.fit(x_train, y_train, batch_size=32, epochs=8,
verbose=1, validation_data=(x_test, y_test))
model.evaluate(x_test, y_test, verbose=0)以上三種方法的準確率如下:
| 特徵 | 分類器 | 準確率 |
|---|---|---|
| gray | kNN | 96.927% |
| gray | 3-layer neural networks | 98.530% |
| Lenet-5 | 98.640% |
3. 參考資料
[1] LeCun, Yann, et al. "Backpropagation applied to handwritten zip code recognition." Neural computation 1.4 (1989): 541-551.
[2] LeCun, Yann, et al. "Gradient-based learning applied to document recognition." Proceedings of the IEEE 86.11 (1998): 2278-2324.
[3] Taylor B. Arnold, Computer vision: LeNet-5, AlexNet, VGG-19, GoogLeNet.
相關推薦
【從傳統方法到深度學習】影象分類
1. 問題 Kaggle上有一個影象分類比賽Digit Recognizer,資料集是大名鼎鼎的MNIST——圖片是已分割 (image segmented)過的28*28的灰度圖,手寫數字部分對應的是0~255的灰度值,背景部分為0。 from keras.datasets import mnist (x
【從傳統方法到深度學習】情感分析
為了記錄在競賽中入門深度學習的過程,我開了一個新系列【從傳統方法到深度學習】。 1. 問題 Kaggle競賽Bag of Words Meets Bags of Popcorn是電影評論(review)的情感分析,可以視作為短文字的二分類問題(正向、負向)。標註資料集長這樣: id sentiment
【神經網路與深度學習】neural-style、chainer-fast-neuralstyle影象風格轉換使用
1. 安裝 我的作業系統是win10,裝了Anaconda,TensorFlow包是通過pip安裝的,中間沒什麼可說的.具體看TensorFlow官網就可以了. 2. 使用 python neural_style.py --content <content fi
【神經網絡和深度學習】筆記 - 第二章 反向傳播算法
討論 固定 特征 array sed 並不會 思想 隨機梯度 相關 上一章中我們遺留了一個問題,就是在神經網絡的學習過程中,在更新參數的時候,如何去計算損失函數關於參數的梯度。這一章,我們將會學到一種快速的計算梯度的算法:反向傳播算法。 這一章相較於後面的章節涉及到的數學
【神經網路和深度學習】筆記
文章導讀: 1.交叉熵損失函式 1.1 交叉熵損失函式介紹 1.2 在MNIST數字分類上使用交叉熵損失函式 1.3 交叉熵的意義以及來歷 1.4 Softmax 2. 過擬合和正則化 2.1 過擬合 2.2 正則化 2.3 為什麼正則化可以減輕
深度學習,影象分類,從vgg到inception,到resnet
最近工作在做一件事情,就是把遊戲影象進行場景分類,相比於自然影象來說,遊戲影象種類較少,因此分類任務比較簡單,但是由於追求工程上的高精度和高效率,所以閱讀了vgg,inception,resnet等相關論文,並且都試了一下效果,算是對深度學習影象分類有了一個系統
【計算機視覺】【神經網路與深度學習】YOLO v2 detection訓練自己的資料
轉自:http://blog.csdn.net/hysteric314/article/details/54097845 說明 這篇文章是訓練YOLO v2過程中的經驗總結,我使用YOLO v2訓練一組自己的資料,訓練後的model,在閾值為.25的情況下,Reca
【神經網路與深度學習】【計算機視覺】SSD
背景介紹: 基於“Proposal + Classification” 的 Object Detection 的方法,R-CNN 系列(R-CNN、SPPnet、Fast R-CNN 以及 Faster R-CNN),取得了非常好的結果,但是在速度方面離實時效果還比較遠在提高 mAP 的同時兼顧速度,逐
深度學習、影象分類入門,從VGG16卷積神經網路開始
剛開始接觸深度學習、卷積神經網路的時候非常懵逼,不知道從何入手,我覺得應該有一個進階的過程,也就是說,理應有一些基本概念作為奠基石,讓你有底氣去完全理解一個龐大的卷積神經網路: 本文思路: 一、我認為學習卷積神經網路必須知道的幾個概念: 1、卷積過程: 我們經常說卷積
【神經網路與深度學習】Google Protocol Buffer介紹
簡介 什麼是 Google Protocol Buffer? 假如您在網上搜索,應該會得到類似這樣的文字介紹: Google Protocol Buffer( 簡稱 Protobuf) 是 Google 公司內部的混合語言資料標準,目前已經正在使用的有超過 48,162 種報文格式定義和超過 12,1
【神經網路與深度學習】【C/C++】ZLIB學習
zlib(http://zlib.NET/)提供了簡潔高效的In-Memory資料壓縮和解壓縮系列API函式,很多應用都會用到這個庫,其中compress和uncompress函式是最基本也是最常用的。不過很奇怪的是,compress和uncompress函式儘管已經非常
【神經網路與深度學習】Win10+VS2015 caffe環境搭建(極其詳細)
caffe是好用,可是配置其環境實在是太痛苦了,依賴的庫很多不說,在VS上編譯還各種報錯,你能想象那種被一百多個紅色提示所籠罩的恐懼。 且網上很多教程是VS2013環境下編譯的,問人很多也說讓我把15解除安裝了裝13,我的答案是:偏不 記下這個艱難的過程,萬一還要再來
【神經網路與深度學習】Caffe原始碼中各種依賴庫的作用及簡單使用
1. Boost庫:它是一個可移植、跨平臺,提供原始碼的C++庫,作為標準庫的後備。 在Caffe中用到的Boost標頭檔案包括: (1)、shared_ptr.hpp:智慧指標,使用它可以不需要考慮記憶體釋放的問題; (2)、date_time/posi
【神經網路與深度學習】【C/C++】使用blas做矩陣乘法
#define min(x,y) (((x) < (y)) ? (x) : (y)) #include <stdio.h> #include <stdlib.h> #include <cublas_v2.h> #include <iostream>
【神經網路與深度學習】【計算機視覺】Fast R-CNN
先回歸一下: R-CNN ,SPP-net R-CNN和SPP-net在訓練時pipeline是隔離的:提取proposal,CNN提取特徵,SVM分類,bbox regression。 Fast R-CNN 兩大主要貢獻點 : 1 實現大部分end-to-end訓練(提proposal階段除外):
乾貨丨深度學習、影象分類入門,從VGG16卷積神經網路開始
剛開始接觸深度學習、卷積神經網路的時候非常懵逼,不知道從何入手,我覺得應該有一個進階的過程,也就
深度學習:影象分類,定位檢測,語義分割,例項分割方法
計算機視覺領域四大基本任務中的應用,包括分類(圖a)、定位、檢測(圖b)、語義分割(圖c)、和例項分割(圖d)。 一、影象分類(image classification) 給定一張輸入影象,影象分類任務旨在判斷該影象所屬類別。 (1) 影象分類常用資料集 以下
深度學習之影象分類模型AlexNet解讀
版權宣告:本文為博主原創文章 https://blog.csdn.net/sunbaigui/article/details/39938097 在imagenet上的影象分類challenge上Alex提出的alexnet網路結構模型贏得了2012屆的冠軍。要研究CNN型別
深度學習在影象分類中的發展
深度學習是一門比較年輕的研究方向,從機器視覺到語音識別,以及自然語言識別等領域都有它的身影。說實話,喵哥此前只是知道有這個學科,但是並不清楚它到底是什麼,怎麼使用它。其實現在也是一無所知,但是我越發覺得深度學習是我們今後特別需要的專業,今天寫下這篇綜述性的文章,希望可以對以後
PaddlePaddle | 深度學習 101- 影象分類
本人僅以 PaddlePaddle 深度學習 101 官網教程為指導,添加個人理解和筆記,僅作為學習練習使用,若有錯誤,還望批評指教。–ZJ 環境: - Python 2.7 - Ubuntu 16.04 影象分類 本教程原始碼目錄在bo