
【從傳統方法到深度學習】情感分析
為了記錄在競賽中入門深度學習的過程,我開了一個新系列【從傳統方法到深度學習】。
1. 問題
Kaggle競賽Bag of Words Meets Bags of Popcorn是電影評論(review)的情感分析,可以視作為短文字的二分類問題(正向、負向)。標註資料集長這樣:
id sentiment review "2381_9" 1 "\"The Classic War of the Worlds\" by Timothy Hines is a very entertaining film that obviously goes to great effort and lengths to faithfully recreate H. G. Wells' classic book. Mr. Hines succeeds in doing so. ..." "2486_3" 0 "What happens when an army of wetbacks, towelheads, and Godless Eastern European commies gather their forces south of the border? Gary Busey kicks their butts, of course. Another laughable example of Reagan-era cultural fallout, Bulletproof wastes a decent supporting cast headed by L Q Jones and Thalmus Rasulala."
評價指標是AUC。因此,在測試資料集上應該給出概率而不是類別;即為predict_proba而不是predict:
# random frorest
result = forest.predict_proba(test_data_features)[:, 1]
# not `predict`
result = forest.predict(test_data_features)採用BoW特徵、RF (random forest)分類器,預測類別的AUC為0.84436,預測概率的AUC則為0.92154。
2. 分析
傳統方法
傳統方法一般會使用到兩種特徵:BoW (bag of words),n-gram。BoW忽略了詞序,只是單純對詞計數;而n-gram則是考慮到了詞序,比如bigram詞對"dog run"、"run dog"是兩個不同的特徵。BoW可以用CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(analyzer="word", tokenizer=None, preprocessor=None,
stop_words=None, max_features=5000)
train_data_features = vectorizer.fit_transform(clean_train_reviews)在一個句子中,不同的詞重要性是不同的;需要用TFIDF來給詞加權重。n-gram特徵則可以用TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(max_features=40000, ngram_range=(1, 3), sublinear_tf=True)
train_x = vectorizer.fit_transform(clean_train_reviews)使用unigram、bigram、trigram特徵 + RF分類器,AUC為0.93058;如果改成LR分類器,則AUC為0.96330。
深度學習
競賽tutorial給出用word2vec詞向量特徵來做分類,並兩個生成特徵思路:
- 對每一條評論的所有詞向量求平均,將其平均值作為改評論的特徵;
- 對訓練的詞向量做聚類,然後對評論中的詞類別進行計數,把這種bag-of-centroids作為特徵。
把生成這種特徵餵給分類器,進行分類。但是,這種方法的AUC不是太理想(在0.91左右)。無論是做平均還是聚類,一方面丟失了詞向量的特徵,另一方面忽略了詞序還有詞的重要性。因此,分類效果不如tfidf化的n-gram。
大神Mikolov在推出word2vec之後,又鼓搗出了doc2vec(gensim有實現)。簡單地說,就是可以把一段文字變成一個向量。與word2vec不同的是,引數除了doc對應的詞列表外,還有類別(TaggedDocument)。結果證明doc2vec的效果還不如word2vec生成特徵,AUC只有0.87915。
doc2vec = Doc2Vec(sentences, workers=8, size=300, min_count=40,
window=10, sample=1e-4)pangolulu嘗試把BoW與doc2vec做ensemble,採用stacking的思路——L1層BoW特徵做LR分類、doc2vec特徵做RBF-SVM分類,L2層將L1層的預測概率組合成一個新特徵,餵給LR分類器;多次迭代後求平均。ensemble結構圖如下:
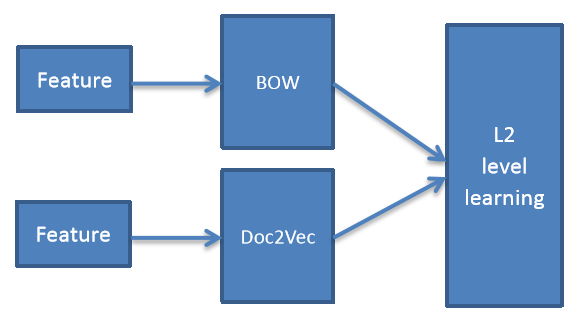
以上所有方法的AUC對比如下:
| 特徵 | 分類 | AUC |
|---|---|---|
| BoW | RF | 0.92154 |
| (1,3) gram, tfidf | LR | 0.96330 |
| (1,3) gram, tfidf | RF | 0.93058 |
| word2vec + avg | RF | 0.90798 |
| word2vec + cluster | RF | 0.91485 |
| doc2vec | RF | 0.87915 |
| doc2vec | LR | 0.90573 |
| BoW, doc2vec | ensemble | 0.93926 |
3. 參考資料
相關推薦
【從傳統方法到深度學習】情感分析
為了記錄在競賽中入門深度學習的過程,我開了一個新系列【從傳統方法到深度學習】。 1. 問題 Kaggle競賽Bag of Words Meets Bags of Popcorn是電影評論(review)的情感分析,可以視作為短文字的二分類問題(正向、負向)。標註資料集長這樣: id sentiment
【從傳統方法到深度學習】影象分類
1. 問題 Kaggle上有一個影象分類比賽Digit Recognizer,資料集是大名鼎鼎的MNIST——圖片是已分割 (image segmented)過的28*28的灰度圖,手寫數字部分對應的是0~255的灰度值,背景部分為0。 from keras.datasets import mnist (x
【神經網絡和深度學習】筆記 - 第二章 反向傳播算法
討論 固定 特征 array sed 並不會 思想 隨機梯度 相關 上一章中我們遺留了一個問題,就是在神經網絡的學習過程中,在更新參數的時候,如何去計算損失函數關於參數的梯度。這一章,我們將會學到一種快速的計算梯度的算法:反向傳播算法。 這一章相較於後面的章節涉及到的數學
【神經網路和深度學習】筆記
文章導讀: 1.交叉熵損失函式 1.1 交叉熵損失函式介紹 1.2 在MNIST數字分類上使用交叉熵損失函式 1.3 交叉熵的意義以及來歷 1.4 Softmax 2. 過擬合和正則化 2.1 過擬合 2.2 正則化 2.3 為什麼正則化可以減輕
【神經網路與深度學習】neural-style、chainer-fast-neuralstyle影象風格轉換使用
1. 安裝 我的作業系統是win10,裝了Anaconda,TensorFlow包是通過pip安裝的,中間沒什麼可說的.具體看TensorFlow官網就可以了. 2. 使用 python neural_style.py --content <content fi
【計算機視覺】【神經網路與深度學習】YOLO v2 detection訓練自己的資料
轉自:http://blog.csdn.net/hysteric314/article/details/54097845 說明 這篇文章是訓練YOLO v2過程中的經驗總結,我使用YOLO v2訓練一組自己的資料,訓練後的model,在閾值為.25的情況下,Reca
【神經網路與深度學習】【計算機視覺】SSD
背景介紹: 基於“Proposal + Classification” 的 Object Detection 的方法,R-CNN 系列(R-CNN、SPPnet、Fast R-CNN 以及 Faster R-CNN),取得了非常好的結果,但是在速度方面離實時效果還比較遠在提高 mAP 的同時兼顧速度,逐
【神經網路與深度學習】Google Protocol Buffer介紹
簡介 什麼是 Google Protocol Buffer? 假如您在網上搜索,應該會得到類似這樣的文字介紹: Google Protocol Buffer( 簡稱 Protobuf) 是 Google 公司內部的混合語言資料標準,目前已經正在使用的有超過 48,162 種報文格式定義和超過 12,1
【神經網路與深度學習】【C/C++】ZLIB學習
zlib(http://zlib.NET/)提供了簡潔高效的In-Memory資料壓縮和解壓縮系列API函式,很多應用都會用到這個庫,其中compress和uncompress函式是最基本也是最常用的。不過很奇怪的是,compress和uncompress函式儘管已經非常
【神經網路與深度學習】Win10+VS2015 caffe環境搭建(極其詳細)
caffe是好用,可是配置其環境實在是太痛苦了,依賴的庫很多不說,在VS上編譯還各種報錯,你能想象那種被一百多個紅色提示所籠罩的恐懼。 且網上很多教程是VS2013環境下編譯的,問人很多也說讓我把15解除安裝了裝13,我的答案是:偏不 記下這個艱難的過程,萬一還要再來
【神經網路與深度學習】Caffe原始碼中各種依賴庫的作用及簡單使用
1. Boost庫:它是一個可移植、跨平臺,提供原始碼的C++庫,作為標準庫的後備。 在Caffe中用到的Boost標頭檔案包括: (1)、shared_ptr.hpp:智慧指標,使用它可以不需要考慮記憶體釋放的問題; (2)、date_time/posi
【神經網路與深度學習】【C/C++】使用blas做矩陣乘法
#define min(x,y) (((x) < (y)) ? (x) : (y)) #include <stdio.h> #include <stdlib.h> #include <cublas_v2.h> #include <iostream>
【神經網路與深度學習】【計算機視覺】Fast R-CNN
先回歸一下: R-CNN ,SPP-net R-CNN和SPP-net在訓練時pipeline是隔離的:提取proposal,CNN提取特徵,SVM分類,bbox regression。 Fast R-CNN 兩大主要貢獻點 : 1 實現大部分end-to-end訓練(提proposal階段除外):
情感計算是人機互動核心?談深度學習在情感分析中的應用
除自然語言理解(NLU)外,情感計算(Affective Computing)也成為近年來 AI 領域熱門的研究方向之一。其中針對中文語境里人機互動中的情感、情緒識別與理解,竹間智慧已經做了許多有益的探索,特別是如何利用情感、情緒分析,來幫助機器人實現對「對話意圖」與「深
【深度學習】神經網路的優化方法
前言 \quad\quad 我們都知道,神經網路的學習目的是找到使損失函式的值儘可能小的引數,這是一個尋找最優引數的
【深度學習】線性迴歸(一)原理及python從0開始實現
文章目錄 線性迴歸 單個屬性的情況 多元線性迴歸 廣義線性模型 實驗資料集 介紹 相關連結 Python實現 環境 編碼
【備忘】從基礎到深度學習OpenCV視訊教程計算機視覺影象識別實戰Python C C++
├─第01講 工欲善其事必先利其器-影象處理基礎 │ cv第一次資料.rar │ 第一課.mkv │ ├─第02講 初探計算機視覺 │ cv_第一二講.pdf │ cv第二次資料.rar │ 第二課.mkv │
【深度學習】從fast.ai學到的十大技巧
那些允許新手在短短几周內實施世界級演算法的祕訣是什麼呢?在GPU驅動的喚醒中留下經驗豐富的深度學習從業者?請允許我用十個簡單的步驟告訴你。 如果您已經在練習深度學習並希望快速瞭解fast.ai在課程中使用的強大技術,請繼續閱讀。如果你已經完成了fast.ai並想要回
【深度學習】卷積計算與訓練模型的幾種方法
卷積計算 全連線層和卷積層的根本區別在於:全連線層(Dense層)從輸入空間中學到的是全域性模式,而卷積層學到的是區域性模式。 因為這個特性,所以卷積神經網路有兩個有趣的性質: 平移不變性:卷積神經網路在影象右下角學到的某個模式,它可以在任何地方識別出來這個模式;而對
【深度學習】學習深度學習的最好方法
學習深度學習的最好方法 親自實現,從零開始編寫能執行的程式,一遍看原始碼一邊思考。只有這樣才能正確理解深度學習,才能對那些看起來很高階的技術有完整的理解。 不依賴第三方庫,從最基礎的開始實現起,對於理解深度學習的意義重大。 在看數學公式和理論無法理解時,可以嘗試閱讀原始碼並執