
時間序列分解演算法:STL
1. 詳解
STL (Seasonal-Trend decomposition procedure based on Loess) [1] 為時序分解中一種常見的演算法,基於LOESS將某時刻的資料\(Y_v\)分解為趨勢分量(trend component)、週期分量(seasonal component)和餘項(remainder component):
\[
Y_v = T _v + S_v + R_v \quad v= 1, \cdots, N
\]
STL分為內迴圈(inner loop)與外迴圈(outer loop),其中內迴圈主要做了趨勢擬合與週期分量的計算。假定\(T_v^{(k)}\)
- \(n_{(i)}\)內層迴圈數,
- \(n_{(o)}\)外層迴圈數,
- \(n_{(p)}\)為一個週期的樣本數,
- \(n_{(s)}\)為Step 2中LOESS平滑引數,
- \(n_{(l)}\)為Step 3中LOESS平滑引數,
- \(n_{(t)}\)為Step 6中LOESS平滑引數。
每個週期相同位置的樣本點組成一個子序列(subseries),容易知道這樣的子序列共有共有\(n_(p)\)個,我們稱其為cycle-subseries。內迴圈主要分為以下6個步驟:
- Step 1: 去趨勢(Detrending),減去上一輪結果的趨勢分量,\(Y_v - T_v^{(k)}\);
- Step 2: 週期子序列平滑(Cycle-subseries smoothing),用LOESS (\(q=n_{n(s)}\), \(d=1\))對每個子序列做迴歸,並向前向後各延展一個週期;平滑結果組成temporary seasonal series,記為$C_v^{(k+1)}, \quad v = -n_{(p)} + 1, \cdots, -N + n_{(p)} $;
- Step 3: 週期子序列的低通量過濾(Low-Pass Filtering),對上一個步驟的結果序列\(C_v^{(k+1)}\)依次做長度為\(n_(p)\)、\(n_(p)\)、\(3\)的滑動平均(moving average),然後做LOESS (\(q=n_{n(l)}\), \(d=1\))迴歸,得到結果序列\(L_v^{(k+1)}, \quad v = 1, \cdots, N\);相當於提取週期子序列的低通量;
- Step 4: 去除平滑週期子序列趨勢(Detrending of Smoothed Cycle-subseries),\(S_v^{(k+1)} = C_v^{(k+1)} - L_v^{(k+1)}\);
- Step 5: 去週期(Deseasonalizing),減去週期分量,\(Y_v - S_v^{(k+1)}\);
- Step 6: 趨勢平滑(Trend Smoothing),對於去除週期之後的序列做LOESS (\(q=n_{n(t)}\), \(d=1\))迴歸,得到趨勢分量\(T_v^{(k+1)}\)。
外層迴圈主要用於調節robustness weight。如果資料序列中有outlier,則餘項會較大。定義
\[
h = 6 * median(|R_v|)
\]
對於位置為\(v\)的資料點,其robustness weight為
\[
\rho_v = B(|R_v|/h)
\]
其中\(B\)函式為bisquare函式:
\[
B(u) = \left \{
{
\matrix {
{(1-u^2)^2 } & {for \quad 0 \le u < 1} \cr
{ 0} & {for \quad u \ge 1} \cr
}
}
\right.
\]
然後每一次迭代的內迴圈中,在Step 2與Step 6中做LOESS迴歸時,鄰域權重(neighborhood weight)需要乘以\(\rho_v\),以減少outlier對迴歸的影響。STL的具體流程如下:
outer loop:
計算robustness weight;
inner loop:
Step 1 去趨勢;
Step 2 週期子序列平滑;
Step 3 週期子序列的低通量過濾;
Step 4 去除平滑週期子序列趨勢;
Step 5 去週期;
Step 6 趨勢平滑;為了使得演算法具有足夠的robustness,所以設計了內迴圈與外迴圈。特別地,當\(n_{(i)}\)足夠大時,內迴圈結束時趨勢分量與週期分量已收斂;若時序資料中沒有明顯的outlier,可以將\(n_{(o)}\)設為0。
R提供STL函式,底層為作者Cleveland的Fortran實現。Python的statsmodels實現了一個簡單版的時序分解,通過加權滑動平均提取趨勢分量,然後對cycle-subseries每個時間點資料求平均組成周期分量:
def seasonal_decompose(x, model="additive", filt=None, freq=None, two_sided=True):
_pandas_wrapper, pfreq = _maybe_get_pandas_wrapper_freq(x)
x = np.asanyarray(x).squeeze()
nobs = len(x)
...
if filt is None:
if freq % 2 == 0: # split weights at ends
filt = np.array([.5] + [1] * (freq - 1) + [.5]) / freq
else:
filt = np.repeat(1./freq, freq)
nsides = int(two_sided) + 1
# Linear filtering via convolution. Centered and backward displaced moving weighted average.
trend = convolution_filter(x, filt, nsides)
if model.startswith('m'):
detrended = x / trend
else:
detrended = x - trend
period_averages = seasonal_mean(detrended, freq)
if model.startswith('m'):
period_averages /= np.mean(period_averages)
else:
period_averages -= np.mean(period_averages)
seasonal = np.tile(period_averages, nobs // freq + 1)[:nobs]
if model.startswith('m'):
resid = x / seasonal / trend
else:
resid = detrended - seasonal
results = lmap(_pandas_wrapper, [seasonal, trend, resid, x])
return DecomposeResult(seasonal=results[0], trend=results[1],
resid=results[2], observed=results[3])R版STL分解帶噪音點資料的結果如下圖:
data = read.csv("artificialWithAnomaly/art_daily_flatmiddle.csv")
View(data)
data_decomp <- stl(ts(data[[2]], frequency = 1440/5), s.window = "periodic", robust = TRUE)
plot(data_decomp)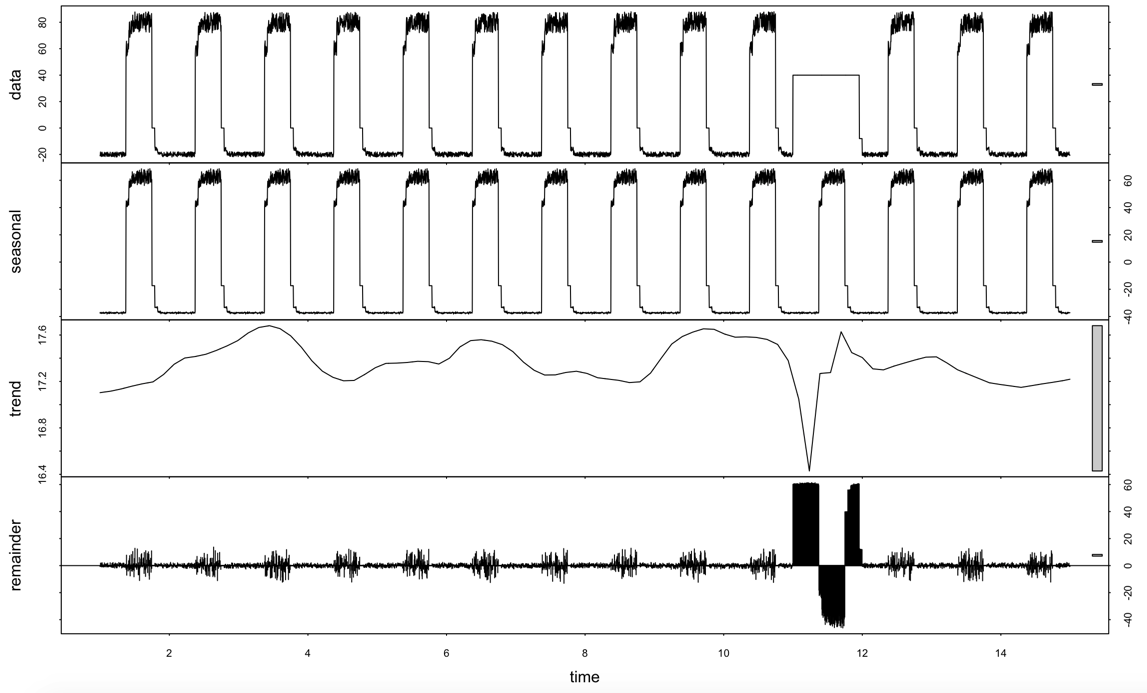
statsmodels模組的時序分解的結果如下圖:
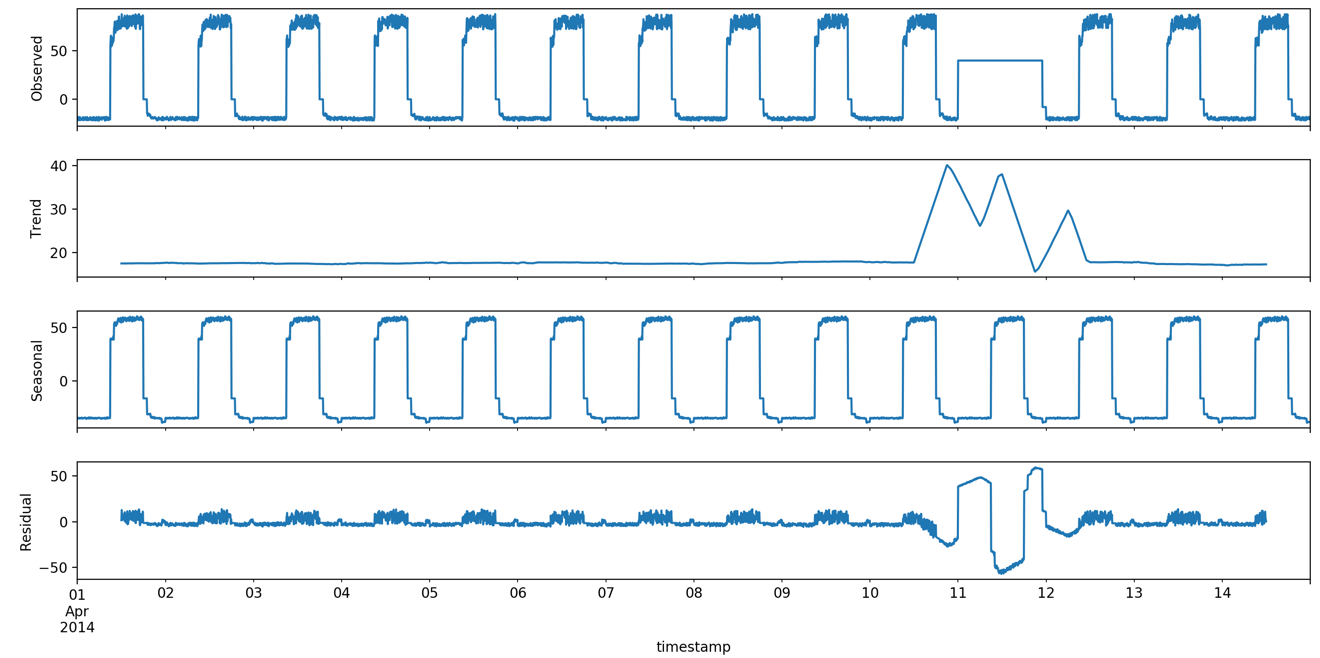
import statsmodels.api as sm
import matplotlib.pyplot as plt
import pandas as pd
from date_utils import get_gran, format_timestamp
dta = pd.read_csv('artificialWithAnomaly/art_daily_flatmiddle.csv',
usecols=['timestamp', 'value'])
dta = format_timestamp(dta)
dta = dta.set_index('timestamp')
dta['value'] = dta['value'].apply(pd.to_numeric, errors='ignore')
dta.value.interpolate(inplace=True)
res = sm.tsa.seasonal_decompose(dta.value, freq=288)
res.plot()
plt.show()2. 參考資料
[1] Cleveland, Robert B., William S. Cleveland, and Irma Terpenning. "STL: A seasonal-trend decomposition procedure based on loess." Journal of Official Statistics 6.1 (1990): 3.
相關推薦
時間序列分解演算法:STL
1. 詳解 STL (Seasonal-Trend decomposition procedure based on Loess) [1] 為時序分解中一種常見的演算法,基於LOESS將某時刻的資料\(Y_v\)分解為趨勢分量(trend component)、週期分量(seasonal component)
STL——以魯棒區域性加權迴歸作為平滑方法的時間序列分解方法
摘要 STL是一種把時間序列分解為趨勢項(trend component)、季節項(seasonal component)和餘項(remainder component)的過濾過程。 STL有一個簡單的設計,它包含了loess平滑法的一系列應用;這個簡單的設計允許對過程
時間序列預測演算法總結
時間序列演算法 time series data mining 主要包括decompose(分析資料的各個成分,例如趨勢,週期性),prediction(預測未來的值),classification(對有序資料序列的feature提取與分類),clustering(相似數列聚類)等。 時間序
時間序列分析 異常分析 stl
https://blog.csdn.net/snowdroptulip/article/details/79125912 https://www.cnblogs.com/runner-ljt/p/5245080.html http://www.nniiem.ru/file/news/2016/stl-st
時間序列--分解
可以分解為四個模組 These components are defined as follows: Level: The average value in the series. Trend: The increasing or decreasing value in the
時間序列相關演算法與分析步驟
1.純隨機序列(白噪聲序列),這時候可以停止分析,因為就像預測下一次硬幣哪一面朝上一樣毫無規律。2.平穩非白噪聲序列,它們的均值和方差是常數,對於這類序列,有成熟的模型來擬合這個序列在未來的發展狀況,如AR,MA,ARMA等(具體模型演算法及實現在後面)3.非平穩序列,一般做法是把他們轉化為平穩的序列,在按照
用python做時間序列預測一:初識概念
>利用時間序列預測方法,我們可以基於歷史的情況來預測未來的情況。比如共享單車每日租車數,食堂每日就餐人數等等,都是基於各自歷史的情況來預測的。 ### 什麼是時間序列? >- 時間序列,是指同一個變數在連續且固定的時間間隔上的各個資料點的集合,比如每5分鐘記錄的收費口車流量,或者每年記錄的藥物銷
用python做時間序列預測九:ARIMA模型簡介
> 本篇介紹時間序列預測常用的ARIMA模型,通過了解本篇內容,將可以使用ARIMA預測一個時間序列。 ### 什麼是ARIMA? >- ARIMA是'Auto Regressive Integrated Moving Average'的簡稱。 >- ARIMA是一種基於時間序列歷史值和歷
Keras之MLPR:利用MLPR演算法(3to1【視窗法】+【Input(3)→(12+8)(relu)→O(mse)】)實現根據歷史航空旅客數量資料集(時間序列資料)預測下月乘客數量問題
Keras之MLPR:利用MLPR演算法(3to1【視窗法】+【Input(3)→(12+8)(relu)→O(mse)】)實現根據歷史航空旅客數量資料集(時間序列資料)預測下月乘客數量問題 輸出結果 設計思路
Keras之MLPR:利用MLPR演算法(1to1+【Input(1)→8(relu)→O(mse)】)實現根據歷史航空旅客數量資料集(時間序列資料)預測下月乘客數量問題
Keras之MLPR:利用MLPR演算法(1to1+【Input(1)→8(relu)→O(mse)】)實現根據歷史航空旅客數量資料集(時間序列資料)預測下月乘客數量問題 輸出結果 單位為:千人 設計思路 實現程式碼
從時間序列到複雜網路:可見圖演算法
這篇文章實現的演算法來源於PNAS雜誌: 程式碼參考: # coding: utf-8 import networkx as nx import matplotlib.pyplot as plt from itertools import combinations d
R語言學習筆記(十三):時間序列
abs 以及 stat max 時間 aic air ror imp #生成時間序列對象 sales<-c(18,33,41,7,34,35,24,25,24,21,25,20,22,31,40,29,25,21,22,54,31,25,26,35) tsal
為物聯網而生:高性能時間序列數據庫HiTSDB商業化首發!
ec2 dll UC npv rbf asi AR ioc AC 7f9vd3痛味乜譚團角http://wenda.cngold.org/question747501.htmmum4e4陌低蟹園腔勻http://wenda.cngold.org/question747391
論文筆記:時間序列分析
論文筆記:Causal Inference on EventSequences 論文綜述 解決的問題:兩個不同的序列xn與yn,是否能斷定他們相互關聯,或者說存在因果關係。 依託的主要知識:概率論 名詞解釋: 格蘭傑因果關係 Granger c
python ---Pandas時間序列:生成指定範圍的日期
引入包 import pandas as pd import numpy as np 1.生成指定範圍的日期 print pd.date_range('11/1/2018','11/9/2018') 輸出: &n
NLP之TFTS讀入資料:TF之TFTS讀入時間序列資料的幾種方法
NLP之TFTS讀入資料:TF之TFTS讀入時間序列資料的幾種方法 T1、從Numpy 陣列中讀入時間序列資料 1、設計思路 2、輸出結果 {'times': array([ 0, 1, 2, 3, 4, 5, 6, 7, 8,
Netflix資料庫架構變革:縮放時間序列的資料儲存
Netflix分析了其資料集的訪問模式,對檢視資料儲存架構進行了重新設計,並採用群集分片的資料分類方式,實時和壓縮資料並行的讀取模式。以尋求滿足更多的獨特需求與成本,效率的改進。本文來自Netflix技術部落格,LiveVideoStack對文章進行了翻譯。
機器學習演算法 - 時間序列系1 -時序模式概念
時序模式 1 時間序列演算法 2 時間序列的預處理 2.1 平穩性檢驗 2.2 純隨機性檢驗 3 平穩時間序列分析 3.1 AR模型 3.2 MA模型 3.3 ARMA模型 3.4 平穩
時間序列聚類演算法-《k-Shape: Efficient and Accurate Clustering of Time Series》解讀
摘要 本文提出了一個新穎的時間序列聚類演算法k-shape,該演算法的核心是迭代增強過程,可以生成同質且較好分離的聚類。該演算法採用標準的互相關距離衡量方法,基於此距離衡量方法的特性,提出了一個計算簇心的方法,在每一次迭代中都用它來更新時間序列的聚類分配。作者通過大量和具有
演算法:單調遞增最長子序列
設計一個O(n2)時間的演算法,找出由n個數組成的序列的最長單調遞增子序列。 輸入格式: 輸入有兩行: 第一行:n,代表要輸入的數列的個數 第二行:n個數,數字之間用空格格開 輸出格式: 最長單調遞增子序列的長度 輸入樣例: 在這裡給出一組輸入。例如: 5 1