
python 二元Logistics Regression 迴歸分析(LogisticRegression)
綱要
boss說增加專案平臺分析方法:
T檢驗(獨立樣本T檢驗)、線性迴歸、二元Logistics迴歸、因子分析、可靠性分析
根本不懂,一臉懵逼狀態,分析部確實有人才,反正我是一臉懵
首先解釋什麼是二元Logistic迴歸分析吧
二元Logistics迴歸 可以用來做分類,迴歸更多的是用於預測
官方簡介:
連結:https://pythonfordatascience.org/logistic-regression-python/



Logistic regression models are used to analyze the relationship between a dependent variable (DV) and independent variable(s) (IV) when the DV is原文dichotomous. The DV is the outcome variable, a.k.a. the predicted variable, and the IV(s) are the variables that are believed to have an influence on the outcome, a.k.a. predictor variables. If the model contains 1 IV, then it is a simple logistic regression model, and if the model contains 2+ IVs, then it isa multiple logistic regression model. Assumptions for logistic regression models: The DV is categorical (binary) If there are more than 2 categories in terms of types of outcome, a multinomial logistic regression should be used Independence of observations Cannot be a repeated measures design, i.e. collecting outcomes at two different time points. Independent variables are linearly related to the log odds Absence of multicollinearity Lack of outliers

理解了什麼是二元以後,開始找庫
需要用的包
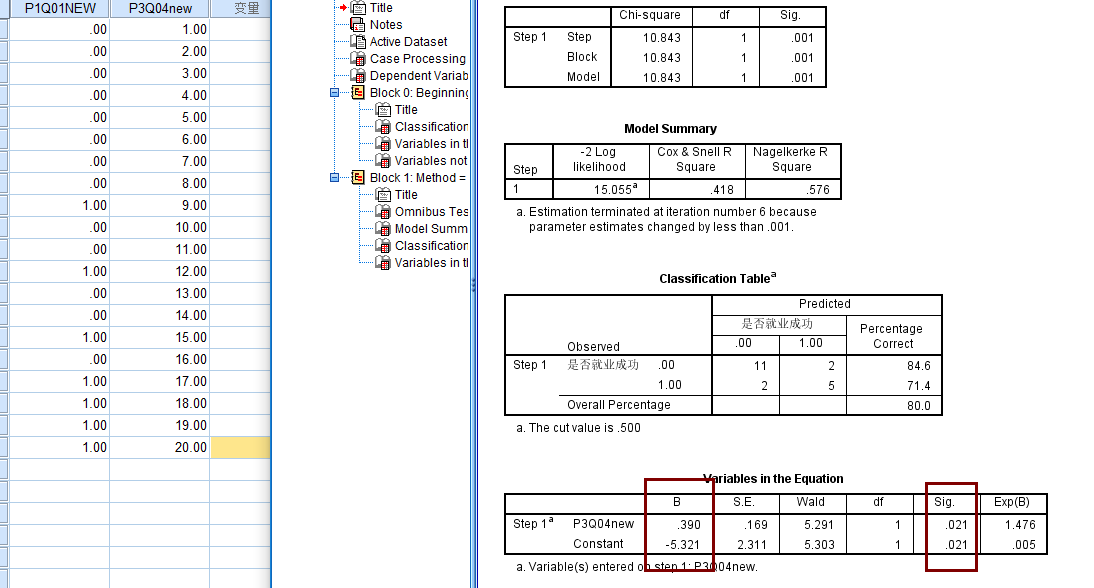
這裡需要特別說一下,第一天晚上我就用的logit,但結果不對,然後用機器學習搞,發現結果還不對,用spss比對的值
奇怪,最後沒辦法,只能抱大腿了,因為他們糾結Logit和Logistic的區別,然後有在群裡問了下,有大佬給解惑了
而且也有下面文章給解惑
1. 是 statsmodels 的logit模組
2. 是 sklearn.linear_model 的 LogisticRegression模組
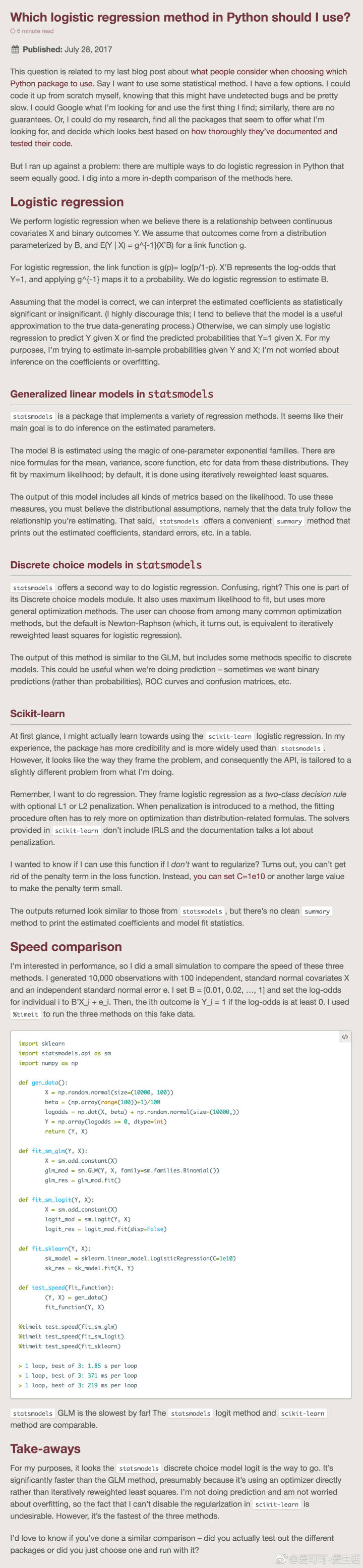
先說第一種方法
首先借鑑文章連結:https://blog.csdn.net/zj360202/article/details/78688070?utm_source=blogxgwz0
解釋的比較清楚,但是一定要注意一點就是,截距項,我就是在這個地方出的問題,因為我覺得不重要,就沒加
#!/usr/bin/env # -*- coding:utf-8 -*- import pandas as pd import statsmodels.api as sm import pylab as pl import numpy as np from pandas import DataFrame, Series from sklearn.cross_validation import train_test_split from sklearn.linear_model import LogisticRegression from sklearn import metrics from collections import OrderedDict data = { 'y': [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1], 'x': [i for i in range(1, 21)], } df = DataFrame(OrderedDict(data)) df["intercept"] = 1.0 # 截距項,很重要的呦,我就錯在這裡了 print(df) print("==================") print(len(df)) print(df.columns.values) print(df[df.columns[1:]]) logit = sm.Logit(df['y'], df[df.columns[1:]]) # result = logit.fit() # res = result.summary2() print(res)
這麼寫我覺得更好,因為上面那麼寫執行第二遍的時候總是報錯:
statsmodels.tools.sm_exceptions.PerfectSeparationError: Perfect separation detected, results not available
我改成x, y變數自己是自己的,就莫名其妙的好了
obj = TwoDimensionalLogisticRegressionModel() data_x = obj.SelectVariableSql( UserID, ProjID, QuesID, xVariable, DatabaseName, TableName, CasesCondition) data_y = obj.SelectVariableSql( UserID, ProjID, QuesID, yVariable, DatabaseName, TableName, CasesCondition) if len(data_x) != len(data_y): raise MyCustomError(retcode=4011) obj.close() df_X = DataFrame(OrderedDict(data_x)) df_Y = DataFrame(OrderedDict(data_y)) df_X["intercept"] = 1.0 # 截距項,很重要的呦,我就錯在這裡了 logit = sm.Logit(df_Y, df_X) result = logit.fit() res = result.summary() data = [j for j in [i for i in str(res).split('\n')][-3].split(' ') if j != ''][1:] return data
第二種方法,機器學習
參考連結:https://zhuanlan.zhihu.com/p/34217858
#!/usr/bin/env python # -*- coding:utf-8 -*- from collections import OrderedDict import pandas as pd examDict = { '學習時間': [i for i in range(1, 20)], '通過考試': [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1] } examOrderDict = OrderedDict(examDict) examDF = pd.DataFrame(examOrderDict) # print(examDF.head()) exam_X = examDF.loc[:, "學習時間"] exam_Y = examDF.loc[:, "通過考試"] print(exam_X) # print(exam_Y) from sklearn.cross_validation import train_test_split X_train,X_test,y_train, y_test = train_test_split(exam_X,exam_Y, train_size=0.8) # print(X_train.values) print(len(X_train.values)) X_train = X_train.values.reshape(-1, 1) print(len(X_train)) print(X_train) X_test = X_test.values.reshape(-1, 1) from sklearn.linear_model import LogisticRegression module_1 = LogisticRegression() module_1.fit(X_train, y_train) print("coef:", module_1.coef_) front = module_1.score(X_test,y_test) print(front) print("coef:", module_1.coef_) print("intercept_:", module_1.intercept_) # 預測 pred1 = module_1.predict_proba(3) print("預測概率[N/Y]", pred1) pred2 = module_1.predict(5) print(pred2)
但是,機器學習的這個有問題,就是隻抽取了15個值
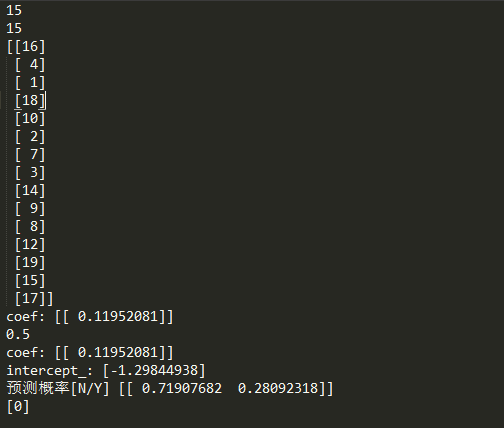
statsmodels的庫連結
Statsmodels:http://www.statsmodels.org/stable/index.html

相關推薦
python 二元Logistics Regression 迴歸分析(LogisticRegression)
綱要 boss說增加專案平臺分析方法: T檢驗(獨立樣本T檢驗)、線性迴歸、二元Logistics迴歸、因子分析、可靠性分析 根本不懂,一臉懵逼狀態,分析部確實有人才,反正我是一臉懵 首先解釋什麼是二元Logistic迴歸分析吧 二元Logistics迴歸 可以用來做分類,迴歸更多的是用於
python 二元Logistics Regression 回歸分析(LogisticRegression)
learn intercept onf 但是 art then 簡介 time HERE 綱要 boss說增加項目平臺分析方法: T檢驗(獨立樣本T檢驗)、線性回歸、二元Logistics回歸、因子分析、可靠性分析 根本不懂,一臉懵逼狀態,分析部確實有人才,反正
利用python/pandas/numpy做資料分析(三)-透視表pivot_table
透視表,根據一個或多個鍵進行聚合,並根據行列上的分組鍵將資料分配到各個矩形區域中. import numpy as np data=pd.DataFrame(np.arange(6).reshape((2,3)), index
ICA與雙迴歸分析(Dual_Regression)
簡單來講,雙迴歸分析是ICA的一個延伸分析,旨在將ICA的組成分結果映射回單個樣本中,從而計算其組差異。許多針對大腦的功能影像資料研究的文章採用過這種方法,在此不贅述。下面進入實現部分: 一. 軟體準備 1.Linux系統 2.FSL:http
迴歸分析(三)——多項式迴歸解決非線性問題
【將線性迴歸模型轉換為曲線——多項式迴歸】之前都是將解釋變數和目標值之間的關係假設為線性的,如果假設不成立,可以新增多項式選項,轉換為多項式迴歸。【sklearn實現多項式迴歸】1、PoltnomialFeatures實現二項迴歸# quadratic 二項迴歸 from
機器學習演算法的Python實現 (1):logistics迴歸 與 線性判別分析(LDA)
本文為筆者在學習周志華老師的機器學習教材後,寫的課後習題的的程式設計題。之前放在答案的博文中,現在重新進行整理,將需要實現程式碼的部分單獨拿出來,慢慢積累。希望能寫一個機器學習演算法實現的系列。 本文主要包括: 1、logistics迴歸 2、線性判別分析(LDA) 使
python的計數引用分析(一)
結果 class 默認 htm ron 如果 目前 解釋器 bject python的垃圾回收采用的是引用計數機制為主和分代回收機制為輔的結合機制,當對象的引用計數變為0時,對象將被銷毀,除了解釋器默認創建的對象外。(默認對象的引用計數永遠不會變成0) 所有的計數引用+1的
python的引用計數分析(二)
裏的 %20 賦值 手動 計數 python 作用域 新的 pri python所有對象引用計數被減少1的情況: 一.對象的別名被賦予新的對象; a = 23345455 # 增加了一個引用 b = a # 增加了一個引用 print(sys.getrefcount(
python的random模塊函數分析(一)
分析 之前 pri orm cnblogs 進行 ron sample 函數封裝 random是python產生偽隨機數的模塊,隨機種子默認為系統時鐘。下面分析模塊中的方法: 1.random.randint(start,stop): 這是一個產生整數隨機數的函數,參數st
[讀書筆記] Python數據分析 (一) 準備工作
基礎 htm 環境 防止 功能 多維 處理工具 ati 增強 1. python中數據結構:矩陣,數組,數據框,通過關鍵列相互聯系的多個表(SQL主鍵,外鍵),時間序列 2. python 解釋型語言,程序員時間和CPU時間衡量,高頻交易系統 3. 全局解釋器鎖GIL,
[python機器學習及實踐(6)]Sklearn實現主成分分析(PCA)
相關性 hit 變量 gray tran total 空間 mach show 1.PCA原理 主成分分析(Principal Component Analysis,PCA), 是一種統計方法。通過正交變換將一組可能存在相關性的變量轉換為一組線性不相關的變量,轉換後的這組
Python數據分析(二)pandas缺失值處理
taf spa 3.0 .data float 數據分析 pandas panda pri import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index
用Python預測某某國際平臺概率分析(一):這個到底是什麽,是什麽樣的規則?
.... pan 又是 參與 其中 其他 nbsp 中國古代 合計 這個到底是什麽? 想必大家都玩過體彩,福彩,甚至6禾踩(懂了就行),以隨機的方式依次羅列出6個(或者7個,或者8個)的數字的集合,參與者可根據已經預訂的數字進行匹配,匹配正確3個以上是什麽什麽樣的獎勵,匹
深入理解線性迴歸演算法(二):正則項的詳細分析
前言 當模型的複雜度達到一定程度時,則模型處於過擬合狀態,類似這種意思相信大家看到個很多次了,本文首先討論了怎麼去理解複雜度這一概念,然後回顧貝葉斯思想(原諒我有點囉嗦),並從貝葉斯的角度去理解正則項的含義以及正則項降低模型複雜度的方法,最後總結全文。 &nb
基於Python的頻譜分析(一)
1、傅立葉變換 傅立葉變換是訊號領域溝通時域和頻域的橋樑,在頻域裡可以更方便的進行一些分析。傅立葉主要針對的是平穩訊號的頻率特性分析,簡單說就是具有一定週期性的訊號,因為傅立葉變換採取的是有限取樣的方式,所以對於取樣長度和取樣物件有著一定的要求。 2、基於Python的頻譜分析 將時域訊號通過FFT轉換
python資料探勘實戰筆記——文字分析(6):關鍵詞提取
緊接上篇的文件,這節學習關鍵字的提取,關鍵詞——keyword,是人們快速瞭解文件內容,把握主題的重要內容。 #匯入需要的模組 import os import codecs import pandas import jieba import jieba.ana
【機器學習】使用Python的自然語言工具包(NLTK)對Reddit新聞標題進行情感分析
讓我們使用Reddit API獲取新聞標題並執行情感分析 在我上一篇文章中,使用Python進行K-Means聚類,我們只是抓取了一些預編譯資料,但是對於這篇文章,我想更深入地瞭解一些實時資料。 使用Reddit API,我們可以從各種新聞subreddit獲得成千上萬的
Python 金融資料分析(二)
1.樣本資料位置 series = Series() series.mean() # 均數 series.median() # 中位數 series.mode() # 眾數 series.quantil
kaggle 影評情感分析(1)—— TF-IDF+Logistic迴歸/樸素貝葉斯/SGD
前言 kaggle的這個starting competition (Bag of words meet bags of popcorns) 其實是一個word2vec-tutorial, 但是本篇文章沒有用到 word2vec, 只用了 TF-IDF 的方式將句
SPSS進行logistic迴歸分析(含示例)
今天做數學建模2017B的時候用到了logistics分析來估計任務是否完成,給大家分享一下 二元logistics迴歸分析適用於因變數的結果只有兩個的情況,例如任務的完成與否(0或1),通過對任務是否完成的影響因素可以估計出任務為完成或未完成的預測概率。 例如2017B中對任務是否完成