
一、如何爬取鏈家網頁房源資訊
由於個人安裝的Python版本是2.7的,因此此後的相關程式碼也是該版本。
- 爬取網頁所有資訊
利用urllib2包來抓取網頁的資訊,先介紹下urllib2包的urlopen函式。
urlopen:將網頁所有資訊存到一個object裡,我們可通過讀取這個object來獲得網頁資訊。例如,我們使用它來獲取百度首頁資訊如下。
import urllib2
f = urllib2.urlopen('http://www.baidu.com')
f.read(100)通過上面的程式碼我們讀取了百度首頁的前100個字元:
'<!DOCTYPE html><!--STATUS OK--> 有時可能會出現編碼問題導致開啟的是亂碼,只需修改下編碼格式即可:
f.read(100).decode('utf-8')通過這種方法我們可以獲得鏈家一個二手房首頁的資訊:
import urllib2
url = 'http://sz.lianjia.com/ershoufang/pg'
res = urllib2.urlopen(url)
content = res.read().decode('utf-8')於是網頁資訊便存在了content之中。
- 獲取房源資訊
上面我們已經獲得了一整個的網頁資訊,接下來需要獲取網頁中我們需要的有用資訊,我們的目標是獲取房源資訊,方法是利用正則表示式來獲取。關於正則表示式的知識可以參考一個網友的博文http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
首先,我們檢視下網頁資訊:
我們關注類似下面的這種資訊

data-el="region">萬科第五園一期</a> | 3室2廳 | 104.58平米 | 南 | 精裝</div><import urllib2
import re
url = 'http://sz.lianjia.com/ershoufang/pg/' 執行結果如下圖:
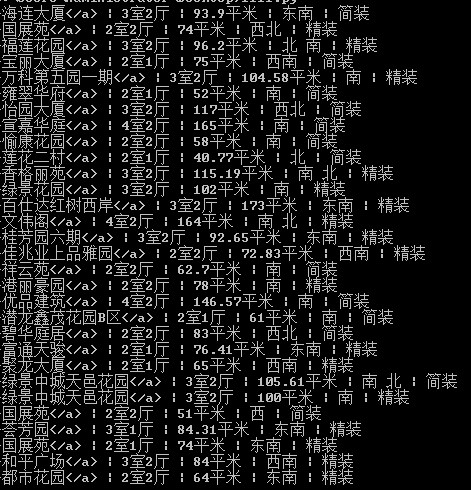
這樣就算是獲取了我想要的資訊了,不過這個資訊中間有個我們不想要的符號,接下來還需要去掉這個符號(可見這種方法比較繁瑣,效率也偏低)。
在這裡我通過字元替換操作,用空字元來替換這個多餘字元。
程式碼為:
import urllib2
import re
url = 'http://sz.lianjia.com/ershoufang/pg/'
res = urllib2.urlopen(url)
content=res.read().decode('utf-8')
result = re.findall(r'>.{1,100}?</div></div><div class="flood">',content)
for i in result:
print(i[0:-31].replace('</a>','').decode('utf-8'))
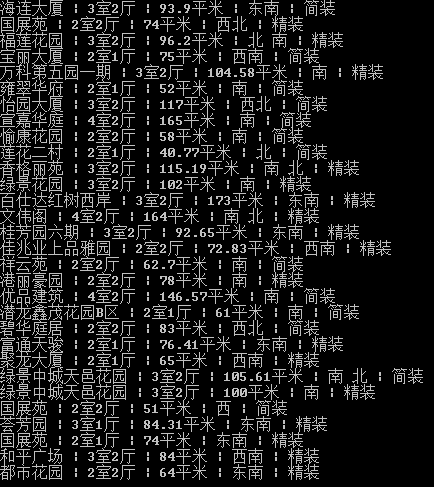
上面的方法雖然幫我們獲得了房源資訊,但是方法還是有些繁瑣,而且效率也並不高
我們利用上面的方法來爬取鏈家二手房100個頁面房源資訊,程式碼修改如下:
import urllib2
import time
import re
print(time.clock())
url = 'http://sz.lianjia.com/ershoufang/pg'
for x in range(101):
finalUrl = url + str(x) + '/'
res = urllib2.urlopen(finalUrl)
content=res.read().decode('utf-8')
result = re.findall(r'>.{1,100}?</div></div><div class="flood">',content)
for i in result:
print(i[0:-31].replace('</a>','').decode('utf-8'))
print(time.clock())
主要是測試一下執行時間,測試結果大概是350s左右(當然,主要還受網速的影響,而對程式碼本身來說消耗的大多數時間都在urlopen上),接下來,在下一篇中,將利用BeautifulSoup庫來實現房源的獲取。
相關推薦
一、如何爬取鏈家網頁房源資訊
由於個人安裝的Python版本是2.7的,因此此後的相關程式碼也是該版本。 爬取網頁所有資訊 利用urllib2包來抓取網頁的資訊,先介紹下urllib2包的urlopen函式。 urlopen:將網頁所有資訊存到一個object裡,我們可通過讀取這個o
利用高德API + Python爬取鏈家網租房資訊 01
看了實驗樓的專案發現五八同城爬取還是有點難度所以轉戰鏈家 實驗程式碼如下 from bs4 import BeautifulSoup from urllib.request import urlopen import csv url = 'https://gz.lia
Python的scrapy之爬取鏈家網房價資訊並儲存到本地
因為有在北京租房的打算,於是上網瀏覽了一下鏈家網站的房價,想將他們爬取下來,並儲存到本地。 先看鏈家網的原始碼。。房價資訊 都儲存在 ul 下的li 裡面 爬蟲結構: 其中封裝了一個數據庫處理模組,還有一個user-agent池。。 先看mylian
python爬蟲爬取鏈家二手房資訊
一種有想做個爬蟲的想法,正好上個月有足夠的時間和精力就學了下scrapy,一個python開源爬蟲框架。好多事開始以為很難,但真正下定決心去做的時候,才發現非常簡單,scrapy我從0基礎到寫出第一個可用的爬蟲只用了兩天時間,從官網例項到我的demo,真是遇到一堆問題,通
爬蟲爬取鏈家二手房資訊,對二手房做分析
import numpy as np import pandas as pd import matplotlib.pyplot as plt from bs4 import BeautifulSoup import requests def genera
爬取鏈家網租房資訊(萬級資料的簡單實現)
這不是一個很難的專案,沒有ajax請求,也沒有用框架,只是一個requests請求和BeautifulSoup的解析 不過,看這段程式碼你會發現,BeautifulSoup不止只有find和fing_all用於元素定位,還有fing_next等其他的更簡單的,
Scrapy實戰篇(一)之爬取鏈家網成交房源數據(上)
meta pat 分割 自定義 是不是 rom 創建 開始 mat 今天,我們就以鏈家網南京地區為例,來學習爬取鏈家網的成交房源數據。 這裏推薦使用火狐瀏覽器,並且安裝firebug和firepath兩款插件,你會發現,這兩款插件會給我們後續的數據提取帶來很大的方便。 首先
Java爬蟲學習《一、爬取網頁URL》
導包,如果是用的maven,新增依賴: <dependency> <groupId>commons-httpclient</groupId> <artifactId>commons
爬取鏈家網北京房源及房價分析
爬取鏈家網北京房源及房價分析 文章開始把我喜歡的這句話送個大家:這個世界上還有什麼比自己寫的程式碼執行在一億人的電腦上更酷的事情嗎,如果有那就是
scrapy實戰(一)-------------爬取鏈家網的二手房資訊
主要是通過scrapy爬取二手房相關資訊,只關心ershoufang相關連結,原始碼地址: 程式碼更新: 1.增加了爬取已成交房產的資訊,用於做為目標樣本來預測未成交房屋的價格。 2.資料通過pip
Scrapy實戰篇(二)之爬取鏈家網成交房源數據(下)
html win64 4.0 https set 爬蟲 使用 創建 鼓樓區 在上一小節中,我們已經提取到了房源的具體信息,這一節中,我們主要是對提取到的數據進行後續的處理,以及進行相關的設置。 數據處理 我們這裏以把數據存儲到mongo數據庫為例。編寫pipelines.p
爬取鏈家所有地區最新房源信息
lba body open jsonp ice {} unit sci split 使用scrapy,拼接url,找到翻頁參數,保存為json lj.py -- coding: utf-8 -- import copy import re import time impor
python爬蟲:爬取鏈家深圳全部二手房的詳細信息
data sts rip 二手房 lse area 列表 dom bubuko 1、問題描述: 爬取鏈家深圳全部二手房的詳細信息,並將爬取的數據存儲到CSV文件中 2、思路分析: (1)目標網址:https://sz.lianjia.com/ershoufang/ (2
Python爬蟲項目--爬取鏈家熱門城市新房
聲明 rules nal logging 命令行 -- new exec 狀態 本次實戰是利用爬蟲爬取鏈家的新房(聲明: 內容僅用於學習交流, 請勿用作商業用途) 環境 win8, python 3.7, pycharm 正文 1. 目標網站分析 通過分析, 找出相關url
Python爬蟲專案--爬取鏈家熱門城市新房
本次實戰是利用爬蟲爬取鏈家的新房(宣告: 內容僅用於學習交流, 請勿用作商業用途) 環境 win8, python 3.7, pycharm 正文 1. 目標網站分析 通過分析, 找出相關url, 確定請求方式, 是否存在js加密等. 2. 新建scrapy專案 1. 在cmd命令列視窗中輸入以
python 學習 - 爬蟲入門練習 爬取鏈家網二手房資訊
import requests from bs4 import BeautifulSoup import sqlite3 conn = sqlite3.connect("test.db") c = conn.cursor() for num in range(1,101): url = "h
43.scrapy爬取鏈家網站二手房信息-1
response ons tro 問題 import xtra dom nts class 首先分析:目的:采集鏈家網站二手房數據1.先分析一下二手房主界面信息,顯示情況如下:url = https://gz.lianjia.com/ershoufang/pg1/顯示
43.scrapy爬取鏈家網站二手房資訊-1
首先分析:目的:採集鏈家網站二手房資料1.先分析一下二手房主介面資訊,顯示情況如下:url = https://gz.lianjia.com/ershoufang/pg1/顯示總資料量為27589套,但是頁面只給返回100頁的資料,每頁30條資料,也就是隻給返回3000條資料。
44.scrapy爬取鏈家網站二手房資訊-2
全面採集二手房資料:網站二手房總資料量為27650條,但有的引數欄位會出現一些問題,因為只給返回100頁資料,具體檢視就需要去細分請求url引數去請求網站資料。我這裡大概的獲取了一下篩選條件引數,一些存在問題也沒做細化處理,大致的採集資料量為21096,實際19794條。看一下執行完成結果: {'d
分享爬取鏈家地圖找房房價資料的小爬蟲
一、說在前面 受人所託,爬取鏈家上地圖找房的資料:https://bj.lianjia.com/ditu/。 上面有按區域劃分的二手房均價和在售套數,我們的任務就是抓下這些資料。 二、開幹 2.1失敗一次 老樣子,Chrome 按下F12開啟Chrome DevTo