
【原始碼】HashMap原始碼剖析
//-----------------------------------------------------------------------------------
轉載需註明出處:http://blog.csdn.net/chdjj
//-----------------------------------------------------------------------------------
注:以下原始碼基於jdk1.7.0_11
public interface Map<K,V> {//Map集合的頂級介面定義 // Query Operations int size(); boolean isEmpty(); boolean containsKey(Object key);//是否包含指定鍵 boolean containsValue(Object value);//是否包含指定值 V get(Object key); // Modification Operations V put(K key, V value); V remove(Object key); // Bulk Operations void putAll(Map<? extends K, ? extends V> m);//批量放置元素 void clear(); // Views //三種檢視 Set<K> keySet();//獲取鍵集 Collection<V> values();//獲取值集 Set<Map.Entry<K, V>> entrySet();//獲取鍵值集合 interface Entry<K,V> {//Map的內部介面,代表一個鍵值對 K getKey();//獲取鍵 V getValue(); //獲取值 V setValue(V value);//設定值 boolean equals(Object o); int hashCode(); } // Comparison and hashing boolean equals(Object o); int hashCode(); }
Map介面定義了Map集合的操作規範,具體實現交由實現類完成,其內部有個介面Entry,代表一個鍵值對. AbstractMap是一個抽象類,其實現了Map介面中的大部分函式。
public abstract class AbstractMap<K,V> implements Map<K,V>下面來看幾個方法:
public boolean containsKey(Object key) {
Iterator<Map.Entry<K,V>> i = entrySet().iterator();//獲得迭代器
if (key==null) {//判斷key是否為空,分別處理
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (e.getKey()==null)//為空的話使用等號判斷
return true;
}
} else {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (key.equals(e.getKey()))//不為空的話使用equals方法判斷
return true;
}
}
return false;
}
public boolean containsValue(Object value) {
Iterator<Entry<K,V>> i = entrySet().iterator();
if (value==null) {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (e.getValue()==null)
return true;
}
} else {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (value.equals(e.getValue()))
return true;
}
}
return false;
}public abstract Set<Entry<K,V>> entrySet();abstractMap並沒有實現put方法,而簡單的丟擲了異常,這要求子類必須複寫此方法:
public V put(K key, V value) {
throw new UnsupportedOperationException();
}但是其卻實現了get方法:
public V get(Object key) {
Iterator<Entry<K,V>> i = entrySet().iterator();
if (key==null) {//依然是根據鍵值是否為null做不同處理
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (e.getKey()==null)
return e.getValue();
}
} else {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (key.equals(e.getKey()))
return e.getValue();
}
}
return null;
}下面來看HashMap。
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, SerializableHashMap繼承了AbstractMap類,並實現了Map介面以及Cloneable、Serializable介面。 其成員變數如下:
static final int DEFAULT_INITIAL_CAPACITY = 16;//預設初始容量
static final int MAXIMUM_CAPACITY = 1 << 30;//最大容量為2的30次方
static final float DEFAULT_LOAD_FACTOR = 0.75f;//預設裝載因子為0.75
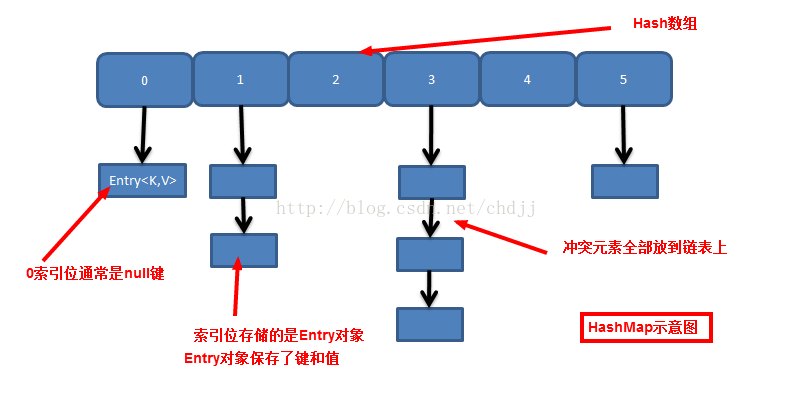
transient Entry<K,V>[] table;//桶陣列,存放鍵值對
transient int size;//實際儲存的鍵值對個數
int threshold;//HashMap的閾值,用於判斷是否需要調整HashMap的容量(threshold = 容量*載入因子)
final float loadFactor;//裝載因子
transient int modCount;//hashmap被改變的次數
static final int ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE;這裡我們得到如下資訊:1.HashMap的預設大小為16,即桶陣列的預設長度為16;2.HashMap的預設裝載因子是0.75;3.HashMap內部的桶陣列儲存的是Entry物件,也就是鍵值對物件。 再看構造器:
public HashMap(int initialCapacity, float loadFactor) {//可手動設定初始容量和裝載因子的構造器
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
//找出“大於initialCapacity”的最小的2的冪
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//初始化桶陣列
table = new Entry[capacity];
useAltHashing = sun.misc.VM.isBooted() &&
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
init();//一個鉤子函式,預設實現是空
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap() {//使用預設的初始容量和預設的載入因子構造HashMap
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(Map<? extends K, ? extends V> m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);
putAllForCreate(m);
}
// internal utilities
void init() {
}需要注意的點: 1.構造器支援指定初始容量和裝載因子,為避免陣列擴容帶來的效能問題,建議根據需求指定初始容量。裝載因子儘量不要修改,0.75是個比較靠譜的值。 2.實際的容量capacity一般情況下是大於我們傳進去的initialCapacity的,因為內部會通過一個迴圈去找到一個比initialCapacity大且為2的整數次冪的一個數作為實際容量。除非傳進去的數恰好為2的整數次方(capacity取2的整數次冪,是為了使不同hash值發生碰撞的概率較小,這樣就能使元素在雜湊表中均勻地雜湊。)。 通過前面的分析,我們知道了HashMap內部通過Entry陣列儲存鍵值對,那麼這個Entry是怎麼實現的呢? 接下來我們看下Entry的實現:
static class Entry<K,V> implements Map.Entry<K,V> {//實現Map.Entry介面
final K key;//鍵,final型別,不可更改/
V value;//值
Entry<K,V> next;//HashMap通過連結串列法解決衝突,這裡的next指向連結串列的下一個元素
int hash;//hash值
/**
* Creates new entry.
*/
//構造器需指定連結串列的下一個結點,所有衝突結點放到一個連結串列上
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
//允許設定value
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
//保證鍵值都相等
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {//鍵為空則hash值為0,否則通過通過hashcode計算
return (key==null ? 0 : key.hashCode()) ^
(value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}需要注意的點: 1.HashMap內部陣列儲存的是鍵值對,也就是Entry物件; 2.Entry物件儲存了鍵、值,並持有一個next指標指向下一個Entry物件(HashMap通過連結串列法解決衝突); 3.Entry可以通過setValue設定值,但不允許設定鍵. 下面我們研究下HashMap中比較重要的方法。從put開始:
public V put(K key, V value) {//向集合中新增一個鍵值對
if (key == null)//如果鍵為空,則呼叫putForNullKey
return putForNullKey(value);
int hash = hash(key);//否則根據key生成一個hash索引值
int i = indexFor(hash, table.length);//在根據索引值找到插入位置
//迴圈遍歷指定位置的Entry連結串列,若找到一個鍵與當前鍵完全一致的Entry,那麼覆蓋原來的鍵所對應的值,並返回原值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//hash值相同且鍵相同
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;//替換原值
e.recordAccess(this);
return oldValue;
}
}
//若沒有找到這樣的鍵,則將當前鍵值插入該位置,並使其位於連結串列頭部.
modCount++;
addEntry(hash, key, value, i);
return null;
}put方法是向hashMap中新增一個鍵值對,這個方法需要注意的有: 1.允許鍵為null。put方法會針對null鍵做相應的處理,呼叫pullforNullKey方法:
private V putForNullKey(V value) {
//空鍵,其hash值為0,必然儲存在陣列的0索引位置上。
//我們需要遍歷0位置的entry連結串列,如果已經有一個null鍵了,那麼也是覆蓋
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
//若沒有,則插入
modCount++;
addEntry(0, null, value, 0);
return null;
}2.不允許兩個鍵相同,如果鍵相同,那麼後插入的鍵所對應的值會覆蓋之前的值。 3.HashMap是通過呼叫hash()方法獲得鍵的hash值,並通過indexFor方法找到實際插入位置,具體程式碼如下:
final int hash(Object k) {//根據鍵生成hash值
int h = 0;
if (useAltHashing) {
if (k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
//根據hash值計算鍵在桶陣列的位置
static int indexFor(int h, int length) {
return h & (length-1);//由put方法可知,這個length就是陣列長度,而且由構造器發現數組長度始終為2的整數次方,那麼這個&操作實際上就是是h%length的高效表示方式,可以使結果小於陣列長度.
}4.put方法通過addEntry方法將鍵值插到合適位置: 5.當容量超過閾值(threshold)時,會發生擴容,擴容後的陣列是原陣列的兩倍。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {//容量超過閾值
resize(2 * table.length);//陣列擴容為原來的兩倍
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];//獲取原來在該位置上的Entry物件
table[bucketIndex] = new Entry<>(hash, key, value, e);//將當前的鍵值插到該位置,並作為連結串列的起始結點。其next指標指向先前的Entry
size++;
}這個resize方法就是擴容方法:
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];//建立新陣列
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
transfer(newTable, rehash);//將原陣列中所有鍵值對轉移至新陣列
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {//需遍歷每個Entry,耗時
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}6.擴容操作需要開闢新陣列,並對原陣列中所有鍵值對重新雜湊,非常耗時。我們應該儘量避免HashMap擴容。 再來看get方法:
public V get(Object key) {
if (key == null)//若鍵為空
return getForNullKey();
Entry<K,V> entry = getEntry(key);//獲取Entry物件
//未找到就返回null,否則返回鍵所對應的值
return null == entry ? null : entry.getValue();
}這個getForNullKey方法就是在陣列0索引位上的連結串列去尋找null鍵:
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}而這個getEntry方法就是通過鍵生成hash值,然後得到其在陣列的索引位,查詢該位置的連結串列,找到第一個滿足的鍵,並返會Entry物件:
final Entry<K,V> getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}再看下remove方法:
public V remove(Object key) {
Entry<K,V> e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
final Entry<K,V> removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key);//先計算hash值
int i = indexFor(hash, table.length);//找到索引位
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
while (e != null) {//遍歷連結串列找到該鍵,並修改連結串列相關指標指向
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}最後看下clear方法:
public void clear() {
modCount++;
Entry[] tab = table;
for (int i = 0; i < tab.length; i++)//遍歷陣列
tab[i] = null;//置空
size = 0;
}4.構造器支援指定初始容量和裝載因子,為避免陣列擴容帶來的效能問題,建議根據需求指定初始容量。裝載因子儘量不要修改,0.75是個比較靠譜的值。 5.桶陣列的長度始終是2的整數次方(大於等於指定的初始容量),這樣做可以減少衝突概率,提高查詢效率。(可以從indexfor函式中看出,h&(length-1),若length為奇數,length-1為偶數那麼h&(length-1)結果的最後一位必然為0,也就是說所有鍵都被雜湊到陣列的偶數下標位置,這樣會浪費近一半空間。另外,length為2的整數次方也保證了h&(length-1)與h%length等效). 6.HashMap接受null鍵; 7.HashMap不允許鍵重複,但是值是可以重複的。若鍵重複,那麼新值會覆蓋舊值。 8.HashMap通過連結串列法解決衝突問題,每個Entry都有一個next指標指向下一個Entry,衝突元素(不是鍵相同,而是hash值相同)會構成一個連結串列。並且最新插入的鍵值對始終位於連結串列首部。 9.當容量超過閾值(threshold)時,會發生擴容,擴容後的陣列是原陣列的兩倍。擴容操作需要開闢新陣列,並對原陣列中所有鍵值對重新雜湊,非常耗時。我們應該儘量避免HashMap擴容。 10.HashMap非執行緒安全。
相關推薦
【原始碼】HashMap原始碼剖析
//----------------------------------------------------------------------------------- 轉載需註明出處:http://blog.csdn.net/chdjj //--------------
【Java】HashMap原始碼分析——基本概念
在JDK1.8後,對HashMap原始碼進行了更改,引入了紅黑樹。 在這之前,HashMap實際上就是就是陣列+連結串列的結構,由於HashMap是一張雜湊表,其會產生雜湊衝突,為了解決雜湊衝突,HashMap採用了開鏈法,即對於用物件hashCode值計算雜湊
【Java】HashMap原始碼分析——常用方法詳解
上一篇介紹了HashMap的基本概念,這一篇著重介紹HasHMap中的一些常用方法:put()get()**resize()** 首先介紹resize()這個方法,在我看來這是HashMap中一個非常重要的方法,是用來調整HashMap中table的容量的,在很多操作中多需要重新計算容量。原始碼如下: 1
【JDK8】HashMap集合 原始碼閱讀
JDK8的HashMap資料結構上覆雜了很多,因此讀取效率得以大大提升,關於原始碼中紅黑樹的增刪改查,博主沒有細讀,會在下一篇博文中使用Java實現紅黑樹的增刪改查。 下面是類的結構圖: 程
JDK1.7原始碼分析【集合】HashMap的死迴圈
前言 在JDK1.7&1.8原始碼對比分析【集合】HashMap中我們遺留了一個問題:為什麼HashMap在呼叫resize() 方法時會出現死迴圈?這篇文章就通過JDK1.7的原始碼來分析並解釋這個問題。 如下,併發場景下使用HashMap造成Race Condition
【原創】從原始碼剖析IO流(四)管道流--轉載請註明出處
一、管道流的特點與作用: PipedInputStream與PipedOutputStream分別為管道輸入流和管道輸出流。管道輸入流通過連線到管道輸出流實現了類似管道的功能,用於執行緒之間的通訊。在使用時,通常由某個執行緒向管道輸出流中寫入資料。根據管道的特性,這些資料會自動傳送到與管道輸
【原創】從原始碼剖析IO流(三)快取流--轉載請註明出處
一、BufferedInputStream 關於BufferedInputStream,首先我們要看一下,官方給予的對於BufferedInputStream這個類的備註: /** * A <code>BufferedInputStream</code> add
【原創】從原始碼剖析IO流(一)輸入流與輸出流--轉載請註明出處
InputStream與OutPutStream兩個抽象類,是所有的流的基礎,首先來看這兩個流的API InputStream: public abstract int read() throws IOException; 從輸入流中讀取資料的下個位元組
【原創】從原始碼剖析IO流(二)檔案流--轉載請註明出處
一、FileInputStream 在FileInputStream中,首先我們需要進行關注的方法,就是read()方法,下面可以來看一下read()方法的原始碼: public int read() throws IOException { return read0()
【原始碼】Hashtable原始碼剖析
注:以下原始碼基於jdk1.7.0_11 上一篇分析了HashMap的原始碼,相信大家對HashMap都有了更深入的理解。本文將介紹Map集合的另一個常用類,Hashtable。 Hashtable出來的比HashMap早,HashMap 1.2才有,而Hashtable
【集合詳解】HashMap原始碼解析
一、HashMap概述 二、HashMap的資料結構 三、HashMap原始碼分析 1.繼承 2、關鍵屬
【筆記】ThreadPoolExecutor原始碼閱讀(三)
執行緒數量的維護 執行緒池的大小有兩個重要的引數,一個是corePoolSize(核心執行緒池大小),另一個是maximumPoolSize(最大執行緒大小)。執行緒池主要根據這兩個引數對執行緒池中執行緒的數量進行維護。 需要注意的是,執行緒池建立之初是沒有任何可用執行緒的。只有在有任務到達後,才開始建立
【Android】Retrofit原始碼分析
Retrofit簡介 retrofit n. 式樣翻新,花樣翻新 vt. 給機器裝置裝配(新部件),翻新,改型 Retrofit 是一個 RESTful 的 HTTP 網路請求框架的封裝。注意這裡並沒有說它是網路請求框架,主要原因在於網路請求的工作並不是 Retrofit
【Android】OkHttp原始碼分析
Android為我們提供了兩種HTTP互動的方式:HttpURLConnection 和 Apache HttpClient,雖然兩者都支援HTTPS,流的上傳和下載,配置超時,IPv6和連線池,已足夠滿足我們各種HTTP請求的需求。但更高效的使用HTTP 可以讓您的應用執行更快、更節省
【NLP】【三】jieba原始碼分析之關鍵字提取(TF-IDF/TextRank)
【一】綜述 利用jieba進行關鍵字提取時,有兩種介面。一個基於TF-IDF演算法,一個基於TextRank演算法。TF-IDF演算法,完全基於詞頻統計來計算詞的權重,然後排序,在返回TopK個詞作為關鍵字。TextRank相對於TF-IDF,基本思路一致,也是基於統計的思想,只不過其計算詞的權
【NLP】【二】jieba原始碼分析之分詞
【一】詞典載入 利用jieba進行分詞時,jieba會自動載入詞典,這裡jieba使用python中的字典資料結構進行字典資料的儲存,其中key為word,value為frequency即詞頻。 1. jieba中的詞典如下: jieba/dict.txt X光 3 n X光線 3
【NLP】【四】jieba原始碼分析之詞性標註
【一】詞性標註 詞性標註分為2部分,首先是分詞,然後基於分詞結果做詞性標註。 【二】jieba的詞性標註程式碼流程詳解 1. 程式碼位置 jieba/posseg/_init_.py 2. 流程分析 def cut(sentence, HMM=True): """
【NLP】【七】fasttext原始碼解析
【一】關於fasttext fasttext是Facebook開源的一個工具包,用於詞向量訓練和文字分類。該工具包使用C++11編寫,全部使用C++11 STL(這裡主要是thread庫),不依賴任何第三方庫。具體使用方法見:https://fasttext.cc/ ,在Linux 使用非常方便
【8】netty4原始碼分析-flush
轉自 http://xw-z1985.iteye.com/blog/1971904 Netty的寫操作由兩個步驟組成: Write:將msg儲存到ChannelOutboundBuffer中 Flush:將msg從ChannelOutboundBuffer中flush到套接字的傳送緩
【7】netty4原始碼分析-write
轉自 http://xw-z1985.iteye.com/blog/1970844 Netty的寫操作由兩個步驟組成: Write:將msg儲存到ChannelOutboundBuffer中 Flush:將msg從ChannelOutboundBuffer中flush到套接字的傳送緩