
機器學習(四)--- 從gbdt到xgboost
gbdt(又稱Gradient Boosted Decision Tree/Grdient Boosted Regression Tree),是一種迭代的決策樹演算法,該演算法由多個決策樹組成。它最早見於yahoo,後被廣泛應用在搜尋排序、點選率預估上。
xgboost是陳天奇大牛新開發的Boosting庫。它是一個大規模、分散式的通用Gradient Boosting(GBDT)庫,它在Gradient Boosting框架下實現了GBDT和一些廣義的線性機器學習演算法。
本文首先講解了gbdt的原理,分析了程式碼實現;隨後分析了xgboost的原理和實現邏輯。本文的目錄如下:
一、GBDT
1. GBDT簡介
2. GBDT公式推導
3. 優缺點
4. 實現分析
5. 常用引數和調優
二、Xgboost
1. Xgboost簡介
2. Xgboost公式推導
3. 優缺點
4. 實現分析
5. 常用引數和調優
一、GBDT/GBRT
1. GBDT簡介
GBDT是一個基於迭代累加的決策樹演算法,它通過構造一組弱的學習器(樹),並把多顆決策樹的結果累加起來作為最終的預測輸出。
樹模型也分為決策樹和迴歸樹,決策樹常用來分類問題,迴歸樹常用來預測問題。決策樹常用於分類標籤值,比如使用者性別、網頁是否是垃圾頁面、使用者是不是作弊;而回歸樹常用於預測真實數值,比如使用者的年齡、使用者點選的概率、網頁相關程度等等。由於GBDT的核心在與累加所有樹的結果作為最終結果,而分類結果對於預測分類並不是這麼的容易疊加(稍等後面會看到,其實並不是簡單的疊加,而是每一步每一棵樹擬合的殘差和選擇分裂點評價方式都是經過公式推導得到的),所以GBDT中的樹都是迴歸樹(其實迴歸樹也能用來做分類的哈)。同樣的我們經常會把RandomForest的思想引入到GBDT裡面來,即每棵樹建樹的時候我們會對特徵和樣本同時進行取樣,然後對取樣的樣本和特徵進行建樹。
好啦,既然每棵樹擬合的值、預測值、分裂點選取都不是隨便選取的,那麼到底是如何選擇的呢?我們先進入GBDT的公式推導吧
2. GBDT公式推導
我們都知道LR的對映函式是,損失函式是

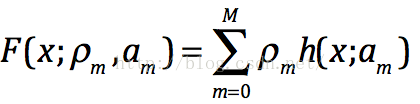
那麼它的目標函式就如下,其中如上公式中是第m顆樹的預測值---梯度方向。我們可以在函式空間上形式使用梯度下降法求解,首先固定x,對F(x)求其最優解。下面給出框架流程和Logloss下的推導,框架流程如下:
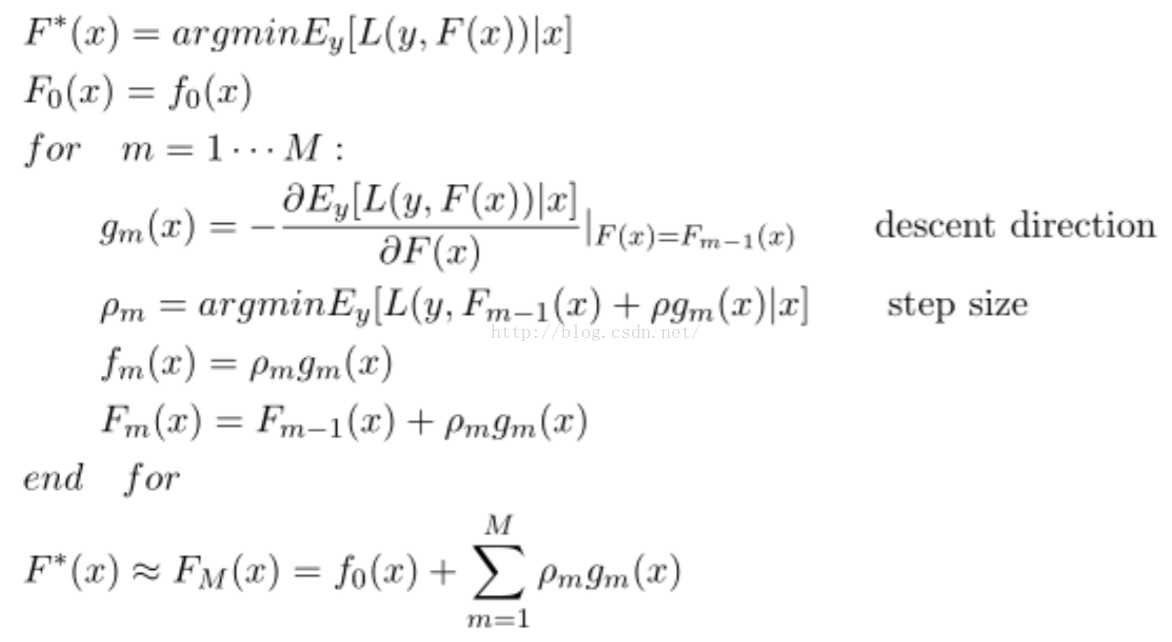
我們需要估計g_m(x),這裡使用決策樹實現去逼近g_m(x),使得兩者之間的距離儘可能的近。而距離的衡量方式有很多種,比如均方誤差和Logloss誤差。我在這裡給出Logloss損失函式下的具體推導:
(GBDT預測值到輸出概率[0,1]的sigmoid轉換)
下面,我們需要首先求解F0,然後再求解每個梯度。
Step 1. 首先求解初始值F0,令其偏導為0。(實現時是第1顆樹需要擬合的殘差)
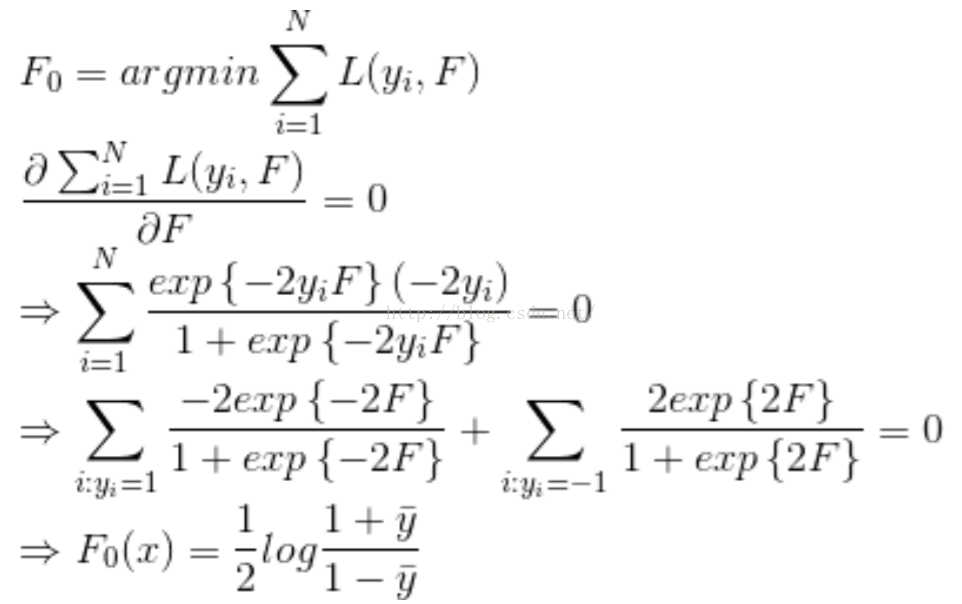
Step2. 估計g_m(x),並用決策樹對其進行擬合。g_m(x)是梯度,實現時是第m顆樹需要擬合的殘差:
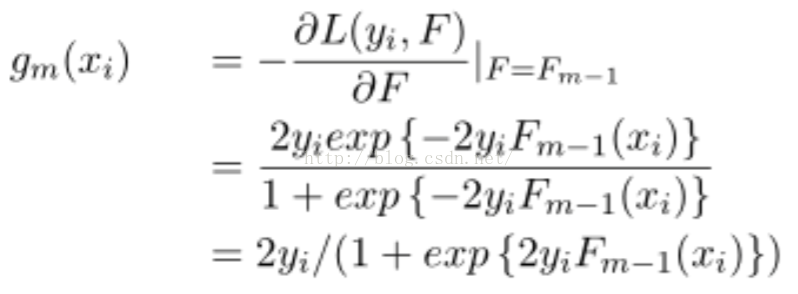
Step3. 使用牛頓法求解下降方向步長。r_jm是擬合的步長,實現時是每棵樹的預測值:
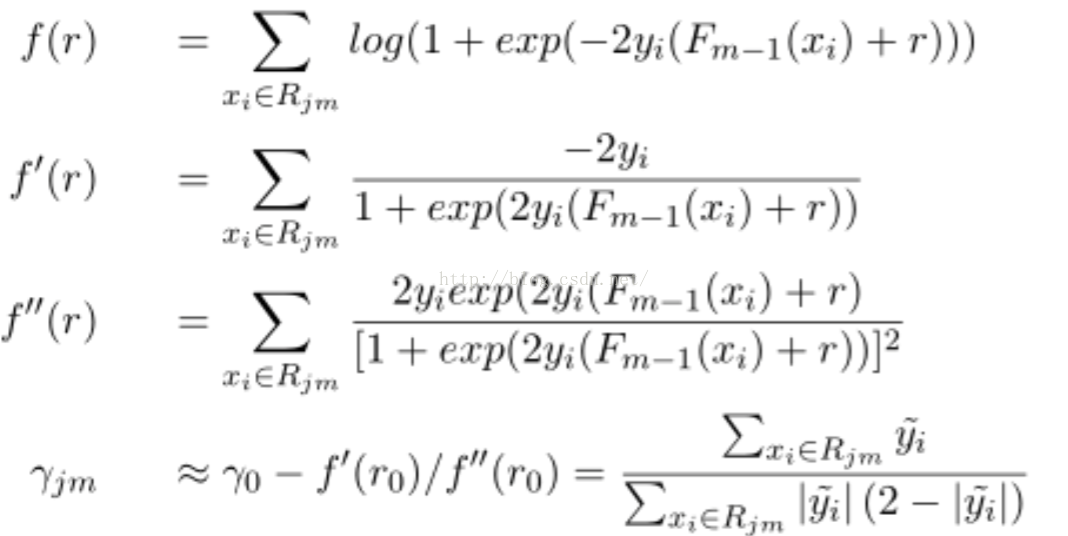
Step4. 預測時就很簡單啦,把每棵樹的預測值乘以縮放因子加到一起就得到預測值啦:
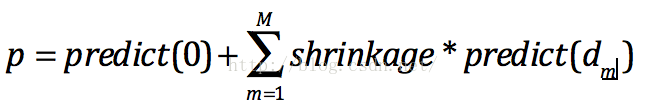
注意如果需要輸出的區間在(0,1)之間,我們還需要做如下轉換:
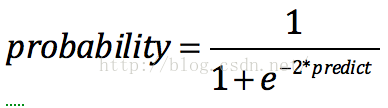
3. 優缺點
GBDT的優點當然很明顯啦,它的非線性變換比較多,表達能力強,而且不需要做複雜的特徵工程和特徵變換。
GBDT的缺點也很明顯,Boost是一個序列過程,不好並行化,而且計算複雜度高,同時不太適合高維洗漱特徵。
4. 實現分析
5. 引數和模型調優
GBDT常用的引數有如下幾個:
1. 樹個數
2. 樹深度
3. 縮放因子
4. 損失函式
5. 資料取樣比
6. 特徵取樣比
二、Xgboost
xgboost是boosting Tree的一個很牛的實現,它在最近Kaggle比賽中大放異彩。它 有以下幾個優良的特性:
1. 顯示的把樹模型複雜度作為正則項加到優化目標中。
2. 公式推導中用到了二階導數,用了二階泰勒展開。(GBDT用牛頓法貌似也是二階資訊)
3. 實現了分裂點尋找近似演算法。
4. 利用了特徵的稀疏性。
5. 資料事先排序並且以block形式儲存,有利於平行計算。
6. 基於分散式通訊框架rabit,可以執行在MPI和yarn上。(最新已經不基於rabit了)
7. 實現做了面向體系結構的優化,針對cache和記憶體做了效能優化。
在專案實測中使用發現,Xgboost的訓練速度要遠遠快於傳統的GBDT實現,10倍量級。
1. 原理
在有監督學習中,我們通常會構造一個目標函式和一個預測函式,使用訓練樣本對目標函式最小化學習到相關的引數,然後用預測函式和訓練樣本得到的引數來對未知的樣本進行分類的標註或者數值的預測。一般目標函式是如下形式的,我們通過對目標函式最小化,求解模型引數。預測函式、損失函式、正則化因子在不同模型下是各不相同的。

其中預測函式有如下幾種形式:
1. 普通預測函式
a. 線性下我們的預測函式為:
b. 邏輯迴歸下我們的預測函式為:
2. 損失函式:
a. 平方損失函式:
b. Logistic損失函式:
3. 正則化:
a. L1 引數求和
b. L2 引數平方求和
其實我個人感覺Boosting Tree的求解方式和以上略有不同,Boosting Tree由於是迴歸樹,一般是構造樹來擬合殘差,而不是最小化損失函式。且看GBDT情況下我們的預測函式為:
而Xgboost引入了二階導來進行求解,並且引入了節點的數目、引數的L2正則來評估模型的複雜度。那麼Xgboost是如何構造和預測的呢?
首先我們給出結果,Xgboost的預測函式為:
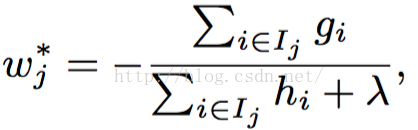
而目標函式為:
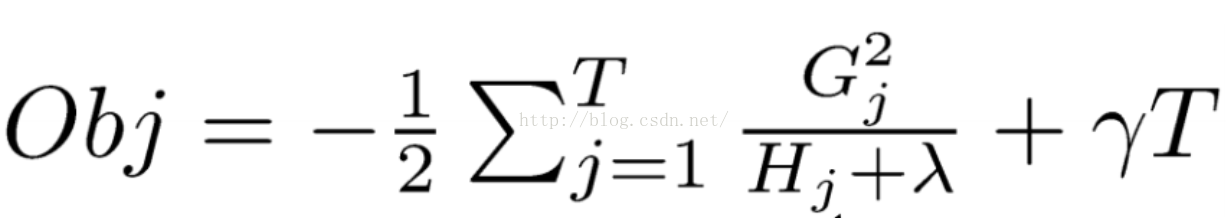
那麼作者是如何構思得到這些預測函式和優化目標的呢?它們又如何求解得到的呢? 答案是作者巧妙的利用了泰勒二階展開和巧妙的定義了正則項,用求解到的數值作為樹的預測值。

我們定義正則化項:
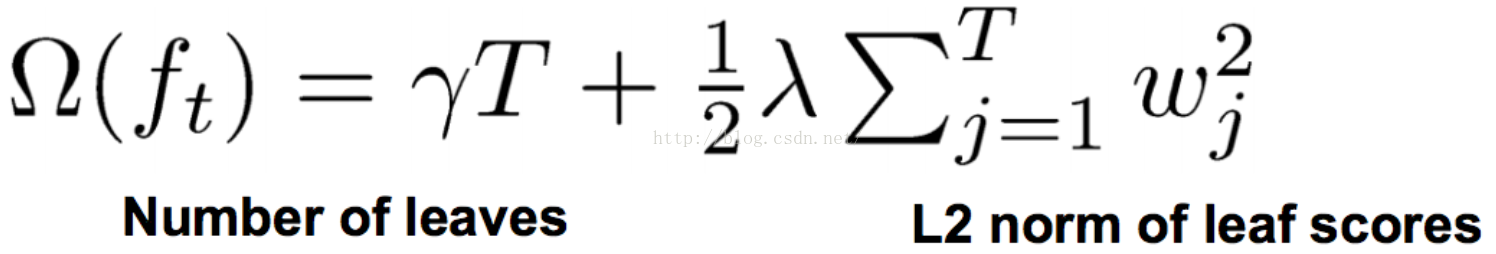
可以得到目標函式轉化為:
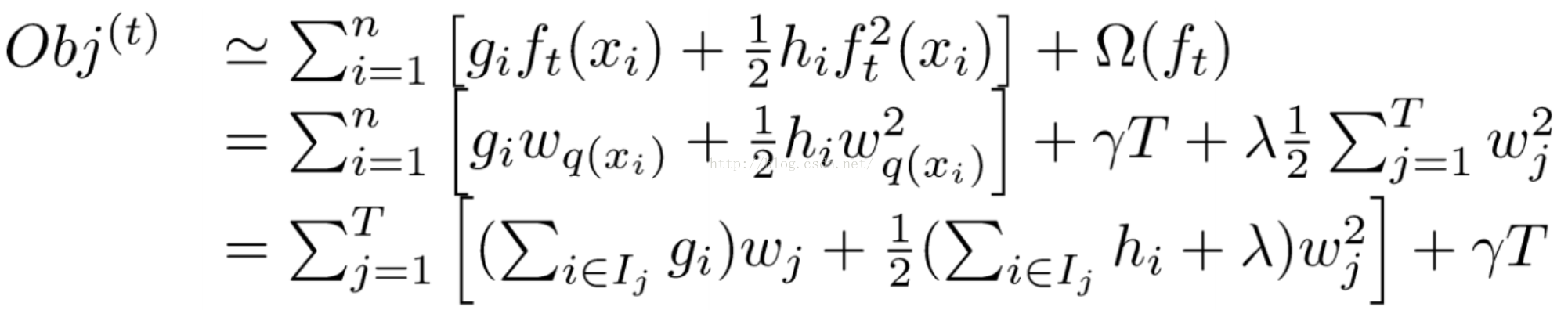
然後就可以求解得到:

同樣在分裂點選擇的時候也,以目標函式最小化為目標。
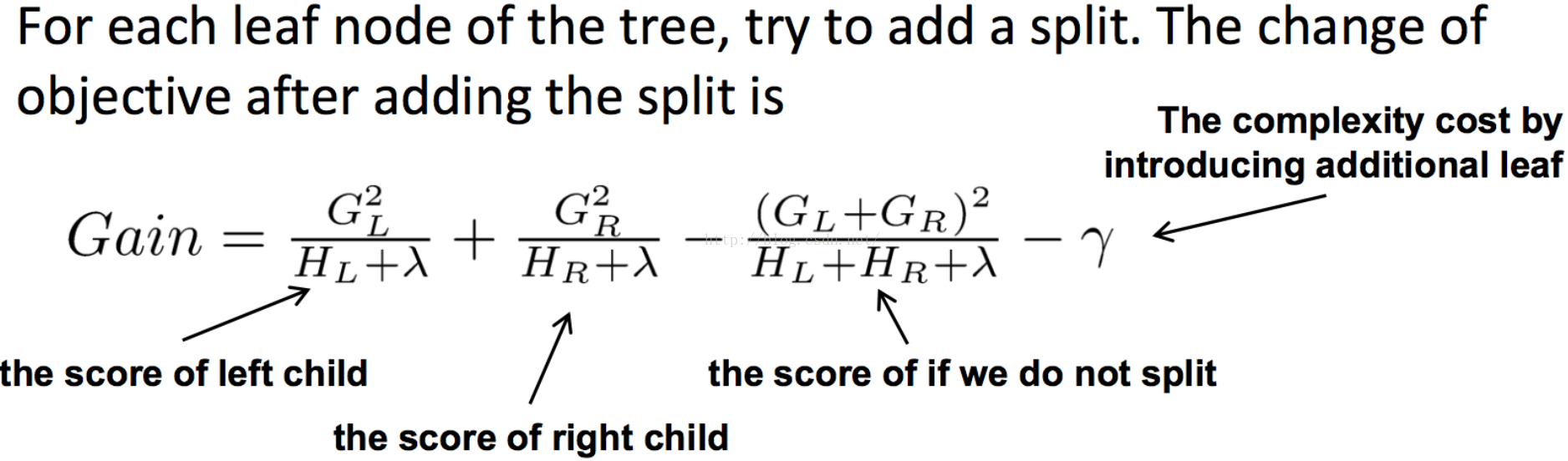
2. 實現分析:
3. 引數調優:
a. 初階引數調優:
1). booster
2). objective
3). eta
4). gamma
5). min_child_weight
6). max_depth
7). colsample_bytree
8). subsample
9). num_round
10). save_period
參考文獻:
1. xgboost導讀和實踐:http://vdisk.weibo.com/s/vlQWp3erG2yo/1431658679
2. GBDT(MART) 迭代決策樹入門教程: http://blog.csdn.net/w28971023/article/details/8240756
3. Introduction to Boosted Trees : https://homes.cs.washington.edu/~tqchen/pdf/BoostedTree.pdf
4. xgboost: https://github.com/dmlc/xgboost
相關推薦
機器學習(四)--- 從gbdt到xgboost
gbdt(又稱Gradient Boosted Decision Tree/Grdient Boosted Regression Tree),是一種迭代的決策樹演算法,該演算法由多個決策樹組成。它最早見於yahoo,後被廣泛應用在搜尋排序、點選率預估上。
機器學習(四)—邏輯回歸LR
-s 劃分 也有 進行 完美 特征處理 tin 向量 進一步 1、關於模型在各個維度進行不均勻伸縮後,最優解與原來等價嗎? 答:等不等價要看最終的誤差優化函數。如果經過變化後最終的優化函數等價則等價。明白了這一點,那麽很容易得到,如果對原來的特征乘除某一常數,則等價。
機器學習(四) 機器學習與深度學習的實際應用整理
前言 本文主要是整理備份機器學習與深度學習的實際應用,儘量給出原始作者網站,包括論文、程式碼和github等原始資料。共勉! 實際應用 基於深度神經網路的免費開源的人臉識別系統 openface已經到了0.2.1了,備份一個基
演算法工程師修仙之路:吳恩達機器學習(四)
吳恩達機器學習筆記及作業程式碼實現中文版 第四章 Logistic迴歸 分類 在分類問題中,要預測的變數y是離散的值,邏輯迴歸 (Logistic Regression) 演算法是目前最流行使用最廣泛的一種學習演算法。 在分類問題中,我們嘗試預測的是結果
機器學習(四)邏輯迴歸模型訓練
本篇不講演算法 只講用Python (pandas, matplotlib, numpy, sklearn) 進行訓練的一些要點 1.合併index np.concatenate([index1,index2]) 2.from sklearn.cross_va
Python教程:進擊機器學習(四)--Matplotlib
介紹 Matplotlib是Python庫中最經常用來繪製圖的,它可以快速的視覺化你的資料,並且匯出不同的格式。用Matplotlib繪製的圖可以達到出版書籍和論文的質量要求。我們開始探索在處理一些常見的資料時應用Matplotlib。 pyplo
機器學習(四):BP神經網路_手寫數字識別_Python
機器學習演算法Python實現 三、BP神經網路 全部程式碼 1、神經網路model 先介紹個三層的神經網路,如下圖所示 輸入層(input layer)有三個units(為
機器學習(四)——Adaboost演算法
一,Boosting演算法概論 boosting是一族可將弱學習器提升為強學習器的演算法。booting中所使用的多個分類器的型別都是一致的,並且不同分類器是通過序列訓練而獲得的,每個新分類器都根據已訓練出的分類器的效能進行訓練。Boosting是通過集中關注被已有分類器錯分的那些資料來獲得新的
機器學習(四)——最小二乘(Least squares)
藉助舉證導數的工具,現在讓我們繼續以封閉的形式找到θ的值,使得J(θ)最小化。我們從用矩陣向量表示法重寫J開始。給定一個訓練集,設計矩陣X為mxn矩陣,(實際上是mx(n+1),如果我們包括攔截項),其中每一行為訓練樣本的輸入值:另外,讓是包含訓練集中所有目標值的m維向量:現
Python與機器學習(四)決策樹
1.決策樹概念: 決策樹經常用於處理分類問題,也是最經常使用的資料探勘演算法。決策樹的一個重要任務是為了資料中所蘊含的知識資訊,並從中提取一系列的規則,而建立這些規則的過程就是機器學習的過程。例如一個典型例子就是根據天氣情況分類星期天是否適合打球。 如果星期天的天氣是晴天
機器學習與深度學習系列連載: 第一部分 機器學習(四)誤差分析(Bias and Variance)和模型調優
1.誤差分析(Bias and Variance) 當我們以非常複雜的模型去進行測試的時候,可能得到的結果並不理想 影響結果的主要有兩個因素:Bias 偏差、Variance 方差 Bias 偏差 在這裡,我們定義偏差是指與目標結果的偏移量,這個偏
前置機器學習(四):一文掌握Pandas用法
> Pandas提供快速,靈活和富於表現力的**資料結構**,是強大的**資料分析**Python庫。 本文收錄於[機器學習前置教程系列](https://mp.weixin.qq.com/mp/appmsgalbum?action=getalbum&__biz=MzUxMjU4NjI4MQ=
機器學習(五)--- FTRL一路走來,從LR -> SGD -> TG -> FOBOS -> RDA -> FTRL
本文會嘗試總結FTRL的發展由來,總結從LR -> SGD -> TG -> FOBOS -> RDA -> FTRL 的發展歷程。本文的主要目錄如下: 一、 反思魏則西事件。 二、 LR模型 三、 SG
機器學習(ML)十四之凸優化
優化與深度學習 優化與估計 儘管優化方法可以最小化深度學習中的損失函式值,但本質上優化方法達到的目標與深度學習的目標並不相同。 優化方法目標:訓練集損失函式值 深度學習目標:測試集損失函式值(泛化性) 1 %matplotlib inline 2 import sys 3 im
Python基礎學習(四)
python 函數 集合 Python 集合: set 顧明思義,就是個集合,集合的元素是唯一的,無序的。一個{ }裏面放一些元素就構成了一個集合,set裏面可以是多種數據類型(但不能是列表,集合,字典,可以是元組) 它可以對列表裏面的重復元素進行去重list1 = [1,2,3,23
爬蟲庫之BeautifulSoup學習(四)
所有 字符串 判斷 href gin int 過濾器 amp link 探索文檔樹: find_all(name,attrs,recursive,text,**kwargs) 方法搜索當前tag的所有tag子節點,並判斷是否符合過濾器的條件 1、name參數,可
java學習(四)代碼的設計
方法 聯系 string 封裝 代碼 his 站點 add 團隊 一、目的 1、為了使程序員編寫的代碼更加的簡潔,使人閱讀起來更加流暢 2、將運算代碼與界面代碼完全分離開來,利於團隊開發,提高團隊之間的工作效率 3、 在很短的時間內可以替換整個站點的外觀; 4、使程
Linux基礎學習(四)
ubuntu pad 檢查 rom run 文件和目錄 mis fdisk 內存 十一、 系統監控 11.1 系統監視和進程控制工具 11.1.1 top 1) top命令的功能:top命令是Linux下常用的性能分析工具,能夠實時顯示系統中各個進程的資源占用狀況,類似於
java學習(四)static靜態變量 和this
java學習 方便 private setname 局部變量 變量 告訴 應該 size java中的this /* this:是當前類的對象引用。簡單的記,它就代表當前類的一個對象。 註意:誰調用這個方法,在該方法內部的this就代表誰
java源碼學習(四)ArrayList
mem mov elements fail ren pac runt 語義 tran ArrayList ? ArrayList是基於數組實現的,是一個動態數組,其容量能自動增長,類似於C語言中的動態申請內存,動態增長內存。 ? ArrayList不是線程安全的,只能用在單