
機器學習(四)——Adaboost演算法
一,Boosting演算法概論
boosting是一族可將弱學習器提升為強學習器的演算法。booting中所使用的多個分類器的型別都是一致的,並且不同分類器是通過序列訓練而獲得的,每個新分類器都根據已訓練出的分類器的效能進行訓練。Boosting是通過集中關注被已有分類器錯分的那些資料來獲得新的分類器。boosting分類的結果是基於所有分類器的加權求和結果的,因此boosting中的分類器權重並不相等,每個權重代表的是對應分類器在上一輪迭代中的成功度。boosting演算法通過分佈迭代(stage-wise)的方式來構建模型,在迭代的每一步中構建的弱分類器都是為了彌補已有模型的不足。(個體學習器之間存在強依賴關係)
樣本加權的過程如下:

上圖中被放大的點是被加權的樣本,樣本加權後,在下一次的學習中就會收到更多的關注。也就是說,boosting演算法對分類錯誤的樣本更加關注,通過改變分類錯誤樣本的權重來改變下一個弱分類器的分類邊界,從而一步步提升分類演算法的準確度。
boosting演算法擁有多個版本,其中Adaboost演算法是其中最流行的版本。
二、Adaboost演算法概述
Adaboost是adaptive boosting(自適應boosting)的縮寫,其執行過程如下:訓練資料中的每一個樣本,賦予一個權重,這些權重構成了向量D。一開始,這些權重都初始化為相等值。首先在訓練資料上訓練出一個弱分類器並計算該分類器的錯誤率,然後再同一個資料集上再次訓練弱分類器,在分類器的第二次訓練當中,將會重新調整每個樣本的權值,其中,第一次分對的樣本的權重將會降低,分錯樣本的權重將會提高。為了從所有弱分類器中得到最終的分類結果,adaboost為每個分類器都分配一個權重值alpha,這些alpha值是基於每個弱分類器的錯誤率進行計算的,其中錯誤率是:

加權後的錯誤率是:

alpha的計算公式:
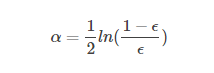
計算出alpha值之後,就可以對權重向量D進行更新,以使得那些正確分類的樣本的權重降低而錯分樣本的權重升高。
如果某個樣本被正確分類,那麼該樣本的權重更改為:
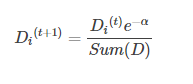
如果某個樣本被錯分,那麼該樣本的權重更改為:

綜合起來就是:
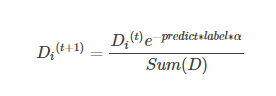
在計算出D之後,Adaboost有開始進入下一輪的迭代。Adaboost演算法會不斷地重複訓練和調整權重的過程,直到錯誤率為0或者弱分類器的數目達到使用者的指定值為止。
關於adaboost中的兩種權重
adaboost演算法中有兩種權重,一種是資料的權重,另一種是弱分類器的權重。其中,資料的權重主要用於弱分類器尋找分類誤差最小的決策點,找到之後用這個最小誤差計算出弱分類器的權重,分類器的權重越大說明該弱分類器在最終決策時有更大的發言權。
資料的權重:如果訓練資料保持不變,那麼弱分類器每次找到的最佳決策點都是一樣的。這時候,資料的權重就派上用場了,資料的權重主要用於弱分類器尋找其分類誤差最小的點。舉個例子,在以前沒有權重時,一共是十個點,對應每個點的權重都是0.1,分錯一個錯誤率就是0.1;分錯三個,錯誤率就是0.3。現在,每個點的權重不一樣了,分別為【0.01,0.01,0.01,0.01,0.01,0.01, 0.01,0.01,0.01,0.91】,如果分錯分錯第一個點,錯誤率就是0.01。如果分錯第三個點,錯誤率是0.01。,要是如果分錯最後一個點時,錯誤率就是0.91。這樣一來在選擇決策點時就會把權重大 的點分對才能降低誤差率。由此可見,權重大的點得到更多的關注,權重小的點得到更少的關注。
圖示說明Adaboost過程:

圖中,“+”和“-”分別表示兩個類別,在這個過程中,使用水平或者垂直的直線作為分類器來進行分類。
第一步:

根據分類的正確率,得到一個新的樣本分佈D2,一個子分類器h1。
其中畫圈的是被分錯的,分錯的樣本會增大權重。
第二步:

根據分類的正確率,得到一個新的樣本分佈D3,一個子分類器h2。
第三步:

得到第三個子分類器h3
整合所有子分類器:

從結果可以看出,即使是簡單的弱分類器,組合起來可以獲得很好的分類效果。
sklearn類庫中的Adaboost應用:
class sklearn.ensemble.AdaBoostRegressor(base_estimator=None, n_estimators=50, learning_rate=1.0, algorithm=’SAMME.R’, random_state=None)
class sklearn.ensemble.AdaBoostRegressor(base_entimator=None, n_estimators=50, learning_rate=1.0, loss="linear", random_state=None)
引數:
(1)base_estimator:即弱分類學習器理論上可以選擇任何一個分類器,不過需要支援樣本權重。我們常用的一般是CART決策樹或者神經網路MLP。預設是決策樹,即AdaBoostClassifier預設使用CART分類樹DecisionTreeClassifier,而AdaBoostRegressor預設使用CART迴歸樹DecisionTreeRegressor。
(2)algorithm:這個引數只有在AdaBoostClassifier中有。主要原因是scikit-learn實現了兩種Adaboost分類演算法,SAMME和SAMME.R。兩者的主要區別是弱分類器權重的度量。SAMME使用了樣本集分類效果作為弱分類器的權重,即誤差率得到的權重;而SAMME.R使用了對樣本集分類的預測概率大小作為權重。由於SAMME.R使用了概率度量的連續值,迭代一般比SAMME快,因此AdaBoostClassifier的預設演算法algorithm的值是SAMME.R。但是注意的是使用了SAMME.R後,弱分類器引數base_estimator必須限制使用支援概率預測的分類器。而SAMME演算法則沒有這個限制。
(3)n_estimators:兩者都有,就是我們弱分類器的最大迭代次數,或者最大的弱學習器的個數。一般來說n_eatimators太小,容易欠擬合,太大又容易過擬合,預設是50.在實際調參過程中,我們常常將n_eatimators和learning_rate一起考慮。
(4)learning_rate:兩者都有,即每個弱學習器的權重縮減係數。
主要方法:
(1)fit(x,y): 從訓練集中建立一個提升分類器
(2)get_params():得到模型的引數
(3)predict(x):預測
(4)score(x,y):驗證集上驗證演算法的精度
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import load_iris
from sklearn import model_selection
#import matplotlib.pyplot as plt
iris = load_iris()
x_train,x_test,y_train,y_test = model_selection.train_test_split(iris.data,
iris.target,test_size=0.2,random_state=0)
abc = AdaBoostClassifier(n_estimators=100)
abc.fit(x_train,y_train)
abc.score(x_test,y_test)0.90000000000000002
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import load_iris
from sklearn import model_selection
from sklearn.tree import DecisionTreeClassifier
#import matplotlib.pyplot as plt
iris = load_iris()
x_train,x_test,y_train,y_test = model_selection.train_test_split(iris.data,
iris.target,test_size=0.2,random_state=0)
abc = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2,min_samples_split=20,
min_samples_leaf=5),
n_estimators=100)
abc.fit(x_train,y_train)
abc.score(x_test,y_test)1.0(震驚臉-_-)
參考:https://blog.csdn.net/zwqjoy/article/details/80424783
http://www.cnblogs.com/pinard/p/6136914.html
![]()
![]()