
SCALA_IDE開發Spark程式
IDEA Eclipse
下載scala
下載地址
scala.msi
scala環境變數配置
(1)設定SCALA-HOME變數:如圖,單擊新建,在變數名一欄輸入: SCALA-HOME 變數值一欄輸入: D:\Program Files\scala 也就是scala的安裝目錄,根據個人情況有所不同,如果安裝在E盤,將“D”改成“E”即可。
(2)設定path變數:找到系統變數下的“path”如圖,單擊編輯。在“變數值”一欄的最前面新增如下的 code: %scala_Home%\bin;%scala_Home%\jre\bin; 注意:後面的分號 ; 不要漏掉。
(3)設定classpath變數:找到找到系統變數下的“classpath”如圖,單擊編輯,如沒有,則單擊“新建”,
“變數名”:ClassPath “變數值“:
.;%scala_Home%\bin;%scala_Home%\lib\dt.jar;%scala_Home%\lib\tools.jar.; 注意:“變數值”最前面的 .; 不要漏掉。最後單擊確定即可。
下載scala ide,scal-SDK-4.4.1-vfinal-2.11-win32.win32.x86.64.zip
下載地址
下載後解壓,點選Eclipse,執行
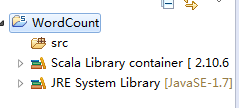
第一步:修改依賴的Scala版本為Scala 2.10.x(預設2.11.7,要做修改)

第二步:加入Spark 1.6.0的jar檔案依賴
下載spark對應的jar包,點選4,下載spark-1.6.1-bin-hadoop2.6.tgz
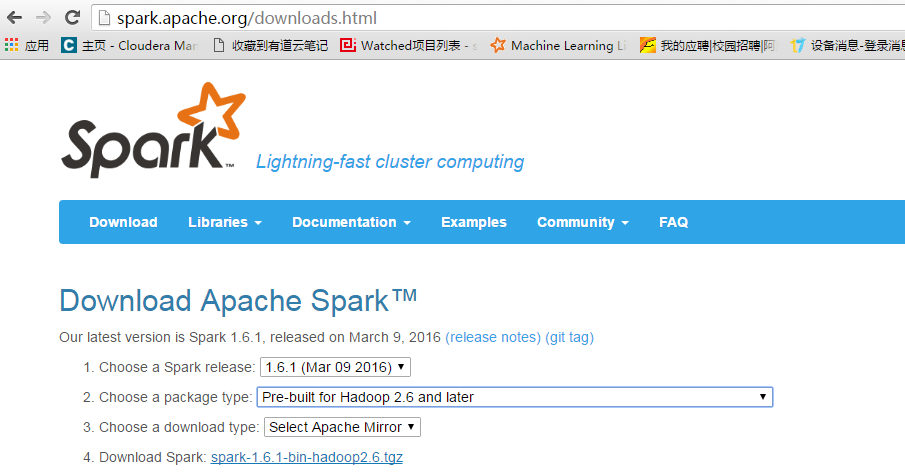
下載地址

下載Spark,在lib中找到依賴檔案
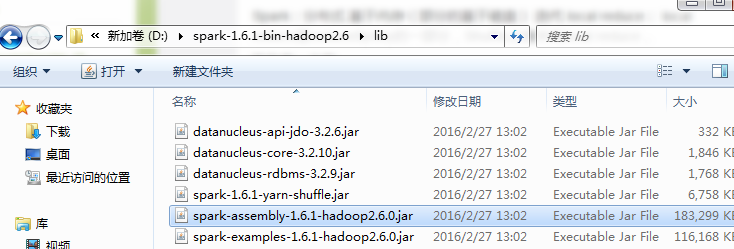
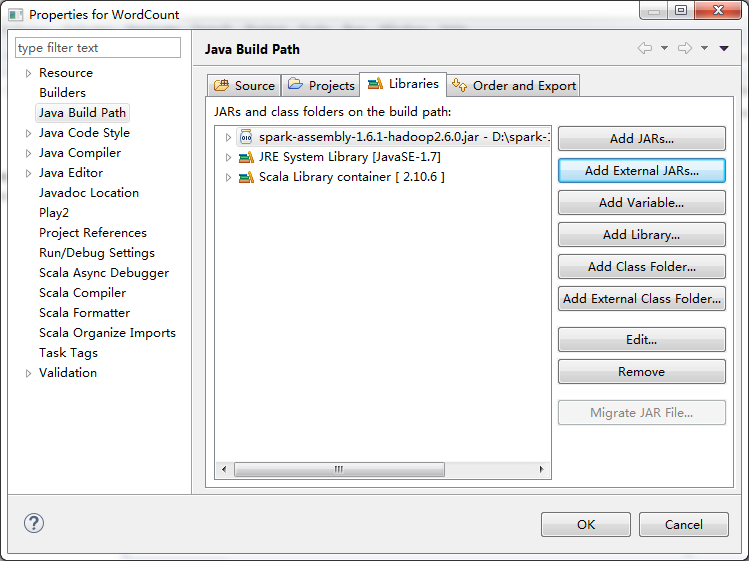
第三步:找到依賴的Spark Jar檔案並匯入到Eclipse中的Jar依賴
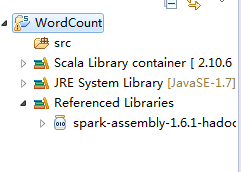
第四步:在src下建立Spark工程包
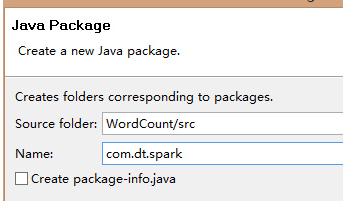
第五步:建立Scala入口類
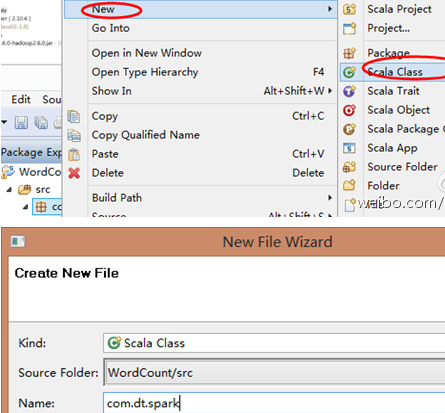
第六步:把class變成object並編寫main入口方法

開發程式有兩種模式:本地執行和叢集執行
修改字型
本地模式
package com.test
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object WordCount {
def main(args: Array[String]){
/**
* 第一步:建立Spark的配置物件SparkConf,設定Spark程式的執行時的配置資訊,
* 例如說通過setMaster來設定程式要連線的Spark叢集的Master的URL,
* 如果設定為local,則代表Spark程式在本地執行,特別適合於機器配置條件非常差
* (例如只有1G的記憶體)的初學者
*/ run as ->Scala Application
執行結果
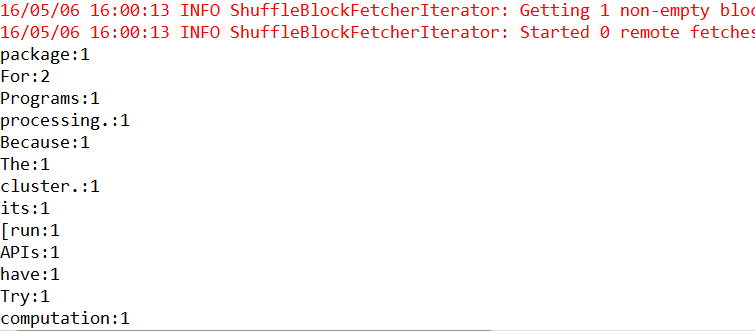
叢集模式
package com.test
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
object WordCountCluster {
def main(args: Array[String]){
/**
* 第一步:建立Spark的配置物件SparkConf,設定Spark程式的執行時的配置資訊,
* 例如說通過setMaster來設定程式要連線的Spark叢集的Master的URL,
* 如果設定為local,則代表Spark程式在本地執行,特別適合於機器配置條件非常差
* (例如只有1G的記憶體)的初學者
*/
val conf =new SparkConf()//建立SparkConf物件,由於全域性只有一個SparkConf所以不需要工廠方法
conf.setAppName("wow,my first spark app")//設定應用程式的名稱,在程式的監控介面可以看得到名稱
// conf.setMaster("spark://Master:7077")//此時程式在Spark叢集
/**
* 第二步:建立SparkContext物件
* SparkContext是Spark程式所有功能的唯一入口,無論是採用Scala、Java、Python、R等都必須要有一個
* SparkContext
* SparkContext核心作用:初始化Spark應用程式執行所需要的核心元件,包括DAGScheduler,TaskScheduler,SchedulerBacked,
* 同時還會負責Spark程式往Master註冊程式等
* SparkContext是整個Spark應用程式中最為至關重要的一個物件
*/
val sc=new SparkContext(conf)//建立SpackContext物件,通過傳入SparkConf例項來定製Spark執行的具體引數的配置資訊
/**
* 第三步:根據具體的資料來源(HDFS,HBase,Local,FileSystem,DB,S3)通過SparkContext來建立RDD
* RDD的建立基本有三種方式,(1)根據外部的資料來源(例如HDFS)(2)根據Scala集合(3)由其它的RDD操作
* 資料會被RDD劃分為成為一系列的Partitions,分配到每個Partition的資料屬於一個Task的處理範疇
*/
//讀取HDFS檔案並切分成不同的Partition
val lines=sc.textFile("hdfs://node1:8020/tmp/harryport.txt")
//val lines=sc.textFile("/index.html")
//型別推斷 ,也可以寫下面方式
// val lines : RDD[String] =sc.textFile("D://spark-1.6.1-bin-hadoop2.6//README.md", 1)
/**
* 第四步:對初始的RDD進行Transformation級別的處理,例如map,filter等高階函式
* 程式設計。來進行具體的資料計算
* 第4.1步:將每一行的字串拆分成單個的單詞
*/
//對每一行的字串進行單詞拆分並把所有行的結果通過flat合併成一個大的集合
val words = lines.flatMap { line => line.split(" ") }
/**
* 第4.2步在單詞拆分的基礎上,對每個單詞例項計數為1,也就是word=>(word,1)tuple
*/
val pairs = words.map { word => (word,1) }
/**
* 第4.3步在每個單詞例項計數為1的基礎之上統計每個單詞在文中出現的總次數
*/
//對相同的key進行value的累加(包括local和Reduce級別的同時Reduce)
val wordCounts = pairs.reduceByKey(_+_)
//列印結果
wordCounts.collect.foreach(wordNumberPair => println(wordNumberPair._1 + ":" +wordNumberPair._2))
//釋放資源
sc.stop()
}
}打包
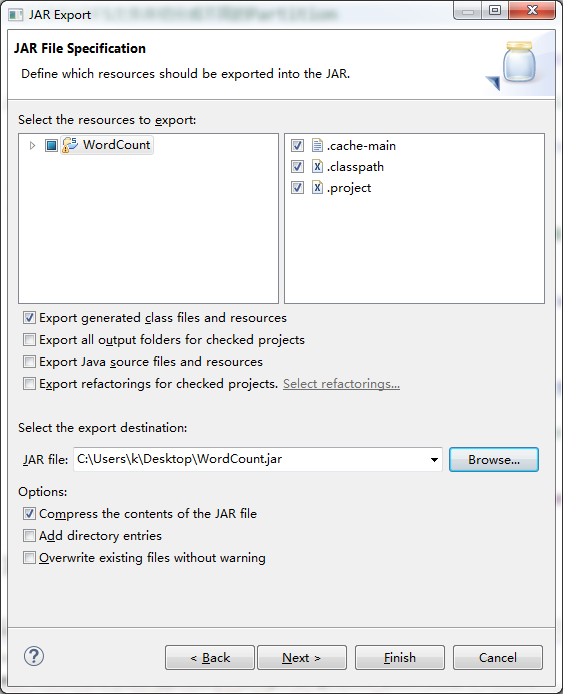
右擊,export,java ,jar File
wordcoun.sh內容
./spark-submit --class com.test.WordCountCluster /root/WordCount.jar
修改許可權chmod 777 wordcount.sh
進入spark/bin目錄下
cd /opt/cloudera/parcels/CDH-5.6.0-1.cdh5.6.0.p0.45/lib/spark/bin
執行指令碼檔案wordcount.sh
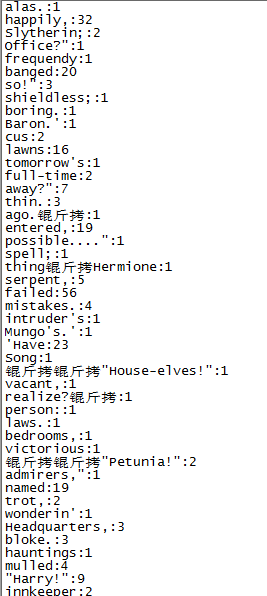
sh /root/wordcount.sh讀取hdfs://node1:8020/tmp/harryport.txt目錄下的單詞並統計
執行結果如下:
SBT
相關推薦
SCALA_IDE開發Spark程式
IDEA Eclipse 下載scala 下載地址 scala.msi scala環境變數配置 (1)設定SCALA-HOME變數:如圖,單擊新建,在變數名一欄輸入: SCALA-HOME 變數值一欄輸入: D:\Prog
IntelliJ Idea開發spark程式及執行
版本:spark-1.6.0,IntelliJ Idea15 1.建立一個SBT專案 2.編寫簡單程式碼 package com.james.scala /* SimpleApp.scala */ import org.apache.spa
IDEA+scala外掛開發spark程式
spark由scala語言編寫,開發spark程式,自然也少不了scala環境,這裡介紹如何利用Intellij IDEA開發spark。1、環境準備。jdk,scala,idea這些對於本文來說都已經預設安裝。2、idea中安裝scala language外掛。File-&
idea開發第一個spark程式---統計文字單詞數
在建立專案之前確保自己本地安裝好了scala環境和java環境,因為spark是scala編寫的,scala和java一樣都是需要編譯成位元組碼,然後在JVM裡面執行。我本地的scala版本是2.11.0版本,hadoop是2.7.6版本 第一步:開啟idea,然後建立一個
pvuv的程式碼開發及提交spark程式jar包執行讀取資料來源並將結果寫入MySQL中
目錄 PvUvToMysql類 ConnectionUtils類 jdbc.properties檔案 在IDEA中打jar包的兩種方式 IDEA打jar包 IDEA中maven方式打jar包 提交spark程式ja
IDEA 中開發第一個Spark 程式
1. 建立一個Maven 專案 2. 新增SCALA依賴庫 ****注意scala 的版本 相對於spark2.4 ,scala 的版本必須是2.11.x 修改POM.xml 檔案 加入 hadoop-client 和spark-core_2.11 的庫依賴
Spark開發wordcount程式
1、java版本(spark-2.1.0) package chavin.king; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction;
IDEA搭建scala開發環境開發spark應用程式
一、idea社群版安裝scala外掛 因為idea預設不支援scala開發環境,所以當需要使用idea搭建scala開發環境時,首先需要安裝scala外掛,具體安裝辦法如下。 1、開啟idea,點選configure下拉選單中的plugins選項: 2、在彈出對話方塊中點選紅框按鈕: 3、在彈出最新對話
通過IDEA搭建scala開發環境開發spark應用程式
一、idea社群版安裝scala外掛因為idea預設不支援scala開發環境,所以當需要使用idea搭建scala開發環境時,首先需要安裝scala外掛,具體安裝辦法如下。1、開啟idea,點選configure下拉選單中的plugins選項:2、在彈出對話方塊中點選紅框按鈕:3、在彈出最新對話方塊的搜尋欄輸
使用idea和maven開發和打包scala和spark程式
使用idea構建maven管理的scala和spark程式,預設已經裝好了idea、scala並在idea中安裝了scala外掛。一、新建Maven專案開啟idea,點選File—New—Project,彈出如下介面,選擇Maven專案,檢視是否是正確的JDK配置項正常來說這
在Windows下用Eclipse開發和執行Spark程式
我們想現在windows環境下開發除錯好spark程式,然後打包,最後放到linux spark叢集環境去執行。 Windows環境準備 Windows本地測試執行 打包 為了可以選擇哪些第三方庫打進jar包,我們需要安裝Fat Jar
spark2.x由淺入深深到底系列五之python開發spark環境配置
spark 大數據 rdd 開發環境 python 學習spark任何的技術前,請先正確理解spark,可以參考: 正確理解spark以下是在mac操作系統上配置用python開發spark的環境一、安裝pythonspark2.2.0需要python的版本是Python2.6+ 或者 P
IDEA搭建scala開發環境開發spark應用程序
編寫 運行程序 通過 https apach import input inf 搭建 一、idea社區版安裝scala插件 因為idea默認不支持scala開發環境,所以當需要使用idea搭建scala開發環境時,首先需要安裝scala插件,具體安裝辦法如下。 1、
8年開發java程式設計師教你:JAVA開發應該學習什麼?讓你不迷茫
java入門學習有哪些內容?很多想學習java的學生都不知道怎麼學java,特別是沒有基礎的學生,今天8年開發的老程式設計師,給大家整理了一下,java入門學習有哪些內容: 第一階段 計算機基本原理,Java語言發展簡史,Java開發環境的搭建,體驗Java程式的開發,Java語法格式
關於vs開發windows程式過程中記憶體檢查二三事
做為一個C/C++程式設計師,面對資源管理是必不可少的。今天,我對我這些年的經驗的一些總結。 每一個程式在執行時都佔用一塊可用的記憶體空間,用於存放動態分配的物件,此記憶體空間稱為程式的自由儲存區或堆。 C 語言程式使用一對標準庫函式 malloc 和 free 在自由儲存區
想高效開發小程式,mpvue瞭解下(一)
序言 小程式一定是今年熱門話題之一,對於我們開發者來講,開發小程式也是屬於我們的技能之一了。從去年我也玩過小程式,但當時處於內測的階段,各種反人類的設計都有,連es6都不支援,只能說瞎折騰了。到了如今,小程式迎來春天,友好度提高了不少,wepy、taro與mpvue的出現也帶來更高的開發
小程式開發-小程式的組成
3.1 小程式的組成 WEB前端組成:HTML+CSS+JavaScript+AJAX+PHP介面 小程式的組成:WXML 模板 + WXSS 樣式 + JS 互動邏輯 + PHP介面 總結: WXML 模板 就是 HTML標籤,區別就是微信重新命名了新
小程式開發-小程式開始開發及基本設定
3.0 小程式開始開發及基本設定 微信開發文件:https://developers.weixin.qq.com/miniprogram/dev/ 下載微信開發者工具 下載地址:https://developers.weixin.qq.com/min
小程式開發-小程式介紹
小程式是什麼? 微信小程式(wei xin xiao cheng xu),簡稱小程式,英文名Mini Program,是一種不需要下載安裝即可使用的應用,它實現了應用“觸手可及”的夢想,使用者掃一掃或搜一下即可開啟應用。 小程式開發成本,大概只需要開發一個App成本的五
VS中用C#開發應用程式的除錯入門、技巧和例項(轉載)
入門篇 假設你是有著.Net平臺的程式設計師,並且使用Visual Studio 做為開發工具。 斷點:最簡單的一種,設定一個斷點,程式執行到那一句就自動中斷進入除錯狀態。設定斷點,在你覺得有問題的程式碼行,左側單擊,會出現紅色的紅點即斷點。 啟動調式:按F5,或者選單欄---調式---開始除錯,或