
Python爬蟲實現自動登入、簽到
更新 2016/8/9:最近發現目標網站已經遮蔽了這個登入簽到的介面(PS:不過我還是用這個方式賺到了將近一萬點積分·····)
前幾天女朋友跟我說,她在一個素材網站上下載東西,積分總是不夠用,積分是怎麼來的呢,是每天登入網站簽到獲得的,當然也能購買,她不想去買,因為偶爾才會用一次,但是每到用的時候就發現積分不夠,又記不得每天去簽到,所以就有了這個糾結的事情。怎麼辦呢,想辦法唄,於是我就用python寫了個小爬蟲,每天去自動幫她簽到掙積分。廢話不多說,下面就講講程式碼。
我這裡用的是python3.4,使用python2.x的朋友如果有需要請繞道檢視別的文章。
工具:Fiddler
首先下載安裝Fiddler,這個工具是用來監聽網路請求,有助於你分析請求連結和引數。
開啟目標網站:http://www.17sucai.com/,然後點選登入
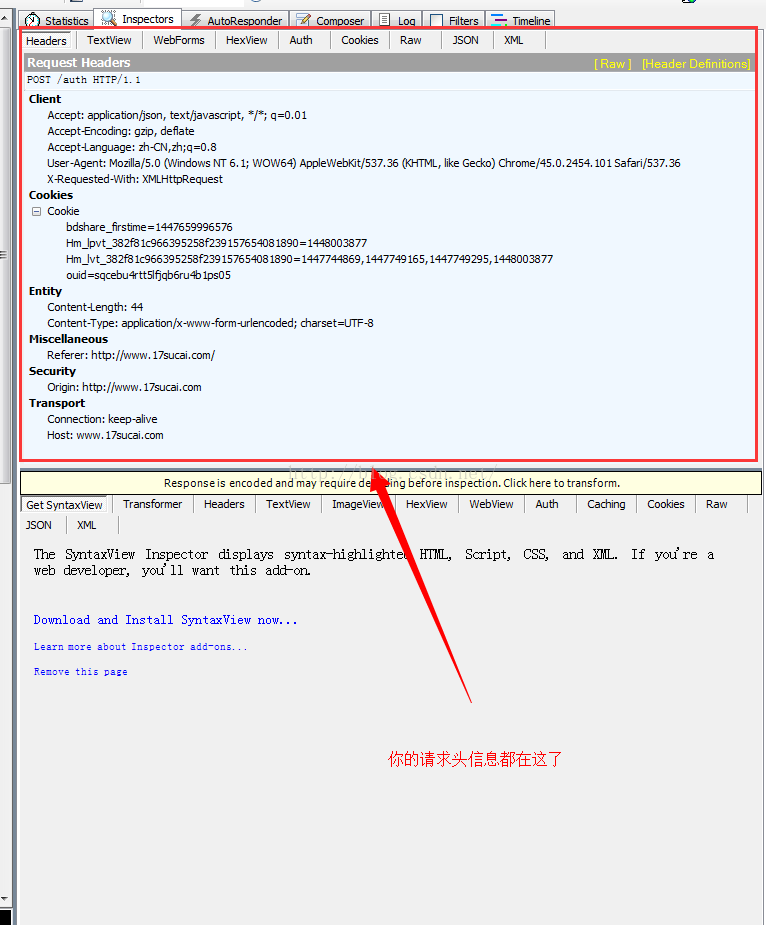
好了,先別急著登入,開啟你的Fiddler,此時Fiddler裡面是沒有監聽到網路請求的,然後回到頁面,輸入郵箱和密碼,點選登入,下面再到fiddler裡面去看

這裡面的第一個請求就是你點選登入的網路請求,點選這個連結可以在右邊看到你的一些請求資訊
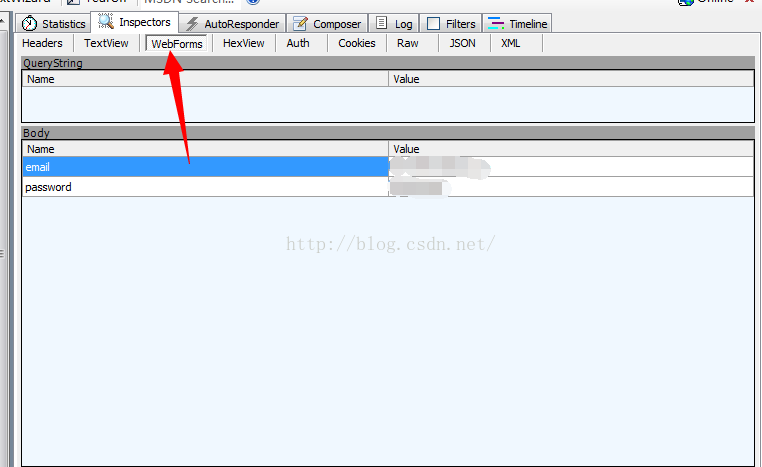
然後點選WebForms可以看到你的請求引數,也就是使用者名稱和密碼
下面我們有程式碼來實現登入功能
好了,接下來清空一下你的Fiddler,然後執行這個程式,看一下你的Fiddlerimport urllib.request import urllib import gzip import http.cookiejar #定義一個方法用於生成請求頭資訊,處理cookie def getOpener(head): # deal with the Cookies <pre name="code" class="python"> cj = http.cookiejar.CookieJar() pro = urllib.request.HTTPCookieProcessor(cj) opener = urllib.request.build_opener(pro) header = [] for key, value in head.items(): elem = (key, value) header.append(elem) opener.addheaders = header return opener #定義一個方法來解壓返回資訊 def ungzip(data): try: # 嘗試解壓 print('正在解壓.....') data = gzip.decompress(data) print('解壓完畢!') except: print('未經壓縮, 無需解壓') return data #封裝頭資訊,偽裝成瀏覽器 header = { 'Connection': 'Keep-Alive', 'Accept-Language': 'zh-CN,zh;q=0.8', 'Accept': 'application/json, text/javascript, */*; q=0.01', 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36', 'Accept-Encoding': 'gzip, deflate', 'X-Requested-With': 'XMLHttpRequest', 'Host': 'www.17sucai.com', } url = 'http://www.17sucai.com/auth' opener = getOpener(header) id = 'xxxxxxxxxxxxx'#你的使用者名稱 password = 'xxxxxxx'#你的密碼 postDict = { 'email': id, 'password': password, } postData = urllib.parse.urlencode(postDict).encode() op = opener.open(url, postData) data = op.read() data = ungzip(data) print(data)
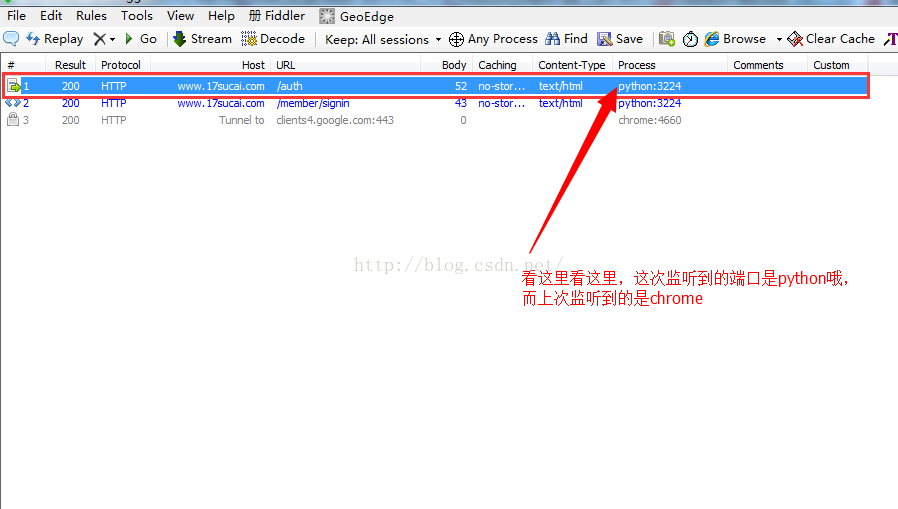
你可以點選這個連結,看看右邊的請求資訊和你用瀏覽器請求的是不是一樣
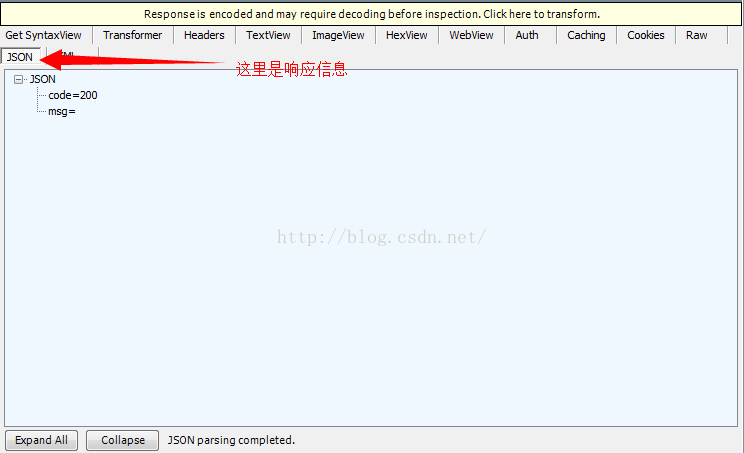
下面是程式後代列印的資訊

code=200表示登陸成功
解析來就需要獲取到簽到的url,這裡你需要一個沒有簽到的賬號在網站中點選簽到按鈕,然後通過Fiddler來獲取到簽到的連結和需要的資訊。
然後點選“簽到”,簽到成功後到Fiddler中檢視捕捉到的url
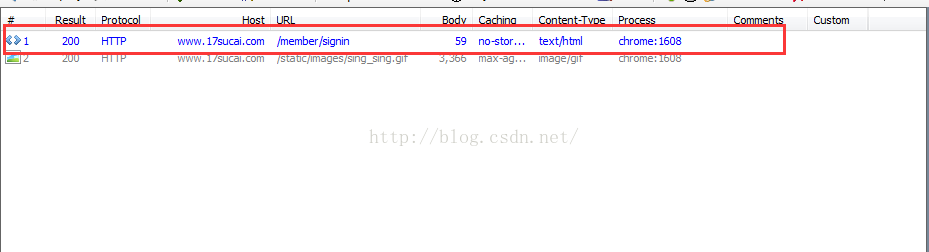
點選這個url可以在右邊檢視訪問這個連結時所需要的頭資訊和cookies神馬的,我們已經登入成功後直接使用cookies就行了,python對cookies的處理做好了封裝,下面是我的程式碼中對cookies的使用
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)下面是簽到成功返回的資訊:code=200表示請求成功,day=1表示連續簽到一天,score=20表示獲得的積分數
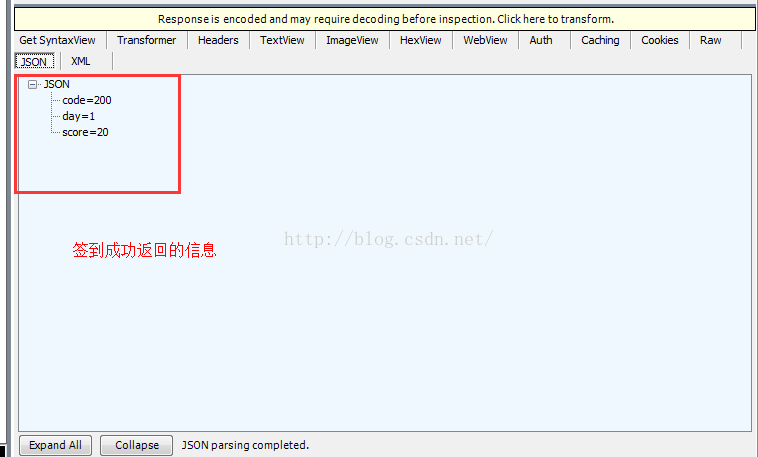
下面放出完整程式碼,當然,為了測試程式碼簽到,你還需要你一沒有簽到過的賬號
import urllib.request
import urllib
import gzip
import http.cookiejar
def getOpener(head):
# deal with the Cookies
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
def ungzip(data):
try: # 嘗試解壓
print('正在解壓.....')
data = gzip.decompress(data)
print('解壓完畢!')
except:
print('未經壓縮, 無需解壓')
return data
header = {
'Connection': 'Keep-Alive',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
'Accept-Encoding': 'gzip, deflate',
'X-Requested-With': 'XMLHttpRequest',
'Host': 'www.17sucai.com',
}
url = 'http://www.17sucai.com/auth'
opener = getOpener(header)
id = 'xxxxxxx'
password = 'xxxxxxx'
postDict = {
'email': id,
'password': password,
}
postData = urllib.parse.urlencode(postDict).encode()
op = opener.open(url, postData)
data = op.read()
data = ungzip(data)
print(data)
url = 'http://www.17sucai.com/member/signin' #簽到的地址
op = opener.open(url)
data = op.read()
data = ungzip(data)
print(data)相比登入,簽到也就是在登入完成後重新開啟一個連結而已,由於我的賬號都已經簽到過了,這裡就不在貼執行程式碼的圖 了。
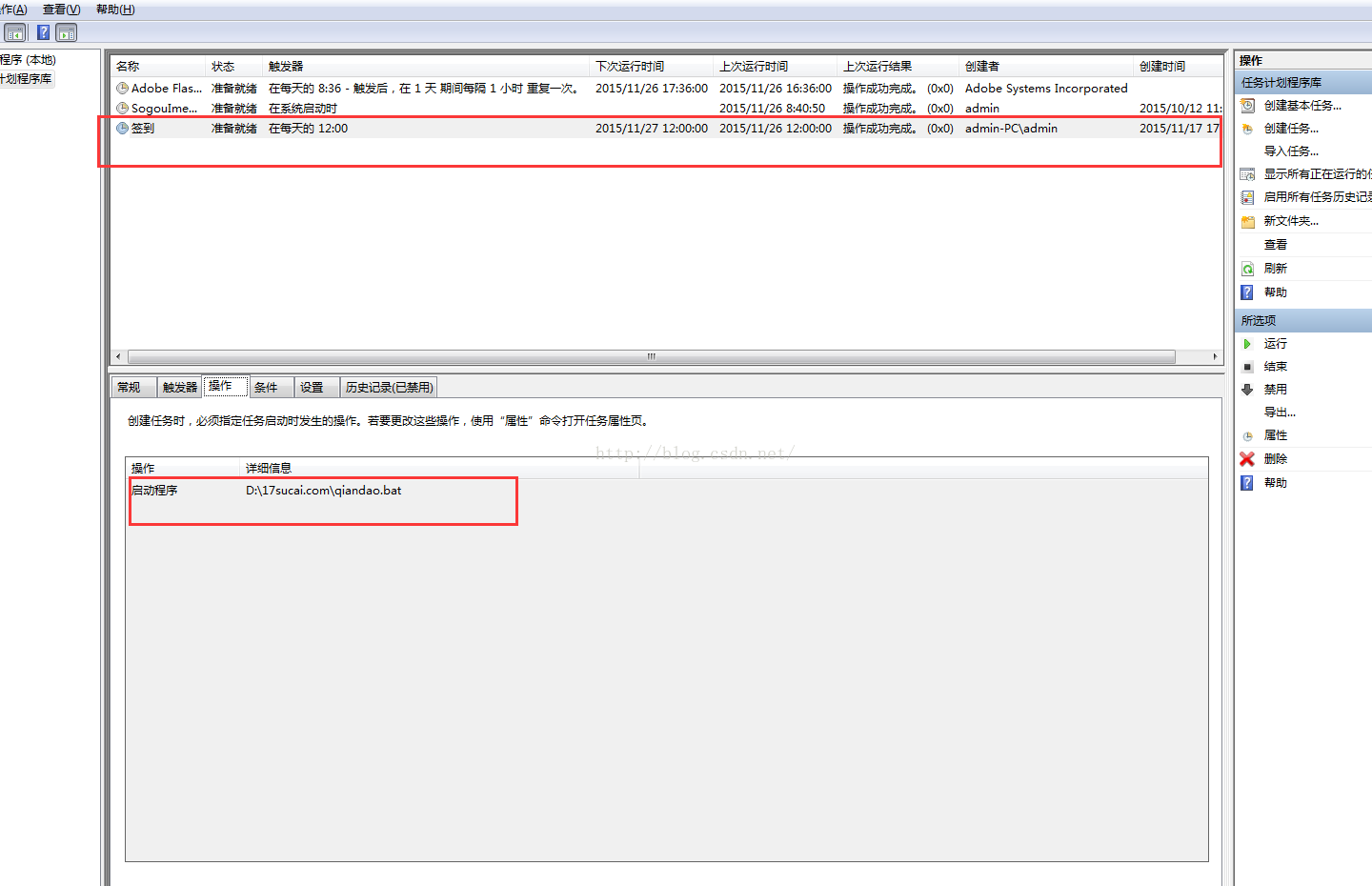
接下來要做的就是在你電腦上寫個bat 指令碼,再在“任務計劃”中新增一個定時任務就行了。
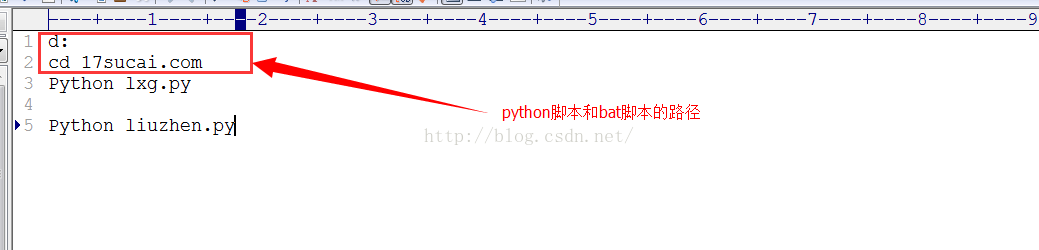
在此之前你還需要配置一下python的環境變數,這裡就不在贅述了。
相關推薦
Python爬蟲實現自動登入、簽到
更新 2016/8/9:最近發現目標網站已經遮蔽了這個登入簽到的介面(PS:不過我還是用這個方式賺到了將近一萬點積分·····) 前幾天女朋友跟我說,她在一個素材網站上下載東西,積分總是不夠用,積分是怎麼來的呢,是每天登入網站簽到獲得的,當然也
Python爬蟲之自動登入與驗證碼識別
轉自:http://blog.csdn.net/tobacco5648/article/details/50640691 在用爬蟲爬取網站資料時,有些站點的一些關鍵資料的獲取需要使用賬號登入,這裡可以使用requests傳送登入請求,並用Session物件來自動處理相關
Python Selenium實現自動登入163郵箱
最近看了看Selenium,發現這個玩意是相當好用,於是我想自己寫一個郵箱自動登入的小程式,下面以登入163郵箱為例,一開始遇到了很多問題,在網上看了很多教程,發現也都失效了,經過一下午的摸索,終於找到了原因——在Web應用中經常會遇到frame/iframe
[Python爬蟲] Selenium實現自動登入163郵箱和Locating Elements介紹
前三篇文章介紹了安裝過程和通過Selenium實現訪問Firefox瀏覽器並自動搜尋"Eastmount"關鍵字及截圖的功能。而這篇文章主要簡單介紹如何實現自動登入163郵箱,同時繼續介紹Selenium+Python官網Locating Elements部
Python實現自動登入,強行突破圖形驗證碼!
驗證碼有圖形驗證碼、極驗滑動驗證碼、點觸驗證碼、宮格驗證碼。這回重點講講圖形驗證碼的識別。 學習Python中有不明白推薦加入交流群 號:516107834 &
利用Python識別圖形驗證碼!實現自動登入!室友驚訝的合不攏嘴!
驗證碼有圖形驗證碼、極驗滑動驗證碼、點觸驗證碼、宮格驗證碼。這回重點講講圖形驗證碼的識別。 雖說圖形驗證碼最簡單,但是對於我這等新手,還是要苦學一番。首先尋找測試網站,網站選的是如雲閣小說網,小網站不怕被封。他們的驗證碼一般如下:
Python-webbrowser實現自動開啟關、定時開啟關閉網頁/重新整理網頁
webbrowser- 方便的Web瀏覽器控制器,是Python一個模組,可實現自動開啟關、定時開啟關閉網頁/重新整理網頁,在Unix下,圖形瀏覽器在X11下更受歡迎,但如果圖形瀏覽器不可用或X11顯示器不可用,則將使用文字模式瀏覽器。如果使用文字模式瀏覽器,則呼叫程序將阻塞
OkHttp3.0(結合Retrofit2/Rxjava)利用攔截器實現全域性超時自動登入、新增統一引數
應用場景:1.服務端為了統計各個平臺、版本的使用情況,有時在介面中要求傳遞統一的諸如version(客戶端版本)、os(客戶端平臺android/iOS)、userId等引數,這時如果在介面中一一新增就比較繁瑣了,考慮做全域性處理;另外,一次登入成功後,
Python爬蟲:HTTP協議、Requests庫
.org clas python爬蟲 print 通用 娛樂 信息 傳輸協議 介紹 HTTP協議: HTTP(Hypertext Transfer Protocol):即超文本傳輸協議。URL是通過HTTP協議存取資源的Internet路徑,一個URL對應一個數據資源。
struts2框架+mysql,實現使用者登入、註冊功能
說明:所有原始碼已上傳到筆者GitHub上,歡迎follow、star。感謝!!! 一、Demo介紹 本Demo具體實現了以下功能: 1.基於struts2框架+MySQL資料庫驗證,實現了使用者登入、註冊功能。 2.使用者註冊時,分別使用客戶端校驗和伺服器端校
JAVA RPC遠端呼叫伺服器實現使用者登入、註冊
先來百科掃盲 : 什麼是 RPC(反正我也剛看的) RPC(Remote Procedure Call)—遠端過程呼叫,它是一種通過網路從遠端計算機程式上請求服務,而不需要了解底層網路技術的協議。RPC協議假定某些傳輸協議的存在,如TCP或UDP,為通訊程式之間攜帶資訊資料。在OSI
python爬蟲-- 抓取網頁、圖片、文章
零基礎入門Python,給自己找了一個任務,做網站文章的爬蟲小專案,因為實戰是學程式碼的最快方式。所以從今天起開始寫Python實戰入門系列教程,也建議大家學Python時一定要多寫多練。 目標 1,學習Python爬蟲 2,爬取新聞網站新聞列表 3,爬取圖片 4,把爬取到的資料存在本地
php微信網頁開發實現自動登入註冊功能例項
功能:自動登入註冊功能 描述:php實現微信網頁自動登入註冊功能 範圍:適用於所有php版本 thinkphp5.0例項 $token = cookie('token'); if($token){ //這裡寫登入後的邏輯 }else{ $
問卷星 python+splinter實現自動,selenium那個也是可以的
因為被毛概作業纏身= = 無奈此舉 解放大家 小tips:速度調慢一點= =不然被拒絕ip了不要怪博主 from splinter import Browser; browser=Browser('chrome'); import time time_second=0.5; def
SSM整合系列之 基於Shiro框架實現自動登入(RememberMe)
一、前言:Shiro框架提供了記住我(RememerMe)的功能,比如我們訪問一些網站,關閉了瀏覽器,下次再開啟還是能記住你是誰,下次訪問的時候無需登入即可訪問,本文將實現記住我的功能。 專案git地址:https://github.com/gitcaiqing/SSM_DEMO.git
Django 內建的authenticate 處login,logou實現使用者登入、注消
views.py 1. 寫二個函式 userlogon 實現使用者登入驗證,userlogou實現注消 from django.shortcuts import render, HttpResponse from django.contrib.auth import authenticat
定時執行Python指令碼實現自動簽到
起初學Python最想做的就是實現自動簽到了,而且是全自動的,電腦關機也能執行簽到的那種,後來程式碼實現了但是偏偏驅動器出問題了,也就是程式執行第一步 不能開啟瀏覽器,後來我的pycharm的環境也出各種問題,我亂增改路徑導致我的python的pip指令都執行不了了,或許是以
mstsc儲存使用者名稱和密碼,實現自動登入遠端桌面
MSTSC引數說明 首先可以使用mstsc /?來檢視關於mstsc的引數說明 根據上述的命令說明,我這裡實現的bat檔案為 mstsc C:/a.rdp /console /v: xxx.xxx.xxx.xxx:3389 rdp檔案生成方法 最近由
ssm整合shiro通過自定義Realm實現認證登入、許可權處理、自定義role攔截、MD5加密
整合後實現功能 1.登入認證 2.許可權處理 3.自定義role攔截 4.md5加密 ssm整合shiro步驟 先看看整合完成後的專案結構 新建一個maven專案 配置pom.xml檔案 <?xml version="1.0" encoding="UT