
Parquet與ORC:高效能列式儲存格式
背景
隨著大資料時代的到來,越來越多的資料流向了Hadoop生態圈,同時對於能夠快速的從TB甚至PB級別的資料中獲取有價值的資料對於一個產品和公司來說更加重要,在Hadoop生態圈的快速發展過程中,湧現了一批開源的資料分析引擎,例如Hive、Spark SQL、Impala、Presto等,同時也產生了多個高效能的列式儲存格式,例如RCFile、ORC、Parquet等,本文主要從實現的角度上對比分析ORC和Parquet兩種典型的列存格式,並對它們做了相應的對比測試。
列式儲存
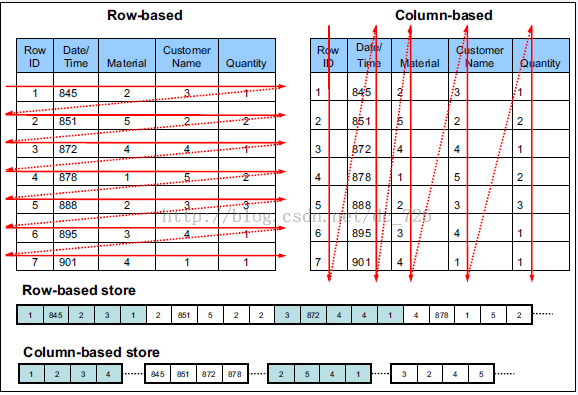
由於OLAP查詢的特點,列式儲存可以提升其查詢效能,但是它是如何做到的呢?這就要從列式儲存的原理說起,從圖1中可以看到,相對於關係資料庫中通常使用的行式儲存,在使用列式儲存時每一列的所有元素都是順序儲存的。由此特點可以給查詢帶來如下的優化:
- 查詢的時候不需要掃描全部的資料,而只需要讀取每次查詢涉及的列,這樣可以將I/O消耗降低N倍,另外可以儲存每一列的統計資訊(min、max、sum等),實現部分的謂詞下推。
- 由於每一列的成員都是同構的,可以針對不同的資料型別使用更高效的資料壓縮演算法,進一步減小I/O。
- 由於每一列的成員的同構性,可以使用更加適合CPU pipeline的編碼方式,減小CPU的快取失效。
巢狀資料格式
通常我們使用關係資料庫儲存結構化資料,而關係資料庫支援的資料模型都是扁平式的,而遇到諸如List、Map和自定義Struct的時候就需要使用者自己解析,但是在大資料環境下,資料的來源多種多樣,例如埋點資料,很可能需要把程式中的某些物件內容作為輸出的一部分,而每一個物件都可能是巢狀的,所以如果能夠原生的支援這種資料,查詢的時候就不需要額外的解析便能獲得想要的結果。例如在Twitter,他們一個典型的日誌物件(一條記錄)有87個欄位,其中嵌套了7層,如下圖。
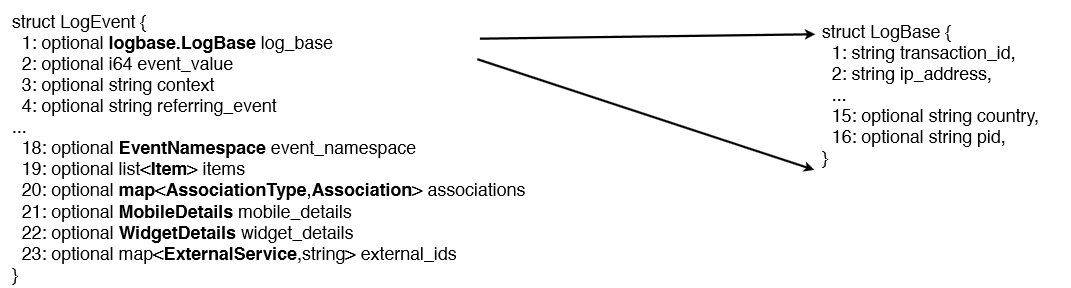
隨著巢狀格式的資料的需求日益增加,目前Hadoop生態圈中主流的查詢引擎都支援更豐富的資料型別,例如Hive、SparkSQL、Impala等都原生的支援諸如struct、map、array這樣的複雜資料型別,這樣促使各種儲存格式都需要支援巢狀資料格式。
Parquet儲存格式
Apache Parquet是Hadoop生態圈中一種新型列式儲存格式,它可以相容Hadoop生態圈中大多數計算框架(Mapreduce、Spark等),被多種查詢引擎支援(Hive、Impala、Drill等),並且它是語言和平臺無關的。Parquet最初是由Twitter和Cloudera合作開發完成並
Parquet最初的靈感來自Google於2010年發表的Dremel論文,文中介紹了一種支援巢狀結構的儲存格式,並且使用了列式儲存的方式提升查詢效能,在Dremel論文中還介紹了Google如何使用這種儲存格式實現並行查詢的,如果對此感興趣可以參考論文和開源實現Drill。
資料模型
Parquet支援巢狀的資料模型,類似於Protocol Buffers,每一個數據模型的schema包含多個欄位,每一個欄位有三個屬性:重複次數、資料型別和欄位名,重複次數可以是以下三種:required(只出現1次),repeated(出現0次或多次),optional(出現0次或1次)。每一個欄位的資料型別可以分成兩種:group(複雜型別)和primitive(基本型別)。例如Dremel中提供的Document的schema示例,它的定義如下:
message Document {
required int64 DocId;
optional group Links {
repeated int64 Backward;
repeated int64 Forward;
}
repeated group Name {
repeated group Language {
required string Code;
optional string Country;
}
optional string Url;
}
}
可以把這個Schema轉換成樹狀結構,根節點可以理解為repeated型別,如圖3。
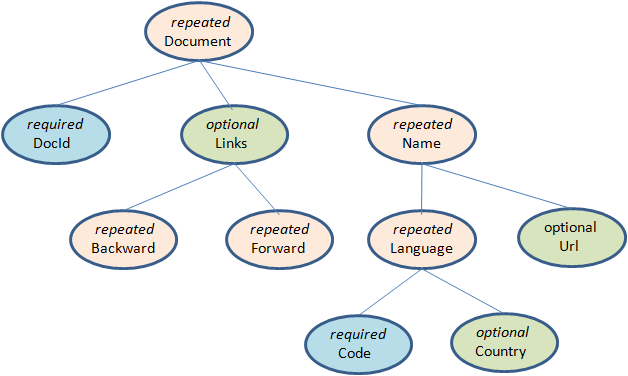
可以看出在Schema中所有的基本型別欄位都是葉子節點,在這個Schema中一共存在6個葉子節點,如果把這樣的Schema轉換成扁平式的關係模型,就可以理解為該表包含六個列。Parquet中沒有Map、Array這樣的複雜資料結構,但是可以通過repeated和group組合來實現的。由於一條記錄中某一列可能出現零次或者多次,需要標示出哪些列的值構成一條完整的記錄。這是由Striping/Assembly演算法實現的。
由於Parquet支援的資料模型比較鬆散,可能一條記錄中存在比較深的巢狀關係,如果為每一條記錄都維護一個類似的樹狀結可能會佔用較大的儲存空間,因此Dremel論文中提出了一種高效的對於巢狀資料格式的壓縮演算法:Striping/Assembly演算法。它的原理是每一個記錄中的每一個成員值有三部分組成:Value、Repetition level和Definition level。value記錄了該成員的原始值,可以根據特定型別的壓縮演算法進行壓縮,兩個level值用於記錄該值在整個記錄中的位置。對於repeated型別的列,Repetition level值記錄了當前值屬於哪一條記錄以及它處於該記錄的什麼位置;對於repeated和optional型別的列,可能一條記錄中某一列是沒有值的,假設我們不記錄這樣的值就會導致本該屬於下一條記錄的值被當做當前記錄的一部分,從而造成資料的錯誤,因此對於這種情況需要一個佔位符標示這種情況。
通過Striping/Assembly演算法,parquet可以使用較少的儲存空間表示複雜的巢狀格式,並且通常Repetition level和Definition level都是較小的整數值,可以通過RLE演算法對其進行壓縮,進一步降低儲存空間。
檔案結構
Parquet檔案是以二進位制方式儲存的,是不可以直接讀取和修改的,Parquet檔案是自解析的,檔案中包括該檔案的資料和元資料。在HDFS檔案系統和Parquet檔案中存在如下幾個概念:
- HDFS塊(Block):它是HDFS上的最小的副本單位,HDFS會把一個Block儲存在本地的一個檔案並且維護分散在不同的機器上的多個副本,通常情況下一個Block的大小為256M、512M等。
- HDFS檔案(File):一個HDFS的檔案,包括資料和元資料,資料分散儲存在多個Block中。
- 行組(Row Group):按照行將資料物理上劃分為多個單元,每一個行組包含一定的行數,在一個HDFS檔案中至少儲存一個行組,Parquet讀寫的時候會將整個行組快取在記憶體中,所以如果每一個行組的大小是由記憶體大的小決定的。
- 列塊(Column Chunk):在一個行組中每一列儲存在一個列塊中,行組中的所有列連續的儲存在這個行組檔案中。不同的列塊可能使用不同的演算法進行壓縮。
- 頁(Page):每一個列塊劃分為多個頁,一個頁是最小的編碼的單位,在同一個列塊的不同頁可能使用不同的編碼方式。
通常情況下,在儲存Parquet資料的時候會按照HDFS的Block大小設定行組的大小,由於一般情況下每一個Mapper任務處理資料的最小單位是一個Block,這樣可以把每一個行組由一個Mapper任務處理,增大任務執行並行度。Parquet檔案的格式如下圖所示。
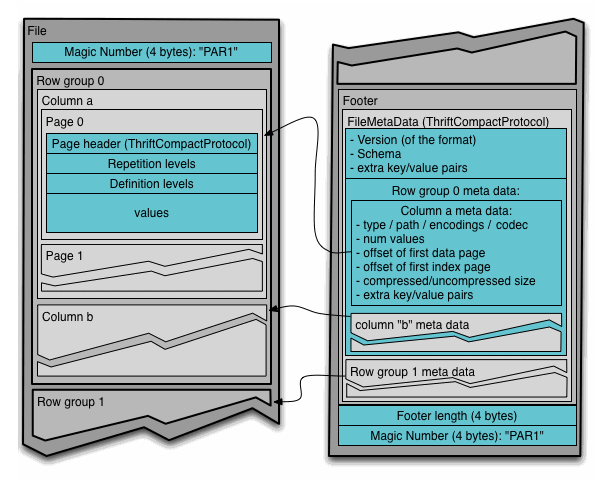
上圖展示了一個Parquet檔案的結構,一個檔案中可以儲存多個行組,檔案的首位都是該檔案的Magic Code,用於校驗它是否是一個Parquet檔案,Footer length儲存了檔案元資料的大小,通過該值和檔案長度可以計算出元資料的偏移量,檔案的元資料中包括每一個行組的元資料資訊和當前檔案的Schema資訊。除了檔案中每一個行組的元資料,每一頁的開始都會儲存該頁的元資料,在Parquet中,有三種類型的頁:資料頁、字典頁和索引頁。資料頁用於儲存當前行組中該列的值,字典頁儲存該列值的編碼字典,每一個列塊中最多包含一個字典頁,索引頁用來儲存當前行組下該列的索引,目前Parquet中還不支援索引頁,但是在後面的版本中增加。
資料訪問
說到列式儲存的優勢,Project下推是無疑最突出的,它意味著在獲取表中原始資料時只需要掃描查詢中需要的列,由於每一列的所有值都是連續儲存的,避免掃描整個表文件內容。
在Parquet中原生就支援Project下推,執行查詢的時候可以通過Configuration傳遞需要讀取的列的資訊,這些列必須是Schema的子集,Parquet每次會掃描一個Row Group的資料,然後一次性得將該Row Group裡所有需要的列的Cloumn Chunk都讀取到記憶體中,每次讀取一個Row Group的資料能夠大大降低隨機讀的次數,除此之外,Parquet在讀取的時候會考慮列是否連續,如果某些需要的列是儲存位置是連續的,那麼一次讀操作就可以把多個列的資料讀取到記憶體。
在資料訪問的過程中,Parquet還可以利用每一個row group生成的統計資訊進行謂詞下推,這部分資訊包括該Column Chunk的最大值、最小值和空值個數。通過這些統計值和該列的過濾條件可以判斷該Row Group是否需要掃描。另外Parquet未來還會增加諸如Bloom Filter和Index等優化資料,更加有效的完成謂詞下推。
ORC檔案格式
ORC檔案格式是一種Hadoop生態圈中的列式儲存格式,它的產生早在2013年初,最初產生自Apache Hive,用於降低Hadoop資料儲存空間和加速Hive查詢速度。和Parquet類似,它並不是一個單純的列式儲存格式,仍然是首先根據行組分割整個表,在每一個行組內進行按列儲存。ORC檔案是自描述的,它的元資料使用Protocol Buffers序列化,並且檔案中的資料儘可能的壓縮以降低儲存空間的消耗,目前也被Spark SQL、Presto等查詢引擎支援,但是Impala對於ORC目前沒有支援,仍然使用Parquet作為主要的列式儲存格式。2015年ORC專案被Apache專案基金會提升為Apache頂級專案。
資料模型
和Parquet不同,ORC原生是不支援巢狀資料格式的,而是通過對複雜資料型別特殊處理的方式實現巢狀格式的支援,例如對於如下的hive表:
CREATE TABLE `orcStructTable`(
`name` string,
`course` struct<course:string,score:int>,
`score` map<string,int>,
`work_locations` array<string>)
ORC格式會將其轉換成如下的樹狀結構:

在ORC的結構中這個schema包含10個column,其中包含了複雜型別列和原始型別的列,前者包括LIST、STRUCT、MAP和UNION型別,後者包括BOOLEAN、整數、浮點數、字串型別等,其中STRUCT的孩子節點包括它的成員變數,可能有多個孩子節點,MAP有兩個孩子節點,分別為key和value,LIST包含一個孩子節點,型別為該LIST的成員型別,UNION一般不怎麼用得到。每一個Schema樹的根節點為一個Struct型別,所有的column按照樹的中序遍歷順序編號。
ORC只需要儲存schema樹中葉子節點的值,而中間的非葉子節點只是做一層代理,它們只需要負責孩子節點值得讀取,只有真正的葉子節點才會讀取資料,然後交由父節點封裝成對應的資料結構返回。
檔案結構
和Parquet類似,ORC檔案也是以二進位制方式儲存的,所以是不可以直接讀取,ORC檔案也是自解析的,它包含許多的元資料,這些元資料都是同構ProtoBuffer進行序列化的。ORC的檔案結構入圖6,其中涉及到如下的概念:
- ORC檔案:儲存在檔案系統上的普通二進位制檔案,一個ORC檔案中可以包含多個stripe,每一個stripe包含多條記錄,這些記錄按照列進行獨立儲存,對應到Parquet中的row group的概念。
- 檔案級元資料:包括檔案的描述資訊PostScript、檔案meta資訊(包括整個檔案的統計資訊)、所有stripe的資訊和檔案schema資訊。
- stripe:一組行形成一個stripe,每次讀取檔案是以行組為單位的,一般為HDFS的塊大小,儲存了每一列的索引和資料。
- stripe元資料:儲存stripe的位置、每一個列的在該stripe的統計資訊以及所有的stream型別和位置。
- row group:索引的最小單位,一個stripe中包含多個row group,預設為10000個值組成。
- stream:一個stream表示檔案中一段有效的資料,包括索引和資料兩類。索引stream儲存每一個row group的位置和統計資訊,資料stream包括多種型別的資料,具體需要哪幾種是由該列型別和編碼方式決定。
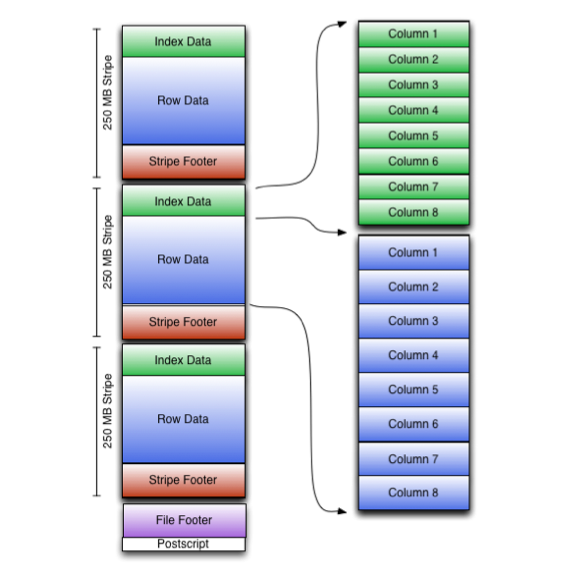
在ORC檔案中儲存了三個層級的統計資訊,分別為檔案級別、stripe級別和row group級別的,他們都可以用來根據Search ARGuments(謂詞下推條件)判斷是否可以跳過某些資料,在統計資訊中都包含成員數和是否有null值,並且對於不同型別的資料設定一些特定的統計資訊。
資料訪問
讀取ORC檔案是從尾部開始的,第一次讀取16KB的大小,儘可能的將Postscript和Footer資料都讀入記憶體。檔案的最後一個位元組儲存著PostScript的長度,它的長度不會超過256位元組,PostScript中儲存著整個檔案的元資料資訊,它包括檔案的壓縮格式、檔案內部每一個壓縮塊的最大長度(每次分配記憶體的大小)、Footer長度,以及一些版本資訊。在Postscript和Footer之間儲存著整個檔案的統計資訊(上圖中未畫出),這部分的統計資訊包括每一個stripe中每一列的資訊,主要統計成員數、最大值、最小值、是否有空值等。
接下來讀取檔案的Footer資訊,它包含了每一個stripe的長度和偏移量,該檔案的schema資訊(將schema樹按照schema中的編號儲存在陣列中)、整個檔案的統計資訊以及每一個row group的行數。
處理stripe時首先從Footer中獲取每一個stripe的其實位置和長度、每一個stripe的Footer資料(元資料,記錄了index和data的的長度),整個striper被分為index和data兩部分,stripe內部是按照row group進行分塊的(每一個row group中多少條記錄在檔案的Footer中儲存),row group內部按列儲存。每一個row group由多個stream儲存資料和索引資訊。每一個stream的資料會根據該列的型別使用特定的壓縮演算法儲存。在ORC中存在如下幾種stream型別:
- PRESENT:每一個成員值在這個stream中保持一位(bit)用於標示該值是否為NULL,通過它可以只記錄部位NULL的值
- DATA:該列的中屬於當前stripe的成員值。
- LENGTH:每一個成員的長度,這個是針對string型別的列才有的。
- DICTIONARY_DATA:對string型別資料編碼之後字典的內容。
- SECONDARY:儲存Decimal、timestamp型別的小數或者納秒數等。
- ROW_INDEX:儲存stripe中每一個row group的統計資訊和每一個row group起始位置資訊。
在初始化階段獲取全部的元資料之後,可以通過includes陣列指定需要讀取的列編號,它是一個boolean陣列,如果不指定則讀取全部的列,還可以通過傳遞SearchArgument引數指定過濾條件,根據元資料首先讀取每一個stripe中的index資訊,然後根據index中統計資訊以及SearchArgument引數確定需要讀取的row group編號,再根據includes資料決定需要從這些row group中讀取的列,通過這兩層的過濾需要讀取的資料只是整個stripe多個小段的區間,然後ORC會盡可能合併多個離散的區間儘可能的減少I/O次數。然後再根據index中儲存的下一個row group的位置資訊調至該stripe中第一個需要讀取的row group中。
由於ORC中使用了更加精確的索引資訊,使得在讀取資料時可以指定從任意一行開始讀取,更細粒度的統計資訊使得讀取ORC檔案跳過整個row group,ORC預設會對任何一塊資料和索引資訊使用ZLIB壓縮,因此ORC檔案佔用的儲存空間也更小,這點在後面的測試對比中也有所印證。
在新版本的ORC中也加入了對Bloom Filter的支援,它可以進一步提升謂詞下推的效率,在Hive 1.2.0版本以後也加入了對此的支援。
效能測試
為了對比測試兩種儲存格式,我選擇使用TPC-DS資料集並且對它進行改造以生成寬表、巢狀和多層巢狀的資料。使用最常用的Hive作為SQL引擎進行測試。
測試環境
- Hadoop叢集:物理測試叢集,四臺DataNode/NodeManager機器,每個機器32core+128GB,測試時使用整個叢集的資源。
- Hive:Hive 1.2.1版本,使用hiveserver2啟動,本機MySql作為元資料庫,jdbc方式提交查詢SQL
- 資料集:100GB TPC-DS資料集,選取其中的Store_Sales為事實表的模型作為測試資料
- 查詢SQL:選擇TPC-DS中涉及到上述模型的10條SQL並對其進行改造。
測試場景和結果
整個測試設定了四種場景,每一種場景下對比測試資料佔用的儲存空間的大小和相同查詢執行消耗的時間對比,除了場景一基於原始的TPC-DS資料集外,其餘的資料都需要進行資料匯入,同時對比這幾個場景的資料匯入時間。
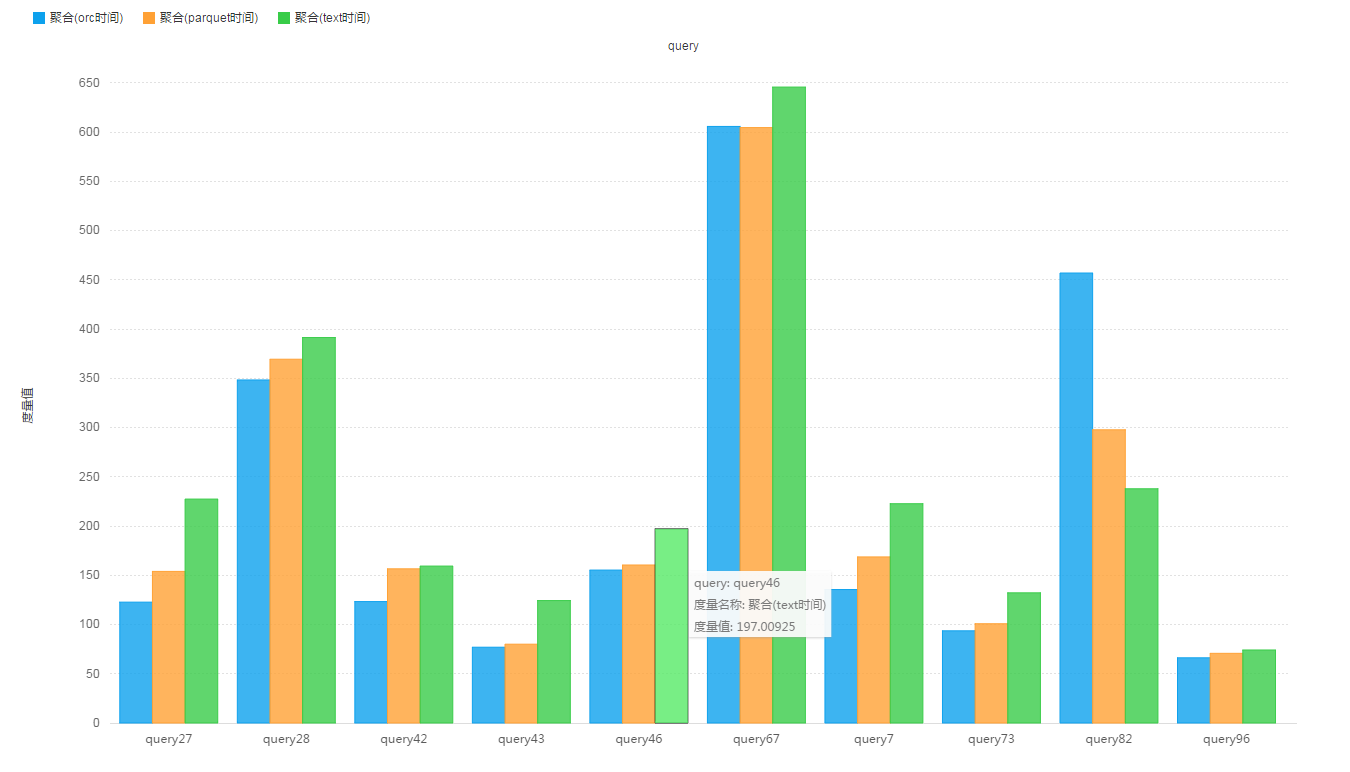
場景一:一個事實表、多個維度表,複雜的join查詢。
基於原始的TPC-DS資料集。
Store_Sales表記錄數:287,997,024,表大小為:
- 原始Text格式,未壓縮 : 38.1 G
- ORC格式,預設壓縮(ZLIB),一共1800+個分割槽 : 11.5 G
- Parquet格式,預設壓縮(Snappy),一共1800+個分割槽 : 14.8 G
查詢測試結果:
場景二:維度表和事實表join之後生成的寬表,只在一個表上做查詢。
整個測試設定了四種場景,每一種場景下對比測試資料佔用的儲存空間的大小和相同查詢執行消耗的時間對比,除了場景一基於原始的TPC-DS資料集外,其餘的資料都需要進行資料匯入,同時對比這幾個場景的資料匯入時間。選取資料模型中的store_sales, household_demographics, customer_address, date_dim, store表生成一個扁平式寬表(store_sales_wide_table),基於這個表執行查詢,由於場景一種選擇的query大多數不能完全match到這個寬表,所以對場景1中的SQL進行部分改造。
store_sales_wide_table表記錄數:263,704,266,表大小為:
- 原始Text格式,未壓縮 : 149.0 G
- ORC格式,預設壓縮 : 10.6 G
- PARQUET格式,預設壓縮 : 12.5 G
查詢測試結果:

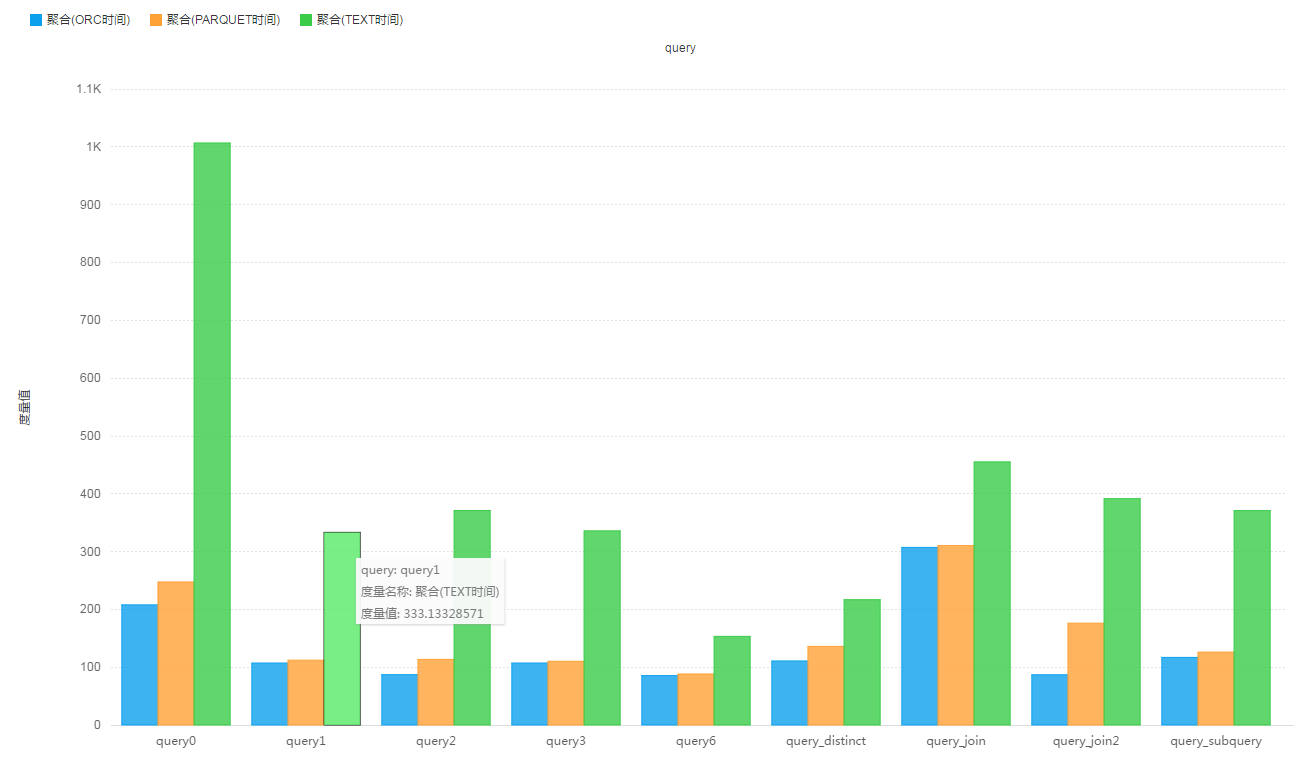
場景三:複雜的資料結構組成的寬表,struct、list、map等(1層)
整個測試設定了四種場景,每一種場景下對比測試資料佔用的儲存空間的大小和相同查詢執行消耗的時間對比,除了場景一基於原始的TPC-DS資料集外,其餘的資料都需要進行資料匯入,同時對比這幾個場景的資料匯入時間。在場景二的基礎上,將維度表(除了store_sales表)轉換成一個struct或者map物件,源store_sales表中的欄位保持不變。生成有一層巢狀的新表(store_sales_wide_table_one_nested),使用的查詢邏輯相同。
store_sales_wide_table_one_nested表記錄數:263,704,266,表大小為:
- 原始Text格式,未壓縮 : 245.3 G
- ORC格式,預設壓縮 : 10.9 G 比store_sales表還小?
- PARQUET格式,預設壓縮 : 29.8 G
查詢測試結果:
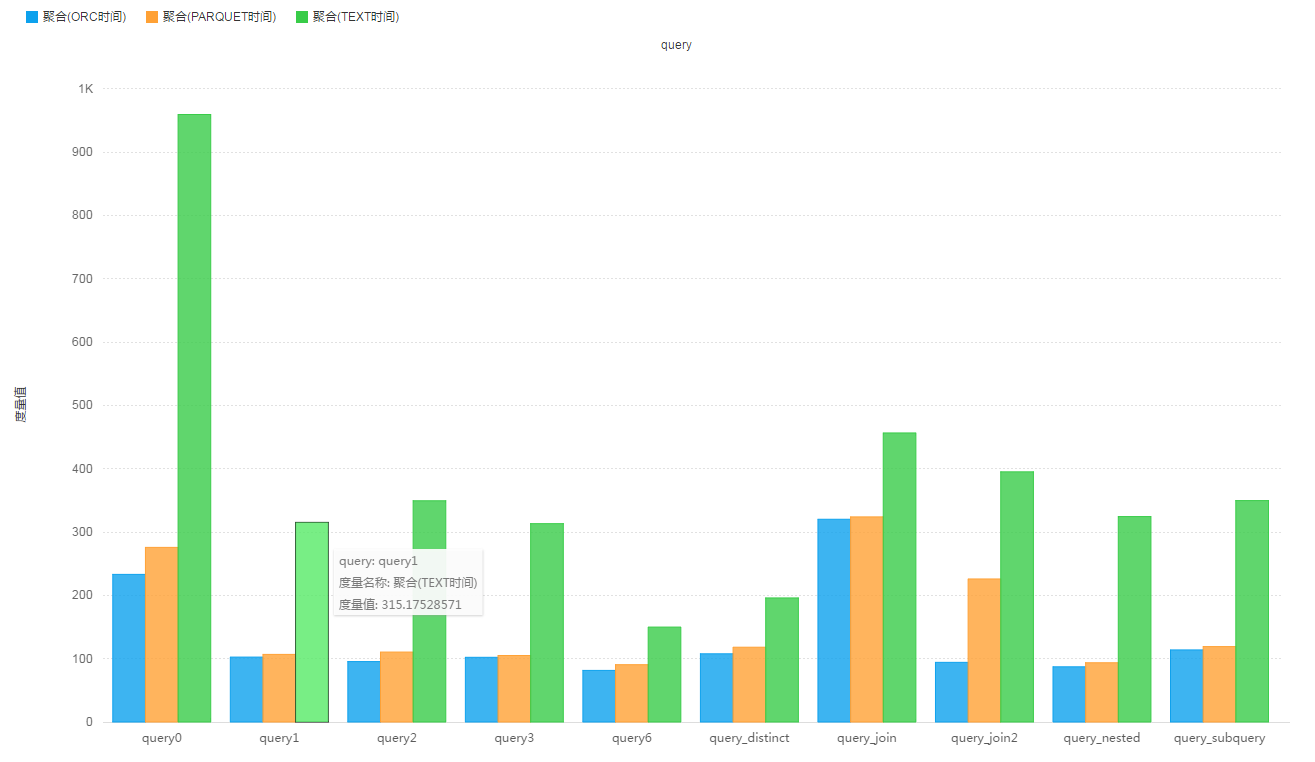
場景四:複雜的資料結構,多層巢狀。(3層)
整個測試設定了四種場景,每一種場景下對比測試資料佔用的儲存空間的大小和相同查詢執行消耗的時間對比,除了場景一基於原始的TPC-DS資料集外,其餘的資料都需要進行資料匯入,同時對比這幾個場景的資料匯入時間。在場景三的基礎上,將部分維度表的struct內的欄位再轉換成struct或者map物件,只存在struct中巢狀map的情況,最深的巢狀為三層。生成一個多層巢狀的新表(store_sales_wide_table_more_nested),使用的查詢邏輯相同。
該場景中只涉及一個多層巢狀的寬表,沒有任何分割槽欄位,store_sales_wide_table_more_nested表記錄數:263,704,266,表大小為:
- 原始Text格式,未壓縮 : 222.7 G
- ORC格式,預設壓縮 : 10.9 G 比store_sales表還小?
- PARQUET格式,預設壓縮 : 23.1 G 比一層巢狀表store_sales_wide_table_one_nested要小?
查詢測試結果:
結果分析
從上述測試結果來看,星狀模型對於資料分析場景並不是很合適,多個表的join會大大拖慢查詢速度,並且不能很好的利用列式儲存帶來的效能提升,在使用寬表的情況下,列式儲存的效能提升明顯,ORC檔案格式在儲存空間上要遠優於Text格式,較之於PARQUET格式有一倍的儲存空間提升,在導資料(insert into table select 這樣的方式)方面ORC格式也要優於PARQUET,在最終的查詢效能上可以看到,無論是無巢狀的扁平式寬表,或是一層巢狀表,還是多層巢狀的寬表,兩者的查詢效能相差不多,較之於Text格式有2到3倍左右的提升。
另外,通過對比場景二和場景三的測試結果,可以發現扁平式的表結構要比巢狀式結構的查詢效能有所提升,所以如果選擇使用大寬表,則設計寬表的時候儘可能的將表設計的扁平化,減少巢狀資料。
通過這三種檔案儲存格式的測試對比,ORC檔案儲存格式無論是在空間儲存、導資料速度還是查詢速度上表現的都較好一些,並且ORC可以一定程度上支援ACID操作,社群的發展目前也是Hive中比較提倡使用的一種列式儲存格式,另外,本次測試主要針對的是Hive引擎,所以不排除存在Hive與ORC的敏感度比PARQUET要高的可能性。
總結
本文主要從資料模型、檔案格式和資料訪問流程等幾個方面詳細介紹了Hadoop生態圈中的兩種列式儲存格式——Parquet和ORC,並通過大資料量的測試對兩者的儲存和查詢效能進行了對比。對於大資料場景下的資料分析需求,使用這兩種儲存格式總會帶來儲存和效能上的提升,但是在實際使用時還需要針對實際的資料進行選擇。另外由於不同開源產品可能對不同的儲存格式有特定的優化,所以選擇時還需要考慮查詢引擎的因素。
相關推薦
Parquet與ORC:高效能列式儲存格式
背景 隨著大資料時代的到來,越來越多的資料流向了Hadoop生態圈,同時對於能夠快速的從TB甚至PB級別的資料中獲取有價值的資料對於一個產品和公司來說更加重要,在Hadoop生態圈的快速發展過程中,湧現了一批開源的資料分析引擎,例如Hive、Spark SQL
【思維導圖】Parquet Orc CarbonData 三種列式儲存格式對比
Parquet Orc CarbonData三種儲存格式對比。 特點: 1.都有row group 的概念。沒有整個列儲存在一個數據結構中。而是按多少行,區分了一下。 2.carbonData 相
深入分析Parquet列式儲存格式
Parquet是面向分析型業務的列式儲存格式,由Twitter和Cloudera合作開發,2015年5月從Apache的孵化器裡畢業成為Apache頂級專案,最新的版本是1.8.0。 列式儲存 列式儲存和行式儲存相比有哪些優勢呢? 可以跳過不符合條件的資料,只讀取需要的資料,降低I
HDFS列式儲存Parquet與行式儲存(Avro)效能測試-Benchmark(hadoop, Spark, Scala)
關於Parquet Parquet是面向分析型業務的列式儲存格式,由Twitter和Cloudera合作開發,2015年5月從Apache的孵化器裡畢業成為Apache頂級專案,細節請參考http://parquet.apache.org/documentation/
(轉載)列式儲存與行式儲存
1 為什麼要按列儲存 列式儲存(Columnar or column-based)是相對於傳統關係型資料庫的行式儲存(Row-basedstorage)來說的。簡單來說兩者的區別就是如何組織表(翻譯不好,直接抄原文了): Ø Row-based storage stor
Hive部分:行式儲存和列式儲存的比較
行式儲存和列式儲存的比較: 列式儲存(Columnar or column-based)是相對於傳統關係型資料庫的行式儲存(Row-basedstorage)來說的。簡單來說兩者的區別就是如何組織表: Ø Row-based storage stores atabl
重點技術-20181001-記憶體級列式儲存Tablesaw的使用
Tablesaw是一個高效能得記憶體資料表,在Java 中主要用於資料操作和列式資料儲存。 ---------------------Maven引入--------------------- <dependency>
資料庫為什麼會分為“行式儲存”和“列式儲存”呢?
我們知道 當今的資料處理大致可分為兩大類 聯機事務處理 OLTP (on-line transaction processing) 以及聯機分析處理 OLAP (On-Line Analytical Processing) OLTP 是傳統關係型資料庫的主要應用 用來執行一些基本的、日常的事務處
幾張圖看懂列式儲存
最近看到一篇很好資料,裡面三言兩語配上幾個圖就把列式儲存(Column-based Storage)講明白了,牛啊!最喜歡的就是這種淺顯易懂就把背景知識講得明明白白,而不是長篇大論的講概念。1 為什麼要按列儲存列式儲存(Columnar or column-based)是相對
行式儲存和列式儲存的比較
行式儲存的優點: 同一行資料存放在同一個block塊裡面,select * from table_name;資料能直接獲取出來; INSERT/UPDATE比較方便 行式儲存的缺點: 不同型別資料存放在同一個block塊裡面,壓縮效能不好; select id,name
HBase 是列式儲存資料庫嗎
在介紹 HBase 是不是列式儲存資料庫之前,我們先來了解一下什麼是行式資料庫和列式資料庫。 行式資料庫和列式資料庫 在維基百科裡面,對行式資料庫和列式資料庫的定義為:列式資料庫是以列相關儲存架構進行資料儲存的資料庫,主要適合於批量資料處理(OLAP)和即時查詢。相對應的是行式資料庫,資料以行相關的儲存體
五大儲存模型關係模型、鍵值儲存、文件儲存、列式儲存、圖形資料庫
也可以認為是五大資料庫儲存模型。 資料庫市場需要細分,行式資料庫不再滿足所有的需求,而有很多需求需要通過本記憶體資料庫和列式資料庫解決,列式資料庫在資料分析、海量儲存、BI這三個領域有自己獨到。 1. 關係型資料庫(行式資料庫) mysql sybase etc 定義:
作業系統:虛擬頁式儲存管理(缺頁中斷、頁面置換演算法)
1、基本工作原理 1、基本工作原理 在程序開始執行之前,不是全部裝入頁面,而是裝入一個或者零個頁面,之後根據程序執行的需要,動態裝入其他頁面;當記憶體已滿,而又需要裝入 新的頁面時,則根據某種演算法淘
列式儲存資料庫-kudu
一、kudu概念 Apache Kudu是由Cloudera開源的儲存引擎,可以同時提供低延遲的隨機讀寫和高效的資料分析能力。Kudu支援水平擴充套件,使用Raft協議進行一致性保證,並且與Cloudera Impala和Apache Spark等當前流行的大資料查詢和分析工具結合緊密。 這是一個為塊資料的快
Hbase與Oracle比較(列式資料庫與行式資料庫)
1 主要區別 1.1、Hbase適合大量插入同時又有讀的情況 1.2、 Hbase的瓶頸是硬碟傳輸速度,Oracle的瓶頸是硬碟尋道時間。 Hbase本質上只有一種操作,就是插入,其更新操作是插入一個帶有新的時間戳的行,而刪除是插入一個帶有插入標記的行。其主要操作是收集
資料庫參考,鍵值(Key-value)資料庫,列式儲存,文件型資料庫,圖型資料庫
【TechTarget中國原創】DB-Engines網站專門提供資料庫管理系統流行度的排名資訊,這個排名主要根據5個因素來進行:Google以及Bing搜尋引擎的關鍵字搜尋數量、Google Trends的搜尋數量、Indeed網站中的職位搜尋量、LinkedIn中提到關鍵字的個人資料數以及Stacko
你應該知道一些其他儲存——列式儲存
導讀:在講《Apache Druid 底層儲存設計》時就說過要講一講列式儲存。現在來了,通過本文你可以瞭解到行儲存模式、列儲存模式、它們的優缺點以及列儲存模式的優化等知識。 今日格言:不要侷限於單向思維,多對比了解更多不同維度的東西。 從資料儲存講起 我們最先接觸的資料庫系統,大部分都是行儲存系統。大
JAVAEE學習——struts2_03:OGNL表達式、OGNL與Struts2的結合和練習:客戶列表
數據 setvalue mage 工作 準備 nor fig 存在 dir 一、OGNL表達式 1.簡介 OGNL:對象視圖導航語言. ${user.addr.name} 這種寫法就叫對象視圖導航。 OGNL不僅僅可以視圖導航.支持比EL表達式更加豐富的功能
拉開大變革序幕(下):分布式計算框架與大數據
ble itl skip 下一代 .bashrc add sum 輸出 sda 由於對大數據處理的需求。使得我們不斷擴展計算能力,集群計算的要求導致分布式計算框架的誕生。用便宜的集群計算資源在短短的時間內完畢以往數周甚至數月的執行等待,有人說誰掌握了龐大
Zookeeper詳解(一):分布式與Zookeeper
zookeeper介紹 分布式 保留本文出自 “小惡魔的家” 博客,請務必保留此出處http://littledevil.blog.51cto.com/9445436/1983260Zookeeper詳解(一):分布式與Zookeeper