
Pandas之資料標準化
Python資料分析博文彙總
資料標準化:將資料按比例縮放,使之落入到特定區間,一般我們使用0-1標準化。
公式:X=(x-min)/(max-min)
from pandas import read_csv;
df = read_csv("E:\\pythonlearning\\datacode\\firstpart\\4\\4.14\\data.csv");
scale = (df.score-df.score.min())/(df.score.max()-df.score.min())
df['scale']=scale執行前三行得:
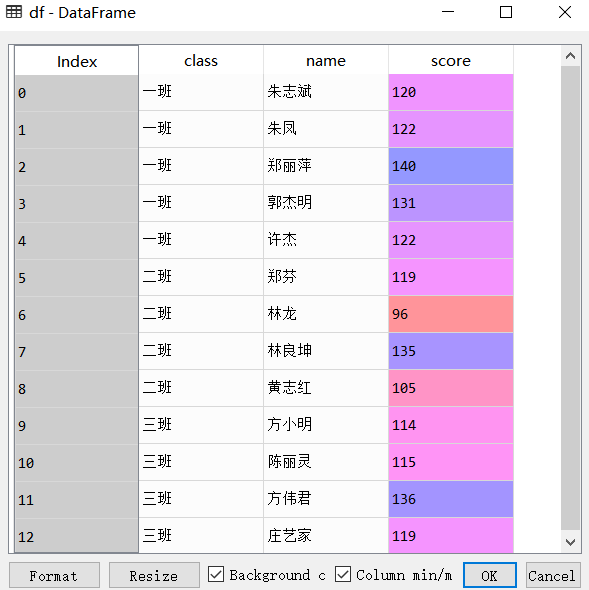
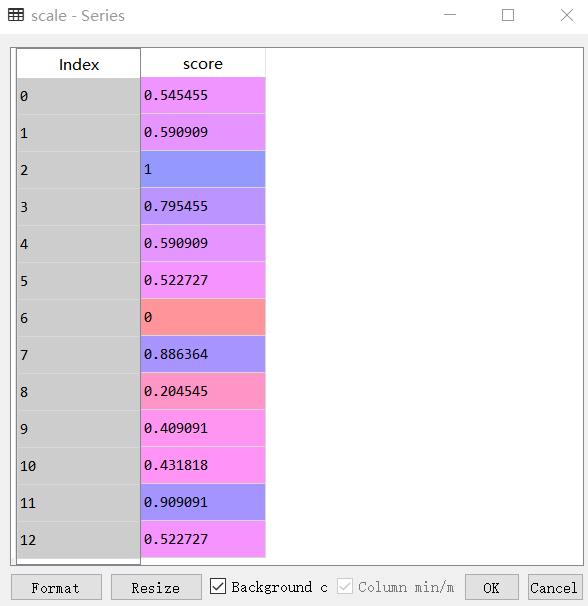
再執行第四行得:

原始碼:https://download.csdn.net/download/w_weiying/10427108
相關推薦
Pandas之資料標準化
Python資料分析博文彙總資料標準化:將資料按比例縮放,使之落入到特定區間,一般我們使用0-1標準化。公式:X=(x-min)/(max-min)from pandas import read_csv; df = read_csv("E:\\pythonlearning\\
機器學習之資料標準化處理
機器學習之資料標準化處理 # -*- coding: utf-8 -*- """ Created on Sat Dec 8 16:41:32 2018 @author: muli """ from sklearn.preprocessing import MinM
機器學習 --2 特徵預處理 之 資料標準化
歸一化: API位置 sklearn.preprocessing 歸一化: 特點:通過對原始資料進行變換把資料對映到(預設為[0,1])之間 注意也可以通過指定MinMaxScalar 裡邊的feature_range 來指定縮放的範圍 示例程式碼
資料預處理之資料標準化
資料標準化的意義 在對資料集建模前,常常要對資料的某一特徵或幾個特徵進行規範化處理,其目的在於將特徵值歸一到同一個維度,消除比重不平衡的問題。 常用的標準化方法有 最大-最小標準化、零-均值標準化 和 小數定標標準化。 最大-最小標準化 最大-最小標準化
pandas 之資料的簡單處理和排序輸出
import pandas as pd from pandas import DataFrame, Series #要排序,需新增 data_4= pd.read_csv('(result-4)句網綜合-pandas.csv',usecols=[0,3],heade
pandas之DataFrame資料框
DataFrame資料框 1.建立資料框 df = DataFrame({ 'age':[21,22,23], 'name':['zhangYafei','LiuGeliang','KangYue'] },index=['fir
Python資料處理之(十 一)Pandas 選擇資料
首先先建立一個6X4的矩陣 >>> import pandas as pd >>> import numpy as np >>> dates=pd.date_range('20181121',periods=6) >>
Python Pandas 做資料分析之玩轉 Excel 報表分析
Python Pandas 是大資料分析的基礎,這裡將分享和Excel報表相關的分析技巧,都是工作中的實戰內容。 本場 Chat 主要內容: Excel、CSV 資料的讀、寫、儲存; DataFrame 的 Index、Columns 相關操作; loc、iloc、XS 和 Mul
pandas 中DataFrame使用:資料標準化、資料分組、日期轉換、日期格式化、日期抽取
1資料標準化 將資料按比例縮放,使之落入到特定區間,一般我們使用0-1標準化。公式如下: X∗=x−minmax−minX∗=x−minmax−min #導包 import pandas; from pandas import read_csv df=read_c
python資料分析處理庫-Pandas之Series結構及Series常用操作方法
我上上篇部落格說過:Pandas資料結構為DataFrame,裡面可以同時是int、float、object(string型別時)、datatime、bool資料型別。而構成DataFrame結構的每一
python pandas 之 Dataframe 資料結構
DataFrame 是 pandas 中兩個主要資料結構之一,另一個是 Series。DataFrame 的文件在這裡:傳送門。 因為這幾天需要使用這個資料結構來完成一個小作業,在這裡總結一下 Dataframe 的一些基本用法。 文章目錄 建立
pandas之算數運算和資料對齊--帶有重複值的軸索引
s1=Series([7.3,-2.5,3.4,1.5],index=['a','c','d','e']) s2=Series([-2.1,3.6,-1.5,4,3.1],index=['a','c','e','f','g']) s1 s2 s1+s s1+s
Pandas之iris資料集簡單分析
匯出iris資料集 from sklearn import datasets import pandas as np iris_datas = datasets.load_iris() ir
pandas之重排分級資料到整數索引
# coding: utf-8 import sys; print('Python %s on %s' % (sys.version, sys.platform)) sys.path.extend(['F:\\c++\\callGBDT', 'F:/c++/c
python 資料處理學習pandas之DataFrame(三)
請原諒沒有一次寫完,本文是自己學習過程中的記錄,完善pandas的學習知識,對於現有網上資料的缺少和利用python進行資料分析這本書部分知識的過時,只好以記錄的形勢來寫這篇文章.最如果後續工作定下來有時間一定完善pandas庫的學習,請見諒!
python處理資料的風騷操作[pandas 之 groupby&agg]
介紹每隔一段時間我都會去學習、回顧一下python中的新函式、新操作。這對於你後面的工作是有一定好處的。本文重點介紹了pandas中groupby、Grouper和agg函式的使用。這2個函式作用類似,都是對資料集中的一類屬性進行聚合操作,比如統計一個使用者在每個月內的全部花
pandas 之 to_csv 儲存資料出現中文亂碼問題及解決辦法
1. 使用scrapy框架爬取了一些汽車評價儲存在csv檔案中,但是直接開啟時亂碼了。2. 使用pandas讀取再使用to_csv()方法重新儲存import pandas as pd file_name = 'G:/myLearning/pythonML201804/s
Python資料分析之pandas基本資料結構:Series、DataFrame
1引言 本文總結Pandas中兩種常用的資料型別: (1)Series是一種一維的帶標籤陣列物件。 (2)DataFrame,二維,Series容器 2 Series陣列 2.1 Series陣列構成 Series陣列物件由兩部分構成: 值(value):一維陣列的各元素值,是一個ndarr
OpenCV之資料分享
tps article www. blank org 圖像濾波 arc htm 有用 分享一些有用的資料鏈接: OpenCV入門教程:http://blog.csdn.net/column/details/opencv-tutorial.html OpenCV入門教程(組件
pandas之系列操作
nec mysq error from div conn excel soft exc 1.讀庫到Excel: 1 # coding=utf-8 2 import pandas as pd 3 import pymysql 4 sql_select =" SELECT *