
深度學習之五:序列模型與詞向量
阿新 • • 發佈:2019-01-19
1 迴圈序列模型
1.1 序列模型的適用範圍
序列模型是一種用於處理序列資料的模型,它可以用於語音識別,音樂生成,情感分類,機器翻譯,命名實體識別等。模型的輸出也可能是一個序列。
1.2 相關的符號約定
表示輸入序列中的第k個元素
表示輸出序列中的第k個元素
表示第i個輸入序列中的第k個元素
表示第i個輸出序列中的第k個元素
表示輸入序列的長度
表示第i個輸入序列的長度
表示輸出序列的長度
表示第i個輸出序列的長度
1.3 RNN模型
1.3.1 詞的one-hot表示
構造一個詞彙表(也稱為詞典),若詞彙個數為n,詞(word)在詞典中的位置i記作,則詞可表示為一個長度為n的一維向量,向量中第位置的元素為1,其他位置為0。
1.3.2 模型示意
在處理序列資料時,由於輸入和輸出長度的不同,且序列模型的維度過高,引數過多,無法使用傳統的全聯接神經網路來處理,因此必須要使用新的序列化的模型。見下圖:
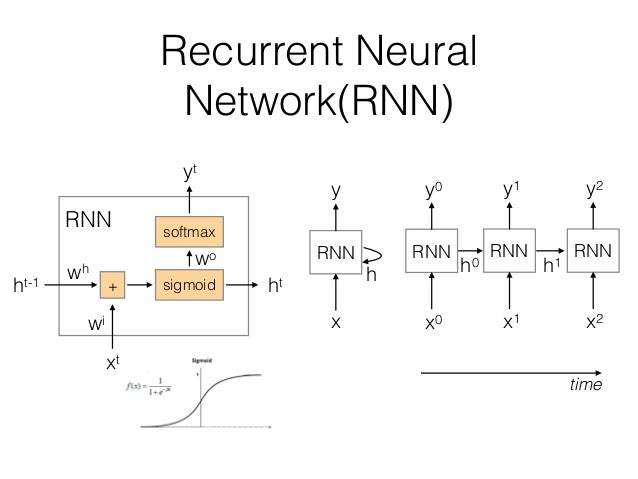
在圖中,RNN單元在時刻接收輸入併產生輸出。在下一個時刻,RNN單元同時接收輸入 和上一個時刻的輸出,從而產生本時刻的輸出。這使得RNN可以考慮歷史輸入的影響。
1.3.3 前向傳播
從上圖的RNN單元的結構中,可以推導前向傳播的計算公式
可以將橫向堆疊,將縱向堆疊,則公式改寫為:
1.3.4 RNN前向傳播實現
# 實現單個RNN單元內部的計算 1.3.4 損失函式
單個樣本的損失函式定義為: