
Python開發Spark應用之Wordcount詞頻統計
待我學有所成,結髮與蕊可好。@夏瑾墨
一個早上只做了一點微小的工作,很懺愧。但是發現Spark這玩意還是蠻有意思的。下面給大家介紹一下如何用python跑一遍Wordcount的詞頻統計的示例程式。
#在pyspark模組中引入SparkContext和SparkConf類
#在operator模組中匯入add類
from pyspark import SparkContext, SparkConf
from operator import add
#應用程式名
#初始化一個SparkContext,現在sc就是一個SparkContext的例項化物件,然後方可建立RDD。 背景知識
1.任何Spark程式的編寫都是從SparkContext(或用Java編寫時的JavaSparkContext)開始的,SparkContext的初始化需要一個SparkConf物件,Sparkconf包括了Spark叢集配置的各種引數(比如主節點的URL)。初始化後,就可以用SparkContext物件所包含的各種方法來建立,操作分散式資料集和共享變數。
2.涉及的函式
- Python split()方法:通過指定分隔符對字串進行切片,如果引數num 有指定值,則僅分隔 num 個子字串。
- Python strip() 方法:用於移除字串頭尾指定的字元(預設為空格)。
- Python lambda()方法:用來建立匿名函式,lambda的主體是一個表示式,用來封轉有限的邏輯進去。
- Python內建的filter()函式 : 用於過濾序列,filter()也接收一個函式和一個序列.
- map( )方法:接收一個函式,應用到RDD中的每個元素,然後為每一條輸入返回一個物件。根據提供的函式對指定序列做對映。
- flatMap( )方法:接收一個函式replaceAndSplit,應用到RDD中的每個元素,返回一個包含可迭代的型別(如list等)的RDD,可以理解為先Map(),後flat(). -
map函式會對每一條輸入進行指定的操作,然後為每一條輸入返回一個物件;而flatMap函式則是兩個操作的集合——正是“先對映後扁平化”:
操作1:同map函式一樣:對每一條輸入進行指定的操作,然後為每一條輸入返回一個物件
操作2:最後將所有物件合併為一個物件
- Spark sortByKey函式 : 作用於Key-Value形式的RDD,並對Key進行排序。它是在org.apache.spark.rdd.OrderedRDDFunctions中實現的.
- take(): Spark的RDD的action操作take()用於提取資料
- parallelize() : 建立一個並行集合,例如sc.parallelize(0 until numMappers, numMappers) 建立並行集合的一個重要引數,是slices的數目(例子中是numMappers),它指定了將資料集切分為幾份.
- Spark主要提供了兩種函式:parallelize和makeRDD:
1)parallelize的宣告:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] 2)makeRDD的宣告:
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T]
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] 3)區別:
A)makeRDD函式比parallelize函式多提供了資料的位置資訊。
B)兩者的返回值都是ParallelCollectionRDD,但parallelize函式可以自己指定分割槽的數量,而makeRDD函式固定為seq引數的size大小。

使用spark-submit執行python檔案,我們選擇使用local模式
以下是詞頻統計結果:
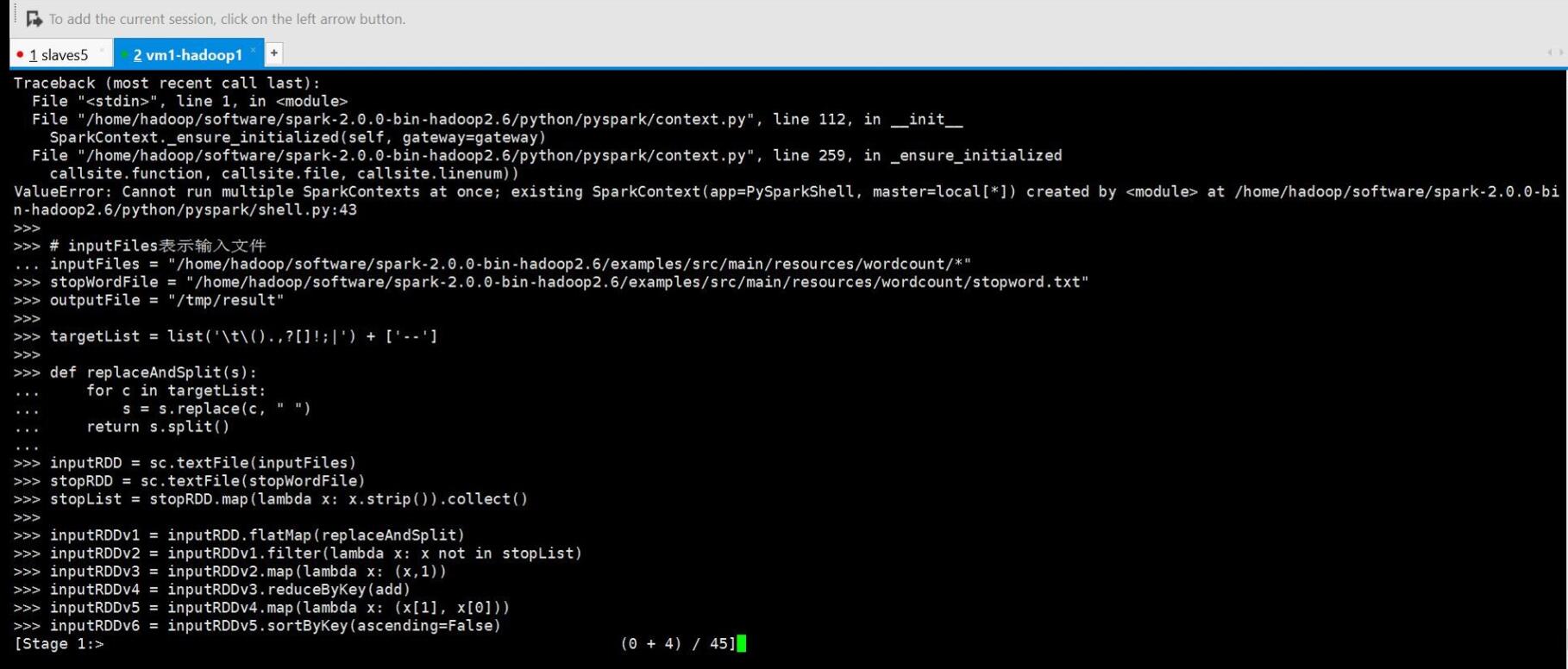
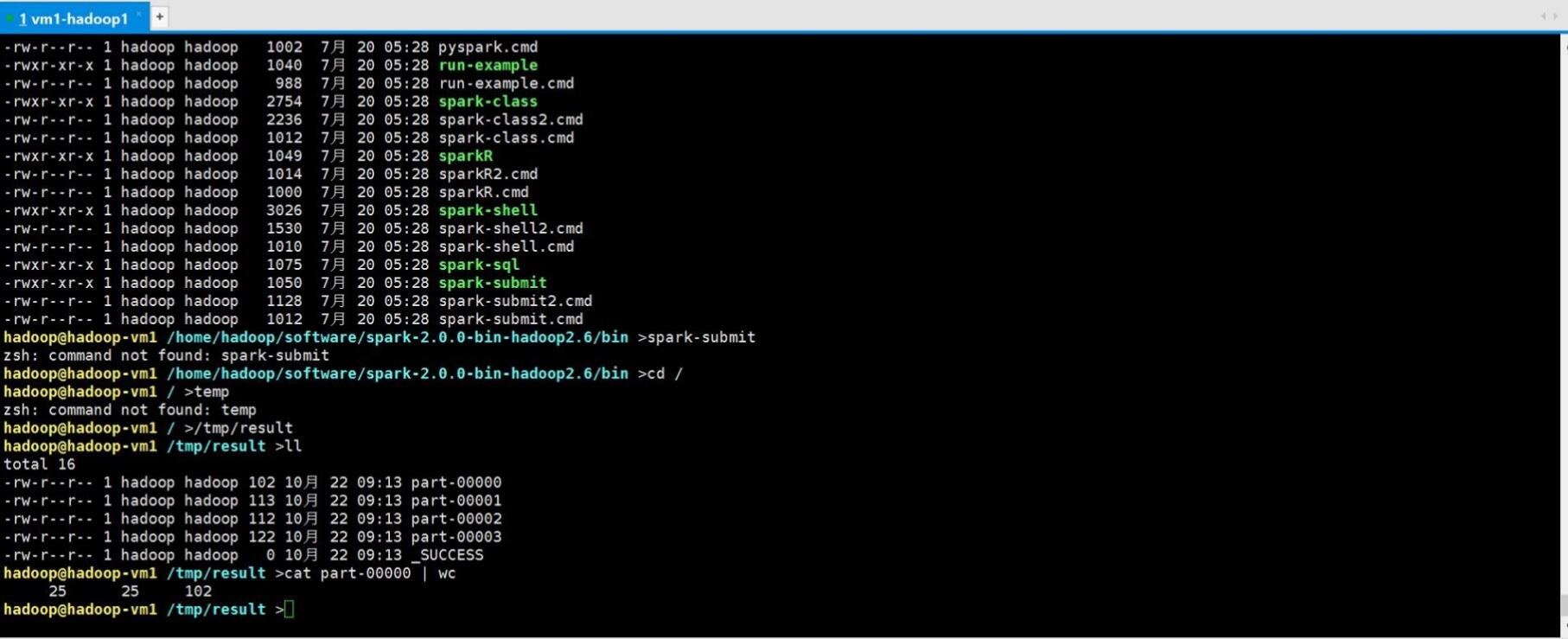
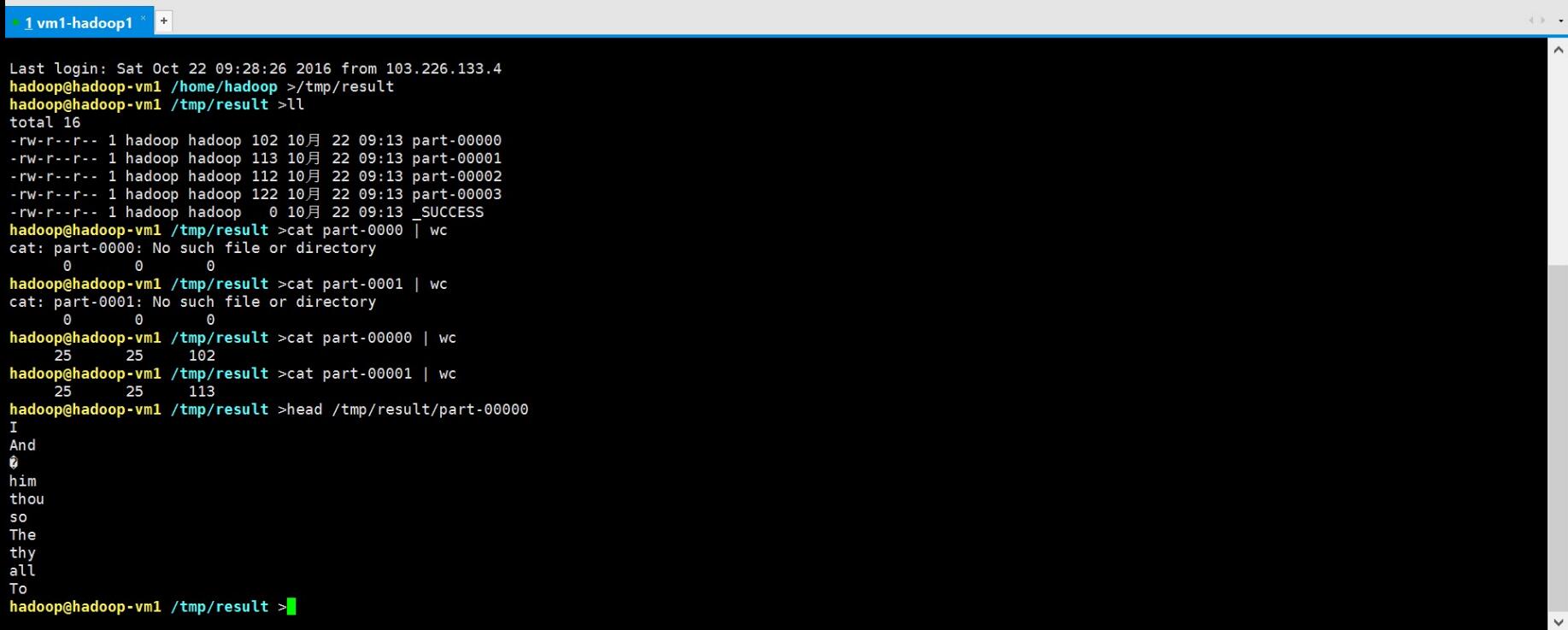
參考資料
待我學有所成,結髮與蕊可好。@夏瑾墨
相關推薦
Python開發Spark應用之Wordcount詞頻統計
待我學有所成,結髮與蕊可好。@夏瑾墨 一個早上只做了一點微小的工作,很懺愧。但是發現Spark這玩意還是蠻有意思的。下面給大家介紹一下如何用python跑一遍Wordcount的詞頻統計的示例程式。 #在pyspark模組中引入SparkCont
spark2.x由淺入深深到底系列五之python開發spark環境配置
spark 大數據 rdd 開發環境 python 學習spark任何的技術前,請先正確理解spark,可以參考: 正確理解spark以下是在mac操作系統上配置用python開發spark的環境一、安裝pythonspark2.2.0需要python的版本是Python2.6+ 或者 P
python開發 隨筆補充之遞歸函數與實例
closed code hid 遞歸函數 span art inpu 但我 重要 遞歸函數 遞歸函數的定義: 1、一個函數在內部調用自己,這就叫遞歸函數 2、遞歸的層數在python裏面是有限制的 3、必須要有一個結束條件 解耦: 要完成一個完整的功能,
Python開發AI應用-國際象棋應用
但是 sid 圖像 節點 互聯 IT 隨機選擇 ech board AI 部分總述 AI在做出決策前經過三個不同的步驟。首先,他找到所有規則允許的棋步(通常在開局時會有20-30種,隨後會降低到幾種)。其次,它生成一個棋步樹用來隨後決定最佳決策。雖然樹的
BigBao 的python開發到DevOps 之路
big targe blog class HA 培訓 ... devops www. 本人是打雜的,從想學Python到自學Python,最後到報班培訓Python路程總共用時兩年,目前在培訓Python。因為我這個大腦不適合自學。腦袋笨,自制力差,所以沒辦法只有乖乖交錢學
Python開發簡單爬蟲之靜態網頁抓取篇:爬取“豆瓣電影 Top 250”電影數據
模塊 歲月 python開發 IE 女人 bubuko status 公司 使用 目標:爬取豆瓣電影TOP250的所有電影名稱,網址為:https://movie.douban.com/top250 1)確定目標網站的請求頭: 打開目標網站,在網頁空白處點擊鼠標右鍵,
IDEA搭建scala開發環境開發spark應用程序
編寫 運行程序 通過 https apach import input inf 搭建 一、idea社區版安裝scala插件 因為idea默認不支持scala開發環境,所以當需要使用idea搭建scala開發環境時,首先需要安裝scala插件,具體安裝辦法如下。 1、
《SpringBoot從入門到放棄》之第(四)篇——開發Web應用之模板Thymeleaf、FreeMarker
SpringBoot提供了預設配置的模板引擎主要有以下幾種:Thymeleaf、FreeMarker、Velocity、Groovy、Mustache 預設的建立SpringBoot專案時,開發工具就幫我們建立好了src/main/resources/static目錄,該位
快速開發跨平臺應用之Xamarin技術
Xamarin 介紹 Xamarin 是一個允許開發人員有效建立可跨 iOS、Android、Windows 應用程式的開發工具集。Xamarin是免費且開源的,遵循 MIT (麻省理工學院許可證)協議,在github上的地址為:https://github.com/x
Spark Streaming整合Spark SQL之wordcount案例
完整原始碼地址: https://github.com/apache/spark/blob/v2.3.2/examples/src/main/scala/org/apache/spark/examples/streaming/SqlNetworkWordCount.scala 案例原
Spring Boot(20)---開發Web應用之JSP篇
Spring Boot(20)---開發Web應用之JSP篇 前言 上一篇介紹了Spring Boot中使用Thymeleaf模板引擎,今天來介紹一下如何使用SpringBoot官方不推薦的jsp,雖然難度有點大,但是玩起來還是蠻有意思的。 正文 先來看看整體的框架
Spring Boot(19)---開發Web應用之Thymeleaf篇
Spring Boot(19)---開發Web應用之Thymeleaf篇 前言 Web開發是我們平時開發中至關重要的,這裡就來介紹一下Spring Boot對Web開發的支援。 正文 Spring Boot提供了spring-boot-starter-web為Web
Hadoop之Wordcount流量統計入門例項
一:何為MapReduce HDFS和MapReduce是Hadoop的兩個重要核心,其中MR是Hadoop的分散式計算模型。MapReduce主要分為兩步Map步和Reduce步,引用網上流傳很廣的一個故事來解釋,現在你要統計一個圖書館裡面有多少本書,為了完成這個任務,你可以指派小明去統計書架
maven環境下使用java、scala混合開發spark應用
熟悉java的開發者在開發spark應用時,常常會遇到spark對java的介面文件不完善或者不提供對應的java介面的問題。這個時候,如果在java專案中能直接使用scala來開發spark應用,同時使用java來處理專案中的其它需求,將在一定程度上降低開發spark專案的
Spring Boot乾貨系列:(五)開發Web應用之JSP篇
前言 上一篇介紹了Spring Boot中使用Thymeleaf模板引擎,今天來介紹一下如何使用SpringBoot官方不推薦的jsp,雖然難度有點大,但是玩起來還是蠻有意思的。 正文 先來看看整體的框架結構,跟前面介紹
Spring Boot乾貨系列:(四)開發Web應用之Thymeleaf篇
前言 Web開發是我們平時開發中至關重要的,這裡就來介紹一下Spring Boot對Web開發的支援。 正文 Spring Boot提供了spring-boot-starter-web為Web開
使用C#開發Android應用之WebApp
近段時間瞭解了一下VS2017開發安卓應用的一些技術,特地把C#開發WebApp的一些過程記錄下來, 歡迎大家一起指教、討論,廢話少說,是時候開始表演真正的技術了。。 1、新建空白Android應用 2、拖一個WebView控制元件進來 3、開
Android開發多媒體應用之SoundPool的使用的程式碼
內容過程中,把寫內容過程中比較好的內容段記錄起來,下面的內容是關於Android開發多媒體應用之SoundPool的使用的內容,希望對各位也有用途。 public class MainActivity extends Activity { private Button button1; private
IDEA搭建scala開發環境開發spark應用程式
一、idea社群版安裝scala外掛 因為idea預設不支援scala開發環境,所以當需要使用idea搭建scala開發環境時,首先需要安裝scala外掛,具體安裝辦法如下。 1、開啟idea,點選configure下拉選單中的plugins選項: 2、在彈出對話方塊中點選紅框按鈕: 3、在彈出最新對話
通過IDEA搭建scala開發環境開發spark應用程式
一、idea社群版安裝scala外掛因為idea預設不支援scala開發環境,所以當需要使用idea搭建scala開發環境時,首先需要安裝scala外掛,具體安裝辦法如下。1、開啟idea,點選configure下拉選單中的plugins選項:2、在彈出對話方塊中點選紅框按鈕:3、在彈出最新對話方塊的搜尋欄輸