
Tensorflow第六課--基於L2正則化損失函式的5層神經網路
這幾天一直在看Tensorflow:實戰google深度學習框架。感覺這本書真的寫的很好,尤其是對於Tensorflow之前毫無所知的我,通過這本書也能學懂並且瞭解很多。今天我主要是學習了損失函式。新增損失函式的主要目的是解決在訓練過程中的過擬合問題。正則化的思想就是在損失函式中加入刻畫模型複雜程度的指標。假設用於刻畫模型訓練資料上表現的損失函式是J(a),那麼在優化時不是直接進行優化J(a),而是優化J(a)+bR(w)。R(w)表示刻畫模型的複雜程度,而b表示模型複雜損失在總損失中的比例。a表示一個神經網路中所有的引數,包括權重和偏置值。
L1正則化計算公式:

L2正則化計算公式:
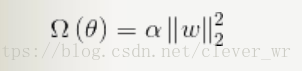
無論是哪個正則化表示方式,其主要目的都是希望通過限制權重的大小,使得模型不能任意的你和訓練資料中的隨機噪音。Tensorflow中集成了正則化損失函式方法。
下面程式碼是利用完整的mnist資料集實現帶有L2正則化函式的5層神經網路程式碼的成功實現,供你們參考。菜菜的我可是用了大半天才執行成功,總是報錯,可能是我對tensorflow還不是很熟悉,但是每次練習都是一個成長的過程。w = tf.Variable(tf.random_normal([2, 1], stddev = 1, seed = 1), dtype=tf.float32) #其中stddev是方差,seed是種子。 y = tf.matmul(x, w) loss = tf.reduce_mean(tf.square(y_ - y) + tf.contrib.layers.l2_regularizer(lamada)(w))
#-*- coding:utf-8 -*- import tensorflow as tf import input_data def get_weight(shape, lamada,session): var = tf.Variable(tf.random_normal(shape,stddev=1.0), dtype=tf.float32) sess.run(tf.global_variables_initializer()) #print sess.run(var) tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(lamada)(var)) return var #input_data:用於訓練和測試的MNIST資料集的原始碼 mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) #download the data of train and testm trainimage = mnist.train.images trainLabel = mnist.train.labels trainimageSize = mnist.train.images.size trainLabelSize = mnist.train.labels.size print trainimageSize,trainLabelSize testimage = mnist.test.images testlabel = mnist.test.labels testimageSize = mnist.test.images.size testlabelSize = mnist.test.labels.size print testimageSize,testlabelSize x = tf.placeholder("float", [None, 784]) layer_dimension = [784, 10, 10, 10, 1] n_layers = len(layer_dimension) y_ = tf.placeholder("float", [None, 1]) # 在機器學習的模型中,我們需要定義一個衡量模型好壞的方式,稱為代價函式(Cost Loss),這裡使用了交叉熵去衡量 reduce_sum 累加 init = tf.initialize_all_variables() with tf.Session() as sess: import numpy as nf sess.run(init) for i in range(1): batch = mnist.train.next_batch(5) # sess.run(train_step, feed_dict={x: batch[0],y_: batch[1]}) for i1 in range(5): print "i1:", i1 #cur_layer = tf.constant([batch[0][i1]],dtype=tf.float32) cur_layer = nf.array([batch[0][i1]], nf.float32) # print cur_layer.tolist() in_dimension = layer_dimension[0] for i2 in range(1, n_layers): print "i2:",i2 out_dimension = layer_dimension[i2] weight = get_weight([in_dimension, out_dimension], 0.001,sess) print "weight:",sess.run(weight) bias = tf.Variable(tf.constant(0.1, shape=[out_dimension])) a = tf.global_variables_initializer() sess.run(a) print "bias",sess.run(bias) print "zhi:",tf.matmul(cur_layer, weight) cur_layer = tf.nn.sigmoid(tf.matmul(cur_layer, weight) + bias) print sess.run(cur_layer) in_dimension = layer_dimension[i2] mse_loss = tf.reduce_mean(tf.square(batch[1][i1] - cur_layer)) tf.add_to_collection('losses', mse_loss) loss = tf.add_n(tf.get_collection('losses')) print sess.run(mse_loss) print sess.run(loss) tf.get_default_graph().clear_collection('losses')
相關推薦
Tensorflow第六課--基於L2正則化損失函式的5層神經網路
這幾天一直在看Tensorflow:實戰google深度學習框架。感覺這本書真的寫的很好,尤其是對於Tensorflow之前毫無所知的我,通過這本書也能學懂並且瞭解很多。今天我主要是學習了損失函式。新增損失函式的主要目的是解決在訓練過程中的過擬合問題。正則化的思想就是在損失函
斯坦福大學(吳恩達) 機器學習課後習題詳解 第六週 程式設計題 正則化線性迴歸以及方差與偏差
作業下載地址:https://download.csdn.net/download/wwangfabei1989/103031341. 正則化線性迴歸代價函式 linearRegCostFunctionfunction [J, grad] = linearRegCostFun
TensorFlow北大公開課學習筆記4.4-神經網路優化----正則化 (正則化損失函式)
今天學習了正則化,主要內容是:通過程式碼比較正則化與不正則化的區別。 什麼叫過擬合? 神經網路模型在訓練資料集上的準確率較高,在新的資料進行預測或分類時準確率較低, 說明模型的泛化能力差 什麼叫正則化:? 在損失函式中給每個引數
[Tensorflow]L2正則化和collection【tf.GraphKeys】
L2-Regularization 實現的話,需要把所有的引數放在一個集合內,最後計算loss時,再減去加權值。 相比自己亂搞,程式碼一團糟,Tensorflow 提供了更優美的實現方法。 一、tf.GraphKeys : 多個包含Variables(Tensor)集合
java作業04(第六章 字串和正則表示式)
有點無聊就先把第六章的兩道賊簡單的題目給做了。 package homework04; import java.util.Scanner; import java.util.regex.Matcher; import java.util.regex.Patte
【tensorflow 學習】給LSTM加上L2正則化
首先,用tf.trainable_variables()得到所有weights和bias, 然後,用tf.nn.l2_loss()計算L2 norm, 求和之後作為正則項加給原來的cost function tv = tf.trainable_vari
L2正則化—tensorflow實現
L2正則化是一種減少過擬合的方法,在損失函式中加入刻畫模型複雜程度的指標。假設損失函式是J(θ),則優化的是J(θ)+λR(w),R(w)=∑ni=0|w2i|。 在tensorflow中的具體實現過
機器學習之路: python線性回歸 過擬合 L1與L2正則化
擬合 python sco bsp orm AS score 未知數 spa git:https://github.com/linyi0604/MachineLearning 正則化: 提高模型在未知數據上的泛化能力 避免參數過擬合正則化常用的方法: 在目
使用L2正則化和平均滑動模型的LeNet-5MNIST手寫數字識別模型
put 輸出矩陣 conv2 cross -m collect variable global 空間 使用L2正則化和平均滑動模型的LeNet-5MNIST手寫數字識別模型 覺得有用的話,歡迎一起討論相互學習~Follow Me 參考文獻Tensorflow實戰Googl
l2-loss,l2範數,l2正則化,歐式距離
access src 梯度 com inf content 開平 nbsp alt 歐式距離: l2範數: l2正則化: l2-loss(也叫平方損失函數): http://openaccess.thecvf.com/content_cvpr_2017/papers
L2正則化項為什麼能防止過擬合學習筆記
https://www.cnblogs.com/alexanderkun/p/6922428.html L2 regularization(權重衰減) L2正則化就是在代價函式後面再加上一個正則化項: C0代表原始的代價函式,後面那一項就是L2正則化項,它是這樣來的:所有引數w的平
L1和L2正則化直觀理解
正則化是用於解決模型過擬合的問題。它可以看做是損失函式的懲罰項,即是對模型的引數進行一定的限制。 應用背景: 當模型過於複雜,樣本數不夠多時,模型會對訓練集造成過擬合,模型的泛化能力很差,在測試集上的精度遠低於訓練集。 這時常用正則化來解決過擬合的問題,常用的正則化有L1正則化和L2
L1,L2正則化
正則化引入的思想其實和奧卡姆剃刀原理很相像,奧卡姆剃刀原理:切勿浪費較多東西,去做,用較少的東西,同樣可以做好的事情。 正則化的目的:避免出現過擬合(over-fitting) 經驗風險最小化 + 正則化項 = 結構風險最小化 經驗風險最小化(ERM),是為了讓擬合的誤差足夠小,即:對訓
L2正則化
#正則化是解決共線性的一個很有用的方法,他可以過濾掉資料中的噪聲,並最終防止過擬合 #正則化就是引入額外的資訊(偏差)對極端權重引數做懲罰。 #特徵縮放(如標準化)很重要的一個原因就是正則化。 #為了使正則化起作用,需要保證所有特徵的衡量標準保持統一。 #使用正則化方法:在代價函式後面加上正則化項
L1正則化和L2正則化
在機器學習中,我們非常關心模型的預測能力,即模型在新資料上的表現,而不希望過擬合現象的的發生,我們通常使用正則化(regularization)技術來防止過擬合情況。正則化是機器學習中通過顯式的控制模型複雜度來避免模型過擬合、確保泛化能力的一種有效方式。如果將模型原始的假設空間比作“天空”,那麼天空飛翔的“鳥
SVM支援向量機系列理論(七) 線性支援向量機與L2正則化 Platt模型
7.1 軟間隔SVM等價於最小化L2正則的合頁損失 上一篇 說到, ξi ξ i \xi_i 表示偏離邊界的度量,若樣本點
批歸一化(Batch Normalization)、L1正則化和L2正則化
from: https://www.cnblogs.com/skyfsm/p/8453498.html https://www.cnblogs.com/skyfsm/p/8456968.html BN是由Google於2015年提出,這是一個深度神經網路訓練的技巧,它不僅可以加快了
NN模型設定--L1/L2正則化
正則化的理解 規則化函式Ω有多重選擇,不同的選擇效果也不同,不過一般是模型複雜度的單調遞增函式——模型越複雜,規則化值越大。 正則化含義中包含了權重的先驗知識,是一種對loss的懲罰項(regularization term that penalizes paramete
L1和L2正則化。L1為什麼能產生稀疏值,L2更平滑
參考部落格:https://zhuanlan.zhihu.com/p/35356992 https://zhuanlan.zhihu.com/p/25707761 https://www.zhihu.com/question/37096933/answer/70426653 首先
訓練過程--正則化(regularization)技巧(包括L2正則化、dropout,資料增廣,早停)
正則化(regularization) 正則化是解決高方差問題的重要方案之一,也是Reducing Overfiltering(克服過擬合)的方法。 過擬合一直是DeepLearning的大敵,它會導致訓練集的error rate非常小,而測試集的error rate大部分時候很