
分散式快取--系列2 -- Redis Cluster
說到Memcached和Redis的區別,我想很多人都會想到下面3點:
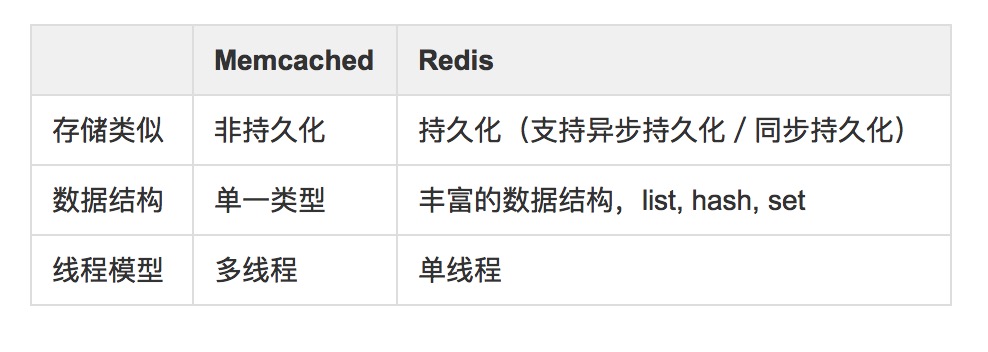
但這都是從“單機角度“來比較。可以說,在redis cluster出來之前,memcached 和 redis 的差別還不算大。(關於Memcached為什麼是多執行緒,而Redis為什麼是單執行緒,這個在後續序列會來探討)
但從Redis 3.0開始,引入了Redis Cluster,從此Redis進入了真正的“分散式叢集“時代。而在“叢集角度“,可以說Redis已經和Memcached有了很多重大的區別。下面這個表,從“叢集角度“比較了2者的重大區別:

P2P架構
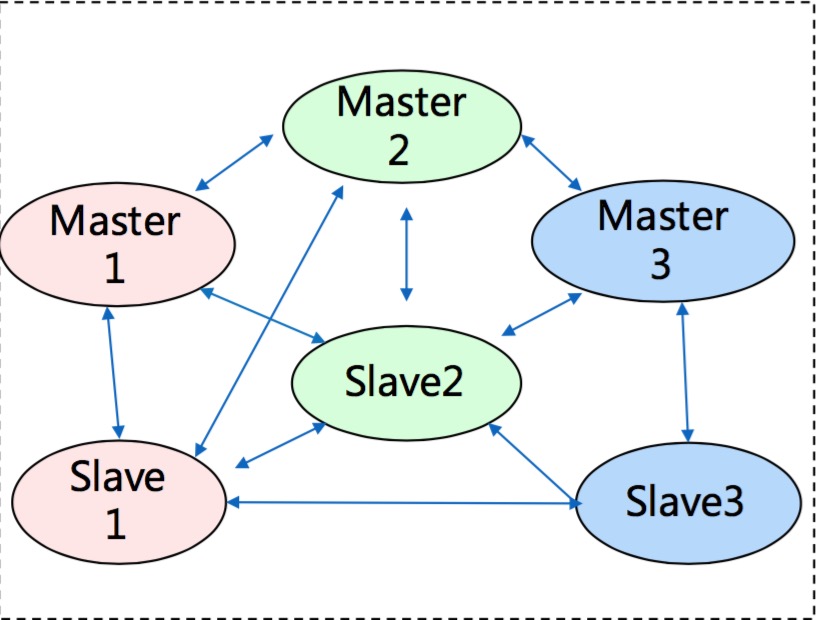
下面這張圖展示了redis-cluster的結點之間的拓撲關係,可以看出它是完全的P2P模式,無中央結點,結點之間通過一個稱之為Gossip的協議進行通訊。
16384個hash槽
不同於Memcached的一致性Hash,Redis準備了16384個hash槽,類似於Memcached Hash環上的一個個位置。
這16384個hash槽被分配給不同節點,存放資料時,根據資料的key計算出所在的槽,再根據槽找到對應的機器。hash函式為:CRC16(key) % 16384。
為什麼是16384?
很顯然,我們需要維護節點和槽之間的對映關係,每個節點需要知道自己有哪些槽,並且需要在結點之間傳遞這個訊息。
為了節省儲存空間,每個節點用一個Bitmap來存放其對應的槽:
2k = 2*1024*8 = 16384,也就是說,每個結點用2k的記憶體空間,總共16384個位元位,就可以儲存該結點對應了哪些槽。然後這2k的資訊,通過Gossip協議,在結點之間傳遞。
客戶端儲存路由資訊
對於客戶端來說,維護了一個路由表:每個槽在哪臺機器上。這樣儲存(key, value)時,根據key計算出槽,再根據槽找到機器。
無損擴容
雖然Hash環可以減少擴容時失效的key的數量,但畢竟有丟失。而在redis-cluster中,當新增機器之後,槽會在機器之間重新分配,同時被影響的資料會自動遷移,從而做到無損擴容。
主從複製
redis-cluster也引入了master-slave機制,從而提供了fail-over機制,這很大程度上解決了“快取雪崩“的問題。關於這個,後面有機會再詳細闡述。