
MapReduce表連線操作之Reduce端join
一:背景
Reduce端連線比Map端連線更為普遍,因為輸入的資料不需要特定的結構,但是效率比較低,因為所有資料都必須經過Shuffle過程。
二:技術實現
基本思路
(1):Map端讀取所有的檔案,並在輸出的內容里加上標示,代表資料是從哪個檔案裡來的。
(2):在reduce處理函式中,按照標識對資料進行處理。
(3):然後根據Key去join來求出結果直接輸出。
資料準備
準備好下面兩張表:
(1):tb_a(以下簡稱表A)
id name
1 北京
2 天津
3 河北
4 山西
5 內蒙古
6 遼寧
7 吉林
8 黑龍江
(2):tb_b(以下簡稱表B)
id statyear num 1 2010 1962 1 2011 2019 2 2010 1299 2 2011 1355 4 2011 3574 4 2011 3593 9 2010 2303 9 2011 2347
#需求就是以id為key做join操作(注:上面的資料都是以製表符“\t”分割)
計算模型
整個計算過程是:
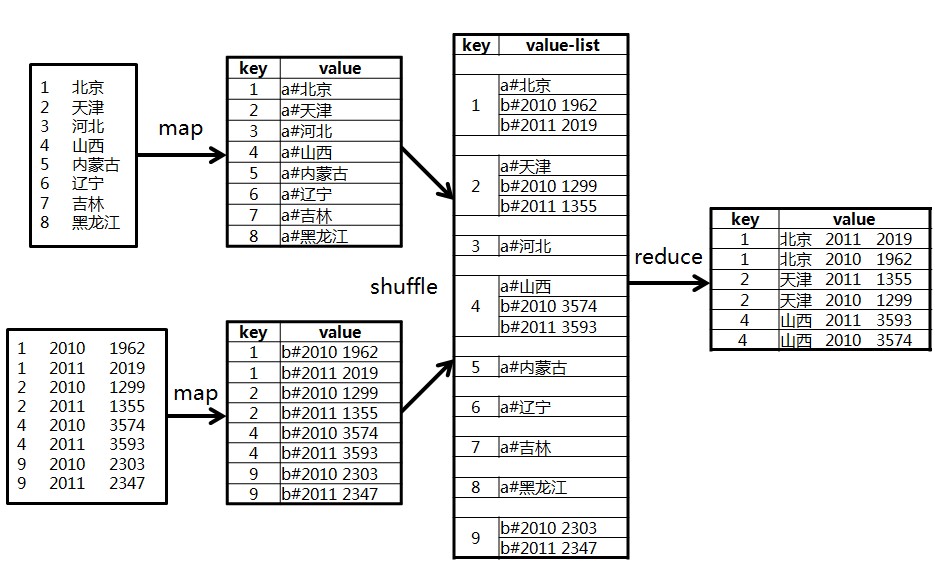
(1):在Map階段,把所有資料標記成<key,value>的形式,其中key是id,value則根據來源不同取不同的形式:來源於A的記錄,value的值為"a#"+name;來源於B的記錄,value的值為"b#"+score。
(2):在reduce階段,先把每個key下的value列表拆分為分別來自表A和表B的兩部分,分別放入兩個向量中。然後遍歷兩個向量做笛卡爾積,形成一條條最終的結果。
如下圖所示:
程式碼實現如下:
public class ReduceJoinTest { // 定義輸入路徑 private static final String INPUT_PATH = "hdfs://liaozhongmin:9000/table_join/tb_*"; // 定義輸出路徑 private static final String OUT_PATH = "hdfs://liaozhongmin:9000/out"; public static void main(String[] args) { try { // 建立配置資訊 Configuration conf = new Configuration(); // 建立檔案系統 FileSystem fileSystem = FileSystem.get(new URI(OUT_PATH), conf); // 如果輸出目錄存在,我們就刪除 if (fileSystem.exists(new Path(OUT_PATH))) { fileSystem.delete(new Path(OUT_PATH), true); } // 建立任務 Job job = new Job(conf, ReduceJoinTest.class.getName()); //1.1 設定輸入目錄和設定輸入資料格式化的類 FileInputFormat.setInputPaths(job, INPUT_PATH); job.setInputFormatClass(TextInputFormat.class); //1.2 設定自定義Mapper類和設定map函式輸出資料的key和value的型別 job.setMapperClass(ReduceJoinMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //1.3 設定分割槽和reduce數量(reduce的數量,和分割槽的數量對應,因為分割槽為一個,所以reduce的數量也是一個) job.setPartitionerClass(HashPartitioner.class); job.setNumReduceTasks(1); //1.4 排序 //1.5 歸約 //2.1 Shuffle把資料從Map端拷貝到Reduce端。 //2.2 指定Reducer類和輸出key和value的型別 job.setReducerClass(ReduceJoinReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); //2.3 指定輸出的路徑和設定輸出的格式化類 FileOutputFormat.setOutputPath(job, new Path(OUT_PATH)); job.setOutputFormatClass(TextOutputFormat.class); // 提交作業 退出 System.exit(job.waitForCompletion(true) ? 0 : 1); } catch (Exception e) { e.printStackTrace(); } } public static class ReduceJoinMapper extends Mapper<LongWritable, Text, Text, Text>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { //獲取輸入檔案的全路徑和名稱 FileSplit fileSplit = (FileSplit) context.getInputSplit(); String path = fileSplit.getPath().toString(); //獲取輸入記錄的字串 String line = value.toString(); //拋棄空記錄 if (line == null || line.equals("")){ return; } //處理來自tb_a表的記錄 if (path.contains("tb_a")){ //按製表符切割 String[] values = line.split("\t"); //當陣列長度小於2時,視為無效記錄 if (values.length < 2){ return; } //獲取id和name String id = values[0]; String name = values[1]; //把結果寫出去 context.write(new Text(id), new Text("a#" + name)); } else if (path.contains("tb_b")){ //按製表符切割 String[] values = line.split("\t"); //當長度不為3時,視為無效記錄 if (values.length < 3){ return; } //獲取屬性 String id = values[0]; String statyear = values[1]; String num = values[2]; //寫出去 context.write(new Text(id), new Text("b#" + statyear + " " + num)); } } public static class ReduceJoinReducer extends Reducer<Text, Text, Text, Text>{ @Override protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException { //用來存放來自tb_a表的資料 Vector<String> vectorA = new Vector<String>(); //用來存放來自tb_b表的 Vector<String> vectorB = new Vector<String>(); //迭代集合資料 for (Text val : values){ //將集合中的資料對應新增到Vector中 if (val.toString().startsWith("a#")){ vectorA.add(val.toString().substring(2)); } else if (val.toString().startsWith("b#")){ vectorB.add(val.toString().substring(2)); } } //獲取兩個Vector集合的長度 int sizeA = vectorA.size(); int sizeB = vectorB.size(); //遍歷兩個向量將結果寫出去 for (int i=0; i<sizeA; i++){ for (int j=0; j<sizeB; j++){ context.write(key, new Text(" " + vectorA.get(i) + " " + vectorB.get(j))); } } } } } }
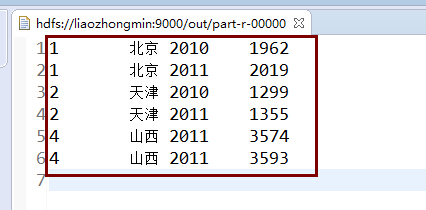
程式執行的結果:
細節:
(1):當map讀取原始檔時,如何區分出是file1還是file2?
FileSplit fileSplit = (FileSplit)context.getInputSplit();
String path = fileSplit.getPath().toString();相關推薦
MapReduce表連線操作之Reduce端join
一:背景 Reduce端連線比Map端連線更為普遍,因為輸入的資料不需要特定的結構,但是效率比較低,因為所有資料都必須經過Shuffle過程。 二:技術實現 基本思路 (1):Map端讀取所有的檔案,並在輸出的內容里加上標示,代表資料是從哪個檔案裡來的。 (2):在red
圖解Oracle 表連線優化之巢狀迴圈連線(Nested loops join)
當一條SQL語句引用多張表連線時,Oracle的查詢優化器(Optimizer)不僅要確定每張表的訪問路徑,而且需要確定這些表的連線順序和連線方法。查詢優化器的目標是通過儘早地過濾不需要的資料,減少需要處理的資料量。 Oracle的SQL優化器(Optimizer)在執行
Oracle表連線操作——Nest Loop Join(巢狀迴圈)
關係型資料庫並不是最早出現的資料庫表現形式,之前還存在層次、網狀資料庫結構。隨著關係型資料庫的出現,以資料表的方式進行資訊留存的方案迅速發展起來。關係型資料庫的重要元素包括資料表和表連線,藉助各種型別的表連線,可以將平鋪直敘的資訊加以組裝拼接。在Oracle資料庫中,應對不同
Hadoop應用——Reduce端Join操作
聯接 使用案例 Table EMP: Name Sex Age DepNo zhang male 20 1 li female 25 2 wang female 30 3 zhou male 35 2 Ta
MapReduce中的join演算法-reduce端join
在海量資料的環境下,不可避免的會碰到join需求, 例如在資料分析時需要連線從不同的資料來源中獲取到資料。 假設有兩個資料集:氣象站資料庫和天氣記錄資料庫,並考慮如何合二為一。 一個典型的查詢是:輸出氣象站的歷史資訊,同時各行記錄也包含氣象站的元資料資訊。 氣象站
Reduce端join演算法實現 - (訂單跟商品)
程式碼地址: https://gitee.com/tanghongping/hadoopMapReduce/tree/master/src/com/thp/bigdata/rjon 現在有兩張表 1.訂單表 2.商品表 訂單資料表t_order: id
MySQL多表連線操作
1 select * from userinfo ,dapartment where userinfo.part_id = dapartment.id; 2 --左連線: 左邊全部顯示 3 select * from userinfo left join dapartment on
資料結構學習(二)——單鏈表的操作之頭插法和尾插法建立連結串列
連結串列也是線性表的一種,與順序表不同的是,它在記憶體中不是連續存放的。在C語言中,連結串列是通過指標相關實現的。而單鏈表是連結串列的其中一種,關於單鏈表就是其節點中有資料域和只有一個指向下個節點的指標域。建立單鏈表的方法有兩種,分別是頭插法和尾插法。 所謂頭插法,就是按節
hadoop streaming reduce端join的python兩種實現方式
實現student和course資料表的join操作,以學生編號(sno)為連線欄位 測試資料 student.txt檔案 #以一個空格分隔 #學生編號 姓名 #sno sname 01 lily 02 tom 03 jac
資料結構學習(四)——迴圈單鏈表的操作之合併
所謂迴圈連結串列就是尾結點與頭結點相連的連結串列,整個連結串列形成一個環。而對於迴圈連結串列的插入與刪除運算,基本上與單鏈表相同,只是在判斷連結串列是否結束有所不同。下面的程式碼操作實現了兩個迴圈單鏈表的合併。且核心程式碼不多,主要是分別找到迴圈單鏈表的尾結點再進行後續操作
Spark RDD Actions操作之reduce()
textFile.map(line => line.split(" ").size).reduce((a, b) => if (a > b) a else b) The argu
C/C++學習(九)迴圈雙鏈表的操作之建立,插入、刪除
雙向連結串列 迴圈單鏈表的出現,雖然能夠實現從任一結點出發沿著鏈能找到其前驅結點,但時間耗費是O(n)。如果希望從表中快速確定某一個結點的前驅,另一個解決方法就是在單鏈表的每個結點裡再增加一個指向其
MapReduce之Reduce Join
一 介紹 Reduce Join其主要思想如下: 在map階段,map函式同時讀取兩個檔案File1和File2,為了區分兩種來源的key/value資料對,對每條資料打一個標籤(tag), 比如:tag=0表示來自檔案File1,tag=2表示來自檔案File2。即:map階段的主要任務是對不同
python之sorted、map、reduce、join、split函式的例項操作
sorted 資料如下: key為選擇需要排序的元素;reverse為True,表示逆序排序。 reverse為False,表示順序排序。 map 資料如下。 按lambda表示式操作。 reduce 按lambda表示式操作
mapreduce演算法之reduce側連線
package mapreduce_join; import java.io.IOException; import java.net.URI; import java.util.HashMap; import java.util.Map; import org.apach
深入理解Oracle表(5):三大表連線方式詳解之Hash Join的定義,原理,演算法,成本,模式和點陣圖
Hash Join只能用於相等連線,且只能在CBO優化器模式下。相對於nested loop join,hash join更適合處理大型結果集 Hash Join的執行計劃第1個是hash表(build table),第2個探查表(probe table),
MapReduce之連線操作類應用
用MapReduce實現關係的自然連線 假設有關係R(A,B)和S(B,C),對二者進行自然連線操作 使用Map過程,把來自R的每個元組<a,b>轉換成一個鍵值對<b, <R,a>>,其中的鍵就是屬性B的值。把關係R包
sql語句-關於自身表連線之join與left join
1、建立表 drop table if exists t_user; create table t_user( id int(11) not null auto_increment, user_id int(11), user_name varchar(100),
大資料案例(七)——MapReduce之map端表合併(Distributedcache)
一、前期準備 由於本案例是在案例六的基礎上做的優化,所以需求及資料輸入輸出請參考案例六;初次之外需要拷貝pd.txt檔案在本地電腦J盤的根目錄下以做參考 本案例只需要上傳order.txt到HDFS上即可-"/user/hadoop/order_productv2/input" 二