
FCN(全卷積神經網路)
原文連結: http://mp.weixin.qq.com/s?__biz=MzI1NTE4NTUwOQ==&mid=2650324665&idx=1&sn=3022e7e75a4bad0acdde36fe3edf565e&scene=5&srcid=0603Le1GYOSbqw1m7oU5BdxF#rd
從CNN 發展到 FCN ,從有監督訓練到end to end, 通常CNN網路在卷積層之後會接上若干個全連線層, 將卷積層產生的特徵圖(feature map)對映成一個固定長度的特徵向量。以AlexNet為代表的經典CNN結構適合於影象級的分類和迴歸任務,因為它們最後都期望得到整個輸入影象的一個數值描述,
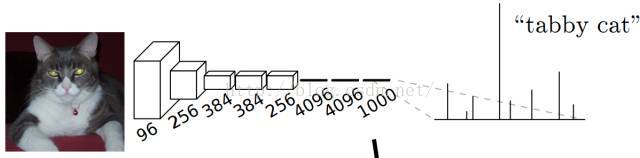
比如AlexNet的ImageNet模型輸出一個1000維的向量表示輸入影象屬於每一類的概率(softmax歸一化)。例如,下圖中的貓, 輸入AlexNet, 得到一個長為1000的輸出向量, 表示輸入影象屬於每一類的概率, 其中在“tabby cat”這一類響應最高。
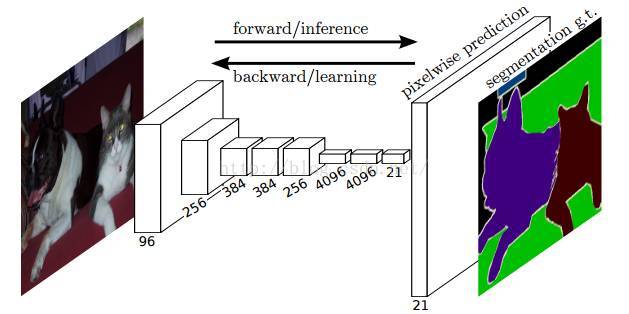
而Lonjong等發表在CVPR2015的論文提出了全卷積網路(FCN)進行畫素級的分類從而高效的解決了語義級別的影象分割(semantic segmentation)問題。與經典的CNN在卷積層之後使用全連線層得到固定長度的特徵向量進行分類(全聯接層+softmax輸出)不同,FCN可以接受任意尺寸的輸入影象,採用反捲積層對最後一個卷積層的feature
map進行上取樣, 使它恢復到輸入影象相同的尺寸,從而可以對每個畫素都產生了一個預測, 同時也保留了原始輸入影象中的空間資訊, 最後在上取樣的特徵圖上進行逐畫素分類。論文中逐畫素計算softmax分類的損失, 相當於每一個畫素對應一個訓練樣本。由於步長(stride)不為一的卷積層和池化層產生的特徵圖(feature map)大小會有一些向下取整操作, 導致最後的feature map大小與原圖不是嚴格的倍數關係。例如對如下的一個pooling層, { name:"pool1"
type: "Pooling" bottom: "conv1_2" top: "pool1" pooling_param { kernel_size: 2 stride: 2 } } 前層輸入大小為 11x11 的特徵圖,
其輸出的特徵圖大小為(11 - 2) / 2 + 1 = 5, 並不是輸入大小11的整數倍。上取樣不能完全保證最後的perpixel prediction 結果與原圖大小嚴格相同, 因此在上取樣(Deconvlution)之後會有一個
綜上,我理解的整體的思路就是輸入影象,然後卷積->下采樣->卷積-> 下采樣 。。。 得到足夠多的feature map --> 上取樣 -->crop對齊-->對整個矩陣進行softmax(畫素級別的分類)-->然後我也不知道怎麼做了......
相關推薦
FCN(全卷積神經網路)
原文連結: http://mp.weixin.qq.com/s?__biz=MzI1NTE4NTUwOQ==&mid=2650324665&idx=1&sn=3022e7e75a4bad0acdde36fe3edf565e&scene=5&a
深度學習筆記(基礎)——(六)全卷積神經網路(FCN)
通常CNN在卷積層之後會接上若干個全連線層,將卷積層產生的特徵圖(Feature Map)對映成一個固定長度的特徵向量進行分類。以AlexNet為代表的經典CNN結構適合於影象級的分類和迴歸任務,因為它們最後都期望得到整個輸入影象的一個數值描述,如AlexN
10分鐘看懂全卷積神經網路( FCN ):語義分割深度模型先驅
大家好,我是為人造的智慧操碎了心的智慧禪師。今天是10月24日,既是程式設計師節,也是程式設計師
卷積神經網路入門一種全卷積神經網路(LeNet),從左至右依次為卷積→子取樣→卷積→子取樣→全連線→全連線→高斯連線測試 最後,為了檢驗 CNN 能否工作,我們準備不同的另一組圖片與標記集(不能在訓練
轉載來自:http://blog.csdn.net/maweifei/article/details/52443995 第一層——數學部分 CNN 的第一層通常是卷積層(Convolutional Layer)。輸入內容為一個 32 x 32 x 3 的畫素值陣列。現在
機器學習筆記(十五):TensorFlow實戰七(經典卷積神經網路:VGG)
1 - 引言 之前我們介紹了LeNet-5和AlexNet,在AlexNet發明之後,卷積神經網路的層數開始越來越複雜,VGG-16就是一個相對前面2個經典卷積神經網路模型層數明顯更多了。 VGGNet是牛津大學計算機視覺組(Visual Geometry Group)和Google
機器學習筆記(十四):TensorFlow實戰六(經典卷積神經網路:AlexNet )
1 - 引言 2012年,Imagenet比賽冠軍的model——Alexnet [2](以第一作者alex命名)。這個網路算是一個具有突破性意義的模型 首先它證明了CNN在複雜模型下的有效性,然後GPU實現使得訓練在可接受的時間範圍內得到結果,讓之後的網路模型構建變得更加複雜,並且通過
機器學習筆記(十三):TensorFlow實戰五(經典卷積神經網路: LeNet -5 )
1 - 引言 之前我們介紹了一下卷積神經網路的基本結構——卷積層和池化層。通過這兩個結構我們可以任意的構建各種各樣的卷積神經網路模型,不同結構的網路模型也有不同的效果。但是怎樣的神經網路模型具有比較好的效果呢? 下圖展示了CNN的發展歷程。 經過人們不斷的嘗試,誕生了許多有
機器學習筆記(十二):TensorFlow實戰四(影象識別與卷積神經網路)
1 - 卷積神經網路常用結構 1.1 - 卷積層 我們先來介紹卷積層的結構以及其前向傳播的演算法。 一個卷積層模組,包含以下幾個子模組: 使用0擴充邊界(padding) 卷積視窗過濾器(filter) 前向卷積 反向卷積(可選) 1.1
機器學習筆記(十七):TensorFlow實戰九(經典卷積神經網路:ResNet)
1 - 引言 我們可以看到CNN經典模型的發展從 LeNet -5、AlexNet、VGG、再到Inception,模型的層數和複雜程度都有著明顯的提高,有些網路層數更是達到100多層。但是當神經網路的層數過高時,這些神經網路會變得更加難以訓練。 一個特別大的麻煩就在於訓練的時候會產
機器學習筆記(十六):TensorFlow實戰八(經典卷積神經網路:GoogLeNet)
1 - 引言 GoogLeNet, 在2014年ILSVRC挑戰賽獲得冠軍,將Top5 的錯誤率降低到6.67%. 一個22層的深度網路 論文地址:http://arxiv.org/pdf/1409.4842v1.pdf 題目為:Going deeper with convolu
關於CNN(卷積神經網路)中一些基本要點的簡要敘述
現階段卷積神經網路基本是以下幾個過程 : 1.卷積(Convolution) 2.非線性處理(ReLu) 3.池化(Pooling) 4.全連線層進行分類(Fully Connected) 假設輸入影象可以是狗 ,貓,船,鳥,當我們輸入一張船的影象的時候,卷
機器學習筆記(十二):TensorFlow實現四(影象識別與卷積神經網路)
1 - 卷積神經網路常用結構 1.1 - 卷積層 我們先來介紹卷積層的結構以及其前向傳播的演算法。 一個卷積層模組,包含以下幾個子模組: 使用0擴充邊界(padding) 卷積視窗過濾器(filter) 前向卷積 反向卷積(可選) 1.1.2 - 邊界填充
深度學習(卷積神經網路)問題總結
深度卷積網路 涉及問題: 1.每個圖如何卷積: (1)一個圖如何變成幾個? (2)卷積核如何選擇? 2.節點之間如何連線? 3.S2-C3如何進行分配? 4.1
深度學習框架tensorflow學習與應用10(MNSIT卷積神經網路實現)
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('F:/PY/MNIST_data/',
幾種使用了CNN(卷積神經網路)的文字分類模型
下面就列舉了幾篇運用CNN進行文字分類的論文作為總結。 1 yoon kim 的《Convolutional Neural Networks for Sentence Classification》。(2014 Emnlp會議) 他用的結構比較簡單,就是使用長度不同的 filter 對文字矩陣進行
Tensorflow例項:(卷積神經網路)LeNet-5模型
通過卷積層、池化層等結構的任意組合得到的神經網路有無限多種,怎樣的神經網路更有可能解決真實的影象處理問題?本文通過LeNet-5模型,將給出卷積神經網路結構設計的一個通用模式。 LeNet-5模型 LeNet-5模型是Yann LeCun教授於1998年
斯坦福大學的 CS231n(全稱:面向視覺識別的卷積神經網路)
斯坦福大學的 CS231n(全稱:面向視覺識別的卷積神經網路)一直是計算機視覺和深度學習領域的經典課程,每年開課都吸引很多學生。今年是該課程第3次開課,學生達到730人(第1次150人,第2次350人)。今年的CS231n Spring的instructors 是李飛飛、Ju
全卷積神經網路FCN-TensorFlow程式碼精析
這裡解析所有程式碼 並加入詳細註釋注意事項:FCN.py# coding=utf-8 from __future__ import print_function import tensorflow as tf import numpy as np import Tensor
影象語義分割(1)-FCN:用於語義分割的全卷積神經網路
論文地址:Fully Convolutional Networks for Semantic Segmentation [Long J , Shelhamer E , Darrell T . Fully Convolutional Networks for Semantic Segmen
tensorflow手冊cifar10.py(alexnet,卷積神經網路)的一些理解
以下只寫一些我花了點時間才理解的東西: 1、卷積tf.nn.conv2d()函式的理解:它其中有第二個引數是[filter_height, filter_width, in_channels, out_channels]。程式碼中第二次卷積,輸入是64,輸出也是6