
boost 字串處理(1)
字串演算法
標頭檔案 include
一.從split開始
string str1("hello abc-*-ABC-*-aBc goodbye");
vector<string> SplitVec; //結果
split(SplitVec, str1, is_any_of("-*"), token_compress_on);1.首先討論最簡單的一個引數token_compress_on,為一個列舉型別
namespace boost {
namespace algorithm {
//! Token compression mode
/*!
Specifies token compression mode for the token_finder.
*/ token_compress_on 為壓縮方式,如果在str1中遇到連續的’-‘,’*’則壓縮成一個
該引數下結果如下:
+ &SplitVec 0x005dfa9c [3](“hello abc”,”ABC”,”aBc goodbye”)
token_compress_off 為非壓縮凡是,和上面的相反結果為:
+ &SplitVec 0x0059fc88 [7](“hello abc”,”“,”“,”ABC”,”“,”“,”aBc goodbye”)
當然這個不是重點,重點是以上的列舉型別寫法,通過using方式將algorithm空間中的變數提升到boost空間中,這種方法比較常用,可避免列舉型別的衝突。
2.is_any_of(“-*”)
該函式返回一個is_any_of的struct物件,該物件為仿函式。
這些類似的仿函式生成函式,還提供幾個
// pull names to the boost namespace
using algorithm::is_classified;
using algorithm::is_space;
using algorithm::is_alnum;
using algorithm::is_alpha;
using algorithm::is_cntrl;
using algorithm::is_digit;
using algorithm::is_graph;
using algorithm::is_lower;
using algorithm::is_upper;
using algorithm::is_print;
using algorithm::is_punct;
using algorithm::is_xdigit;
using algorithm::is_any_of;
using algorithm::is_from_range;這樣就好理解了,在執行split過程中,呼叫is_any_of(),仿函式來判斷是否需要切割,如果返回true則切割,false則繼續查詢。
當然每一次的切割結果放入SplitVec容器中。理解這個之後,自己也可以寫這個仿函數了。
二.split拓展
先給一個大致的流程圖
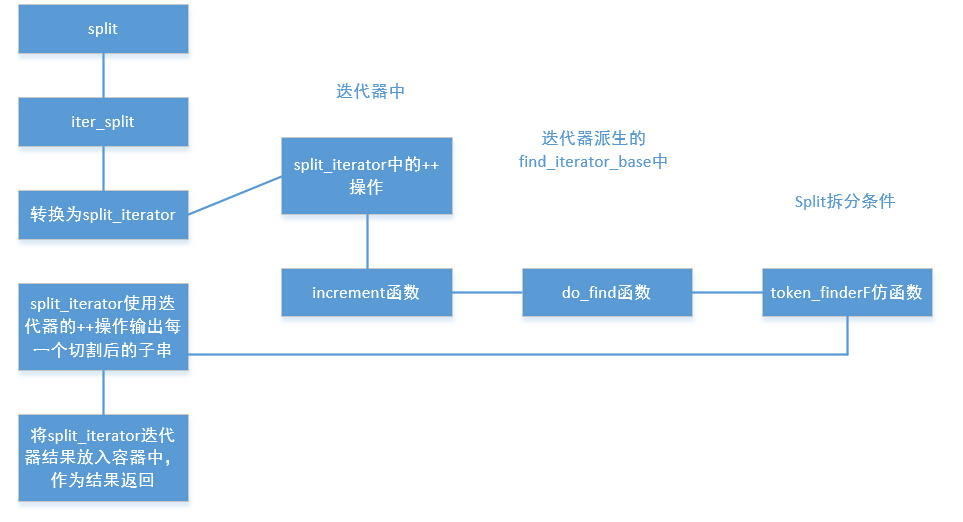
split
Split input into parts
iter_split
Use the finder to find matching substrings in the input and use them as separators to split the input into parts
template< typename SequenceSequenceT, typename RangeT, typename PredicateT >
inline SequenceSequenceT& split(
SequenceSequenceT& Result,
RangeT& Input,
PredicateT Pred,
token_compress_mode_type eCompress=token_compress_off )
{
return ::boost::algorithm::iter_split(
Result,
Input,
::boost::algorithm::token_finder( Pred, eCompress ) );
}split的內部是呼叫iter_split,iter_split是使用迭代器方式的。下面來看下iter_split中的具體實現:
template<
typename SequenceSequenceT,
typename RangeT,
typename FinderT >
inline SequenceSequenceT&
iter_split(
SequenceSequenceT& Result,
RangeT& Input,
FinderT Finder )
{
BOOST_CONCEPT_ASSERT((
FinderConcept<FinderT,
BOOST_STRING_TYPENAME range_iterator<RangeT>::type>
));
iterator_range<BOOST_STRING_TYPENAME range_iterator<RangeT>::type> lit_input(::boost::as_literal(Input));
typedef BOOST_STRING_TYPENAME
range_iterator<RangeT>::type input_iterator_type;
typedef split_iterator<input_iterator_type> find_iterator_type;
typedef detail::copy_iterator_rangeF<
BOOST_STRING_TYPENAME
range_value<SequenceSequenceT>::type,
input_iterator_type> copy_range_type;
input_iterator_type InputEnd=::boost::end(lit_input);
typedef transform_iterator<copy_range_type, find_iterator_type>
transform_iter_type;
transform_iter_type itBegin=
::boost::make_transform_iterator(
find_iterator_type( ::boost::begin(lit_input), InputEnd, Finder ),
copy_range_type() );
transform_iter_type itEnd=
::boost::make_transform_iterator(
find_iterator_type(),
copy_range_type() );
SequenceSequenceT Tmp(itBegin, itEnd);
Result.swap(Tmp);
return Result;
}在iter_split將Input轉換為迭代器,也就是lit_input。然後使用make_transform_iterator轉換函式,轉換為split_iterator迭代器。這時候split_iterator的begin指向了字串的首地址。在split_iterator類中實現了
迭代器中的++操作。在match_type結構中有兩個指標,begin和end用來指向當前迭代器中的有效部分,每一次do_find就可以將兩個指標向後移動。
void increment()
{
match_type FindMatch=this->do_find( m_Next, m_End );
if(FindMatch.begin()==m_End && FindMatch.end()==m_End)
{
if(m_Match.end()==m_End)
{
// Mark iterator as eof
m_bEof=true;
}
}
m_Match=match_type( m_Next, FindMatch.begin() );
m_Next=FindMatch.end();
}那麼do_find函式從何而來呢?
可以看一下,split_iterator 類的派生關係,可以看到這個類:detail::find_iterator_base,do_find就是來自這個類。
template<typename IteratorT>
class split_iterator :
public iterator_facade<
split_iterator<IteratorT>,
const iterator_range<IteratorT>,
forward_traversal_tag >,
private detail::find_iterator_base<IteratorT>現在來看下do_find函式,其中的m_Finder就是iter_split的最後一個引數FinderT Finder,也就最後用來傳遞給split_iterator的。m_Finder也就是::boost::algorithm::token_finder( Pred, eCompress )生成的仿函式物件。
// Find operation
match_type do_find(
input_iterator_type Begin,
input_iterator_type End ) const
{
if (!m_Finder.empty())
{
return m_Finder(Begin,End);
}
else
{
return match_type(End,End);
}
}在token_finder中又包含了一層,這樣來看的話token_finderF的才是仿函式的名字了。
template< typename PredicateT >
inline detail::token_finderF
token_finder(
PredicateT Pred,
token_compress_mode_type eCompress=token_compress_off )
{
return detail::token_finderF( Pred, eCompress );
}
看下token_finderF仿函式實現
ForwardIteratorT It=std::find_if( Begin, End, m_Pred );
就是查詢的重點了,m_Pred 就是is_any_of(“-*”),
當遇到”-*”中的任意一個返回true的仿函式。
這樣的話就可以通過token_finderF的仿函式返回滿足m_Pred條件的區域了。
template< typename ForwardIteratorT >
iterator_range<ForwardIteratorT>
operator()(
ForwardIteratorT Begin,
ForwardIteratorT End ) const
{
typedef iterator_range<ForwardIteratorT> result_type;
ForwardIteratorT It=std::find_if( Begin, End, m_Pred );
if( It==End )
{
return result_type( End, End );
}
else
{
ForwardIteratorT It2=It;
if( m_eCompress==token_compress_on )
{
// Find first non-matching character
while( It2!=End && m_Pred(*It2) ) ++It2;
}
else
{
// Advance by one position
++It2;
}
return result_type( It, It2 );
}
}三、split之外
在split中可見,boost中對字串的處理,幾乎是採用迭代器模式。
在boost::algorithm中,主要包括以下幾類演算法的實現,
演算法:
1. to_upper to_lower 字串大小寫的轉換
2. trim_left trim_right trim 字串左右空白字元的裁剪
3. starts_with ends_with contains …等 字串包含關係
4. find 字串查詢
5. replace 字串替換
6. split 字串切割
7. join 字串拼接
相關推薦
boost 字串處理(1)
字串演算法 標頭檔案 include 一.從split開始 string str1("hello abc-*-ABC-*-aBc goodbye"); vector<string> SplitVec; //結果 split(SplitVe
字元和字串處理(1)
2.1 字符集及字元編碼(字符集——字元的集合,不同的字符集,收錄的字元可能不同) 2.1.1多位元組字符集及ANSI編碼標準 (1)單位元組編碼:ASCII字符集及擴充套件——滿足英語及西歐語言的需要 (2)雙位元組編碼:——滿足亞洲等國家語言文字的需要,如:
字串處理(1) : 首字母轉大寫/小寫
/** * 首字母轉小寫 * * @param str * @return */ public static String toLowerCaseFirstOne(String str) { i
字串處理-1.1
-- charindex 尋找字串位置 CHARINDEX (@findStr, @baseStr [, @beginPoint ] ) @findStr :想要找到的字串 @baseStr :基礎字串,即被
Windows下的字串處理(1)
最近感覺Windows下的字串處理有點紊亂,準備系統學習下。在此做點筆記。 Unicode或者寬字元都沒有改變char資料型態在C中的含義。char繼續表示1個位元組的儲存空間,sizeof (char)繼續返回1。 理論上,C中1個位元組可比8位長,但對我們大多數人來說,1個位元組(也就是
boost字串處理(下)
四、正則表示式庫 Boost.Regex 可以應用正則表示式於C++。正則表示式大大減輕了搜尋特定模式字串的負擔,在很多語言中都是強大的功能。雖然現在C++仍然需要以 Boost C++庫的形式提供這一功能,但是在將來正則表示式將進入C++標準庫。 Boost Rege
Java(一) -Core Java-(1)-字串處理
任何對String字串的操作均不改變原串 Java中將字串作為String型別物件來處理。當建立一個String物件時,被建立的字串是不能被改變的。每次需要改變字串時都要建立一個新的String物件來
Boost(五)——字串處理(一):字串操作
由於這一章內容過多,我將採用三個小章,精簡原文三個小部分內容。 區域設定: setlocale(LC_ALL,“”) locale::global(std::locale("German")); //設定全域性區域德語環境 字串操作: 一、將字串所有字元轉成大寫
Boost(五)——字串處理(二):正則表示式操作
正則表示式: 一些簡單的描述符: . 匹配除換行符以外的任意字元 \w 匹配字母或數字或下劃線或漢字 等價於 '[^A-Za-z0-9_]'。 \s 匹配任意的空白符 \d 匹配數字 \b 匹配單詞的開始或結束 ^ 匹配字串的開始 $ 匹配字串的結束 一、字
Boost(五)——字串處理(三):詞彙分割操作
講解 詞彙分割器庫 -> Boost.Tokenizer 可以在指定某個字元為分隔符後,遍歷字串的部分表示式。 字元分割: boost::char_separator<char(或者wchar_t)> #include <iostream&g
boost常用字串處理方法學習
工作中經常要用到boost中關於字串處理的方法,這裡做個簡單的介紹: 分割字串:split string test1("Hello world, hello programmer"); vector<string> vec1; boost::split(
boost——字串與文字處理tokenizer
#include <iostream> #include <string> #include <vector> #include <set> #include <map> #include <al
boost 字串和文字處理庫概述
conversion/lexical_cast - lexical_cast 類模板,來自 Kevlin Henney. format - 型別安全的 '類printf' 的格式化操作,來自 Samuel Krempp. iostreams - 一個框架,用於定義流、流緩衝和i/o過濾器,來自 Jonatha
boost的字串處理函式——format
boost::format的格式一般為: boost::format( "format-string ") % arg1 % arg2 % ... % argN ; 注意這裡沒有示例物件,format-string代表需要格式化的字串,後面用過載過的%跟
<數字圖像處理1> 數字圖像定義(Definition) 類型(Type) 采樣 (Sampling) 量化 (Quantisation)
nali rom pixel diff 類型 out 4.3 this ecif Continuous Greyscale Image 1 mapping f from a rectangular domain Ω =(0,a1) X (0,a2) to a co-do
中文維基數據處理 - 1. 下載與清洗
下載 open shell title -m 實體 code 選擇 html 1. 數據下載 一些重要的鏈接: 最新轉儲 需要 zhwiki-latest-pages-articles.xml.bz2 這個文件 中文維基的頁面統計信息 目前內容頁面數大約是 978K 2
Python自然語言處理1
cmd 輸入 函數調用 down load src 選擇 分享 cnblogs 首先,進入cmd 輸入pip install的路徑 隨後開始下載nltk的包 一、準備工作 1、下載nltk 我的之前因為是已經下載好了 ,我現在用的參考書是Python自然語言處理這本書,最
老王Python-進階篇4-異常處理1.3(周末習題)
調用 page eve sage urn put not name bject 一 編寫with操作類Fileinfo(),定義__enter__和__exit__方法。完成功能: 1.1 在__enter__方法裏打開Fileinfo(filename),並且返回file
字串處理演算法(六)求2個字串最長公共部分
基礎演算法連結快速通道,不斷更新中: 整型陣列處理演算法部分: 整型陣列處理演算法(一)按照正態分佈來排列整型陣列元素 整型陣列處理演算法(二)檔案中有一組整數,要求排序後輸出到另一個檔案中 整型陣列處理演算法(三)把一個數組裡的所有元素,插入到另一個數組的指定位置 整型陣列
mysql進行字串處理
mysql進行字串的處理 MySQL 字串擷取函式:left(), right(), substring(), substring_index()。還有 mid(), substr()。其中,mid(), substr() 等價於 substring() 函式,substring()