
決策樹原理例項(python程式碼實現)
決策數(Decision Tree)在機器學習中也是比較常見的一種演算法,屬於監督學習中的一種。看字面意思應該也比較容易理解,相比其他演算法比如支援向量機(SVM)或神經網路,似乎決策樹感覺“親切”許多。
- 優點:計算複雜度不高,輸出結果易於理解,對中間值的缺失值不敏感,可以處理不相關特徵資料。
- 缺點:可能會產生過度匹配的問題。
- 使用資料型別:數值型和標稱型。
簡單介紹完畢,讓我們來通過一個例子讓決策樹“原形畢露”。
一天,老師問了個問題,只根據頭髮和聲音怎麼判斷一位同學的性別。
為了解決這個問題,同學們馬上簡單的統計了7位同學的相關特徵,資料如下:
| 頭髮 | 聲音 | 性別 |
|---|---|---|
| 長 | 粗 | 男 |
| 短 | 粗 | 男 |
| 短 | 粗 | 男 |
| 長 | 細 | 女 |
| 短 | 細 | 女 |
| 短 | 粗 | 女 |
| 長 | 粗 | 女 |
| 長 | 粗 | 女 |
機智的同學A想了想,先根據頭髮判斷,若判斷不出,再根據聲音判斷,於是畫了一幅圖,如下:
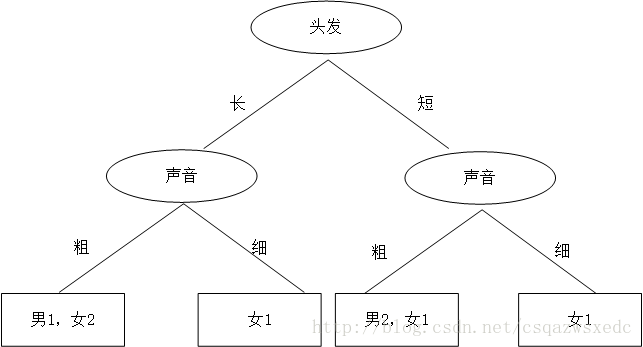
於是,一個簡單、直觀的決策樹就這麼出來了。頭髮長、聲音粗就是男生;頭髮長、聲音細就是女生;頭髮短、聲音粗是男生;頭髮短、聲音細是女生。
原來機器學習中決策樹就這玩意,這也太簡單了吧。。。
這時又蹦出個同學B,想先根據聲音判斷,然後再根據頭髮來判斷,如是大手一揮也畫了個決策樹:
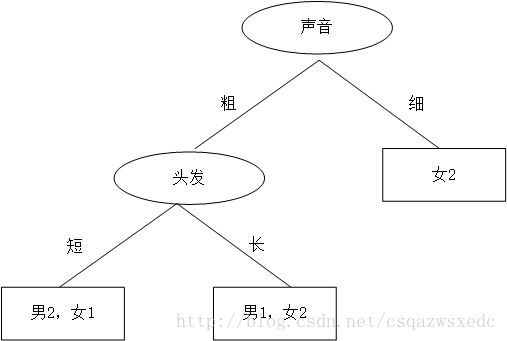
同學B的決策樹:首先判斷聲音,聲音細,就是女生;聲音粗、頭髮長是男生;聲音粗、頭髮長是女生。
那麼問題來了:同學A和同學B誰的決策樹好些?計算機做決策樹的時候,面對多個特徵,該如何選哪個特徵為最佳的劃分特徵?
劃分資料集的大原則是:將無序的資料變得更加有序。
我們可以使用多種方法劃分資料集,但是每種方法都有各自的優缺點。於是我們這麼想,如果我們能測量資料的複雜度,對比按不同特徵分類後的資料複雜度,若按某一特徵分類後複雜度減少的更多,那麼這個特徵即為最佳分類特徵。
Claude Shannon 定義了熵(entropy)和資訊增益(information gain)。
用熵來表示資訊的複雜度,熵越大,則資訊越複雜。公式如下:
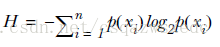
資訊增益(information gain),表示兩個資訊熵的差值。
首先計算未分類前的熵,總共有8位同學,男生3位,女生5位。
熵(總)=-3/8*log2(3/8)-5/8*log2(5/8)=0.9544
接著分別計算同學A和同學B分類後資訊熵。
同學A首先按頭髮分類,分類後的結果為:長頭髮中有1男3女。短頭髮中有2男2女。
熵(同學A長髮)=-1/4*log2(1/4)-3/4*log2(3/4)=0.8113
熵(同學A短髮)=-2/4*log2(2/4)-2/4*log2(2/4)=1
熵(同學A)=4/8*0.8113+4/8*1=0.9057
資訊增益(同學A)=熵(總)-熵(同學A)=0.9544-0.9057=0.0487
同理,按同學B的方法,首先按聲音特徵來分,分類後的結果為:聲音粗中有3男3女。聲音細中有0男2女。
熵(同學B聲音粗)=-3/6*log2(3/6)-3/6*log2(3/6)=1
熵(同學B聲音粗)=-2/2*log2(2/2)=0
熵(同學B)=6/8*1+2/8*0=0.75
資訊增益(同學B)=熵(總)-熵(同學A)=0.9544-0.75=0.2087
按同學B的方法,先按聲音特徵分類,資訊增益更大,區分樣本的能力更強,更具有代表性。
以上就是決策樹ID3演算法的核心思想。
接下來用python程式碼來實現ID3演算法:
from math import log
import operator
def calcShannonEnt(dataSet): # 計算資料的熵(entropy)
numEntries=len(dataSet) # 資料條數
labelCounts={}
for featVec in dataSet:
currentLabel=featVec[-1] # 每行資料的最後一個字(類別)
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1 # 統計有多少個類以及每個類的數量
shannonEnt=0
for key in labelCounts:
prob=float(labelCounts[key])/numEntries # 計算單個類的熵值
shannonEnt-=prob*log(prob,2) # 累加每個類的熵值
return shannonEnt
def createDataSet1(): # 創造示例資料
dataSet = [['長', '粗', '男'],
['短', '粗', '男'],
['短', '粗', '男'],
['長', '細', '女'],
['短', '細', '女'],
['短', '粗', '女'],
['長', '粗', '女'],
['長', '粗', '女']]
labels = ['頭髮','聲音'] #兩個特徵
return dataSet,labels
def splitDataSet(dataSet,axis,value): # 按某個特徵分類後的資料
retDataSet=[]
for featVec in dataSet:
if featVec[axis]==value:
reducedFeatVec =featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet): # 選擇最優的分類特徵
numFeatures = len(dataSet[0])-1
baseEntropy = calcShannonEnt(dataSet) # 原始的熵
bestInfoGain = 0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob =len(subDataSet)/float(len(dataSet))
newEntropy +=prob*calcShannonEnt(subDataSet) # 按特徵分類後的熵
infoGain = baseEntropy - newEntropy # 原始熵與按特徵分類後的熵的差值
if (infoGain>bestInfoGain): # 若按某特徵劃分後,熵值減少的最大,則次特徵為最優分類特徵
bestInfoGain=infoGain
bestFeature = i
return bestFeature
def majorityCnt(classList): #按分類後類別數量排序,比如:最後分類為2男1女,則判定為男;
classCount={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCount[vote]+=1
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels):
classList=[example[-1] for example in dataSet] # 類別:男或女
if classList.count(classList[0])==len(classList):
return classList[0]
if len(dataSet[0])==1:
return majorityCnt(classList)
bestFeat=chooseBestFeatureToSplit(dataSet) #選擇最優特徵
bestFeatLabel=labels[bestFeat]
myTree={bestFeatLabel:{}} #分類結果以字典形式儲存
del(labels[bestFeat])
featValues=[example[bestFeat] for example in dataSet]
uniqueVals=set(featValues)
for value in uniqueVals:
subLabels=labels[:]
myTree[bestFeatLabel][value]=createTree(splitDataSet\
(dataSet,bestFeat,value),subLabels)
return myTree
if __name__=='__main__':
dataSet, labels=createDataSet1() # 創造示列資料
print(createTree(dataSet, labels)) # 輸出決策樹模型結果輸出結果為:
{'聲音': {'細': '女', '粗': {'頭髮': {'短': '男', '長': '女'}}}}這個結果的意思是:首先按聲音分類,聲音細為女生;然後再按頭髮分類:聲音粗,頭髮短為男生;聲音粗,頭髮長為女生。
這個結果也正是同學B的結果。
補充說明:判定分類結束的依據是,若按某特徵分類後出現了最終類(男或女),則判定分類結束。使用這種方法,在資料比較大,特徵比較多的情況下,很容易造成過擬合,於是需進行決策樹枝剪,一般枝剪方法是當按某一特徵分類後的熵小於設定值時,停止分類。
ID3演算法存在的缺點:
1. ID3演算法在選擇根節點和內部節點中的分支屬性時,採用資訊增益作為評價標準。資訊增益的缺點是傾向於選擇取值較多是屬性,在有些情況下這類屬性可能不會提供太多有價值的資訊。
2. ID3演算法只能對描述屬性為離散型屬性的資料集構造決策樹 。
為了改進決策樹,又提出了ID4.5演算法和CART演算法。之後有時間會介紹這兩種演算法。
相關推薦
決策樹原理例項(python程式碼實現)
決策數(Decision Tree)在機器學習中也是比較常見的一種演算法,屬於監督學習中的一種。看字面意思應該也比較容易理解,相比其他演算法比如支援向量機(SVM)或神經網路,似乎決策樹感覺“親切”許多。 優點:計算複雜度不高,輸出結果易於理解,對中間值的缺
模擬RSA雙向驗證,並且實現DES加密以及MD5校驗過程(python程式碼實現)
要求如下: (1)A,B兩端各生成公鑰金鑰對(PA,SA), 金鑰對(PB,SB)。 (2)A端生成隨機數N1,用B的公鑰PB加
支援向量機SVM通俗理解(python程式碼實現)
這是第三次來“複習”SVM了,第一次是使用SVM包,呼叫包並嘗試調節引數。聽聞了“流弊”SVM的演算法。第二次學習理論,看了李航的《統計學習方法》以及網上的部落格。看完後感覺,滿滿的公式。。。記不住啊。第三次,也就是這次通過python程式碼手動來實現SVM,才
Tensorflow 反捲積(DeConv)實現原理+ 手寫python程式碼實現反捲積(DeConv)
1、反捲積原理 反捲積原理不太好用文字描述,這裡直接以一個簡單例子描述反捲積。 假設輸入如下: [[1,0,1], [0,2,1], [1,1,0]] 反捲積卷積核如下: [[ 1, 0, 1], [-1, 1, 0], [ 0,-1, 0]]
ml課程:決策樹、隨機森林、GBDT、XGBoost相關(含程式碼實現)
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教。 基礎概念: 熵Entropy:是衡量純度的一個標準,表示式可以寫為: 資訊增益Information Gain:熵變化的一個量,表示式可以寫為: 資訊增益率Gain Ratio:資訊增益的變化率,表示式可以寫為:
Tensorflow反捲積(DeConv)實現原理+手寫python程式碼實現反捲積(DeConv)
上一篇文章已經介紹過卷積的實現,這篇文章我們學習反捲積原理,同樣,在瞭解反捲積原理後,在後面手寫python程式碼實現反捲積。 1 反捲積原理 反捲積原理不太好用文字描述,這裡直接以一個簡單例子描述反捲積過程。 假設輸入如下: [[1,0,1],
字尾樹系列二:線性時間內構建字尾樹(包含程式碼實現)
上一篇文章已經介紹了字尾樹的前前後後的知識,並且採用各種技巧逼近線性時間了,至於具體怎麼操作大家看完之後應該多多少少有點想法了。而之所以將本文跟上一篇文章分開,主要考慮有三: 第一,和在一起文章就會太長了,看的頭疼。 第二,理論跟實現本來就有差異,本文中一些
leetcode-Two sum(最佳思路以及python程式碼實現)
1、Two sumGiven nums = [2, 7, 11, 15], target = 9, Because nums[0] + nums[1] = 2 + 7 = 9, return [0, 1].答案:使用hashtable,建立陣列值和下標的鍵值對,在pytho
樹的層次遍歷(Java程式碼實現)
與樹的前中後序遍歷的DFS思想不同,層次遍歷用到的是BFS思想。一般DFS用遞迴去實現(也可以用棧實現),BFS需要用佇列去實現。 層次遍歷的步驟是: 1.對於不為空的結點,先把該結點加入到佇列中 2.從隊中拿出結點,如果該結點的左右結點不為空,就分別把左右結點加入到佇列
隨機森林的原理分析及Python程式碼實現
轉載地址:https://blog.csdn.net/flying_sfeng/article/details/64133822/在講隨機森林前,我先講一下什麼是整合學習。整合學習通過構建並結合多個分類器來完成學習任務。整合學習通過將多個學習器進行結合,常可獲得比單一學習器更
紅黑樹Red-Black tree初步詳解(Java程式碼實現)
紅黑樹Red-Blacktree初步詳解 本部落格的參考資料: 演算法導論 http://blog.csdn.net/v_july_v/article/details/6105630 http://www.cnblogs.com/skywang12345/p/3624343
KNN演算法例子(java,scala,python 程式碼實現)
java 版本 package com.fullshare.test; import java.util.ArrayList; import java.util.Collections; import java.util.Comparator; import java.u
推薦系統實踐----基於使用者的協同過濾演算法(python程式碼實現書中案例)
本文參考項亮的《推薦系統實踐》中基於使用者的協同過濾演算法內容。因其中程式碼實現部分只有片段,又因本人初學,對python還不是很精通,難免頭大。故自己實現了其中的程式碼,將整個過程走了一遍。 1. 過程簡述 a. 首先我們因該先找到和目標使用者興趣相似的使用者集合。簡單來
python3.5實現決策樹c4.5(連續值版本)
最近學的python決策樹c4.5,網上沒找到連續值的code,自己xjb寫的,歡迎群巨前來指正·····orz # -*- coding: utf-8 -*- """ Created on Wed Mar 7 18:54:11 2018 @author: jkr
【演算法】手撕紅黑樹(上)—— 基本性質以及插入實現(附帶程式碼實現)
在閱讀其他博主關於紅黑樹增刪實現的時候,博主們大多直接使用文字圖片描述,對整個增刪整體的流程突出的不太明顯(當然dalao們寫得還是很棒得,不然我也寫不出這篇文章),所以我特意花了2天時間用CAD製作了 一張插入操作的流程圖和一張刪除操作的流程圖(刪除見下篇)並手撕程式碼(好吧,其實大部分時間在除錯程式碼,畢
C# GDI繪製儀表盤(純程式碼實現)
純程式碼實現GDI繪製儀表盤,效果在程式碼下面。public partial class HalfDashboardUc : UserControl { /// <summary> /// 儀表盤背景圖片 /// </summar
ml課程:概率圖模型—貝葉斯網路、隱馬爾可夫模型相關(含程式碼實現)
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教。 本文主要介紹機器學習中的一個分支——概率圖模型、相關基礎概念以及樸素貝葉斯、隱馬爾可夫演算法,最後還有相關程式碼案例。 說到機器學習的起源,可以分為以下幾個派別: 連線主義:又稱為仿生學派(bionicsism)或生理學派
ml課程:最大熵與EM演算法及應用(含程式碼實現)
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教。 本文主要介紹最大熵模型與EM演算法相關內容及相關程式碼案例。 關於熵之前的文章中已經學習過,具體可以檢視:ml課程:決策樹、隨機森林、GBDT、XGBoost相關(含程式碼實現),補充一些 基本概念: 資訊量:資訊的度量,即
ml課程:SVM相關(含程式碼實現)
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教。 本文主要介紹svm的創始人Vapnik‘s如何一步一步構建出這個經典演算法模型的,同時也可以給我們以後演算法之路提供一個思路,即使你對優化等數學方法不熟悉,依然可以創造出很好的演算法。 下svm關鍵的幾個idea: KEY ID
ml課程:線性迴歸、邏輯迴歸入門(含程式碼實現)
以下是我的學習筆記,以及總結,如有錯誤之處請不吝賜教。 本文主要介紹簡單的線性迴歸、邏輯迴歸先關推倒,以及案例程式碼。 昨天做專案發現K-means都忘了,想想之前很多基礎都忘了,於是決定重新開始學一遍ml的基礎內容,順便記錄一下,也算是梳理自己的知識體系吧。 機器學習:目前包括有監