
Flume概念與原理
一.什麼是Flume?
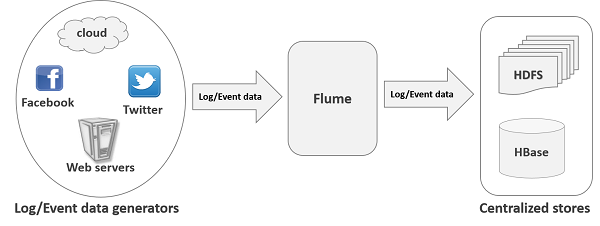
apache Flume 是一個從可以收集例如日誌,事件等資料資源,並將這些數量龐大的資料從各項資料資源中集中起來儲存的工具/服務,或者數集中機制。flume具有高可用,分散式,配置工具,其設計的原理也是基於將資料流,如日誌資料從各種網站伺服器上彙集起來儲存到HDFS,HBase等集中儲存器中。其結構如下圖所示:
二.Flume特點
flume是一個分散式、可靠、和高可用的海量日誌採集、聚合和傳輸的系統。支援在日誌系統中定製各類資料傳送方,用於收集資料;同時,Flume提供對資料進行簡單處理,並寫到各種資料接受方(比如文字、HDFS、Hbase等)的能力 。
flume
1)flume的可靠性
當節點出現故障時,日誌能夠被傳送到其他節點上而不會丟失。Flume提供了三種級別的可靠性保障,從強到弱依次分別為:end-to-end(收到資料agent首先將
event寫到磁碟上,當資料傳送成功後,再刪除;如果資料傳送失敗,可以重新發送。),Store on failure(這也是scribe採用的策略,當資料接收方crash時,將資料寫到本地,待恢復後,繼續傳送),Besteffort(資料傳送到接收方後,不會進行確認)。
2)flume的可恢復性
還是靠Channel。推薦使用FileChannel,事件持久化在本地檔案系統裡(效能較差)。
Flume的一些核心概念
Client:Client生產資料,執行在一個獨立的執行緒。
Event: 一個數據單元,訊息頭和訊息體組成。(Events可以是日誌記錄、 avro 物件等。)
Flow: Event從源點到達目的點的遷移的抽象。
Agent: 一個獨立的Flume程序,包含元件Source、 Channel、 Sink。(Agent使用JVM 執行Flume。每臺機器執行一個agent,但是可以在一個agent中包含多個sources和sinks。)
Source: 資料收集元件。(source從Client收集資料,傳遞給Channel)
Channel: 中轉Event的一個臨時儲存,儲存由Source元件傳遞過來的Event。(Channel連線 sources 和 sinks ,這個有點像一個佇列。)
Sink: 從Channel中讀取並移除Event, 將Event傳遞到FlowPipeline中的下一個Agent(如果有的話)(Sink從Channel收集資料,執行在一個獨立執行緒。)
三.Flume的優勢
1. Flume可以將應用產生的資料儲存到任何集中儲存器中,比如HDFS,HBase
2. 當收集資料的速度超過將寫入資料的時候,也就是當收集資訊遇到峰值時,這時候收集的資訊非常大,甚至超過了系統的寫入資料能力,這時候,Flume會在資料生產者和資料收容器間做出調整,保證其能夠在兩者之間提供一共平穩的資料.
3. 提供上下文路由特徵
4. Flume的管道是基於事務,保證了資料在傳送和接收時的一致性.
5. Flume是可靠的,容錯性高的,可升級的,易管理的,並且可定製的。
3. Flume具有的特徵:
1. Flume可以高效率的將多個網站伺服器中收集的日誌資訊存入HDFS/HBase中
2. 使用Flume,我們可以將從多個伺服器中獲取的資料迅速的移交給Hadoop中
3. 除了日誌資訊,Flume同時也可以用來接入收集規模巨集大的社交網路節點事件資料,比如facebook,twitter,電商網站如亞馬遜,flipkart等
4. 支援各種接入資源資料的型別以及接出資料型別
5. 支援多路徑流量,多管道接入流量,多管道接出流量,上下文路由等
6. 可以被水平擴充套件
四. Flume的結構
1. flume的外部結構:
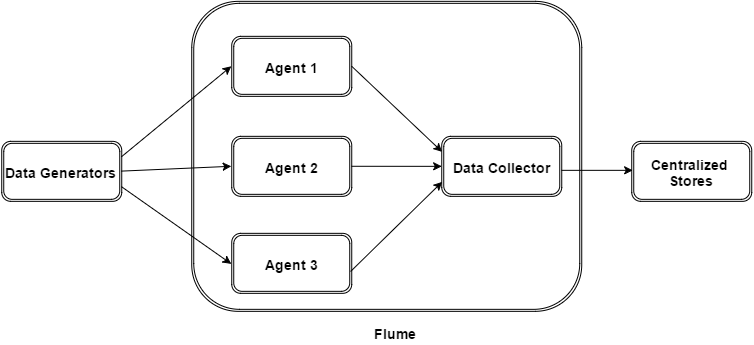
如上圖所示,資料發生器(如:facebook,twitter)產生的資料被被單個的執行在資料發生器所在伺服器上的agent所收集,之後資料收容器從各個agent上彙集資料並將採集到的資料存入到HDFS或者HBase中
Flume OG:Flume Original Generation,初代Flume。
由三種角色構成:代理點(agent)、收集節點(collector)、主節點(master)
agent 從各個資料來源收集日誌資料,將收集到的資料集中到 collector,然後由收集節點彙總存入 hdfs。
master 負責管理 agent,collector 的活動。
agent、collector 都稱為 node,node 的角色根據配置的不同分為 logical node(邏輯節點)、physical node(物理節點)。對 logical nodes 和 physical nodes 的區分、配置、使用一直以來都是使用者最頭疼的地方。
agent、collector由Source、Sink組成,當前節點的資料是從Source傳送到Sink的。
2. Flume 事件
事件作為Flume內部資料傳輸的最基本單元.它是由一個轉載資料的位元組陣列(該資料組是從資料來源接入點傳入,並傳輸給傳輸器,也就是HDFS/HBase)和一個可選頭部構成.
典型的Flume 事件如下面結構所示:

我們在將event在私人定製外掛時比如:flume-hbase-sink外掛是,獲取的就是event然後對其解析,並依據情況做過濾等,然後在傳輸給HBase或者HDFS.
3.Flume Agent
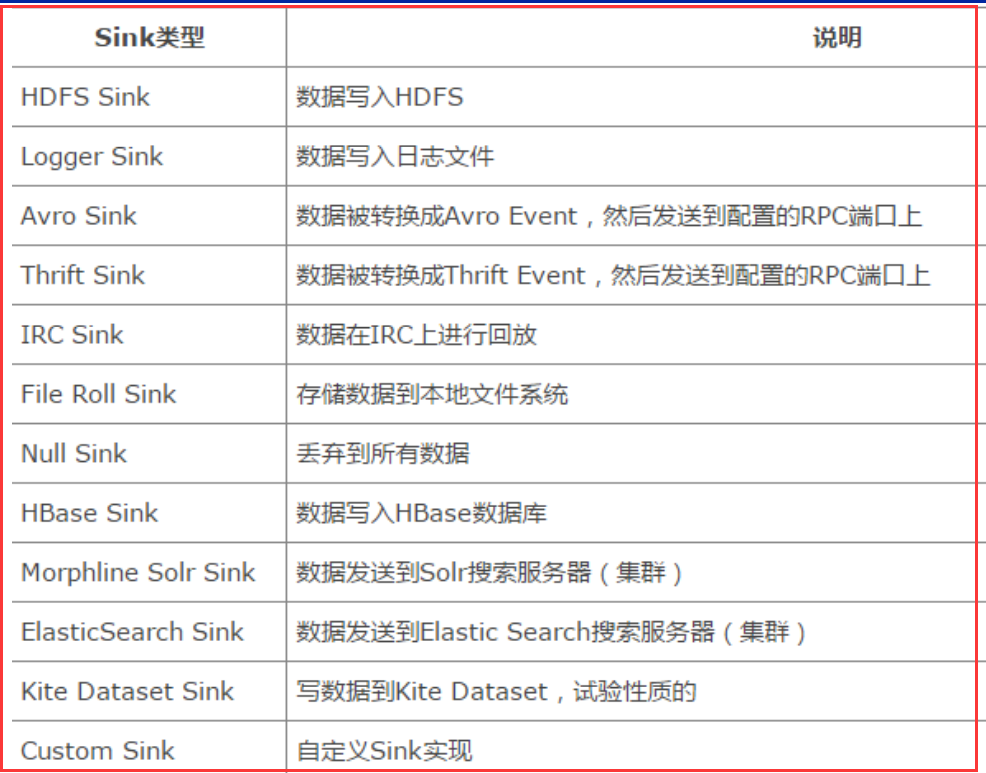
我們在瞭解了Flume的外部結構之後,知道了Flume內部有一個或者多個Agent,然而對於每一個Agent來說,它就是一共獨立的守護程序(JVM),它從客戶端哪兒接收收集,或者從其他的 Agent哪兒接收,然後迅速的將獲取的資料傳給下一個目的節點sink,或者agent. 如下圖所示flume的基本模型
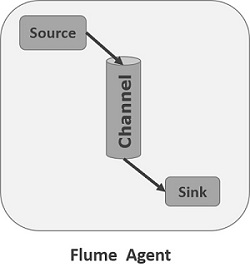
Agent主要由:source,channel,sink三個元件組成.
Source:
從資料發生器接收資料,並將接收的資料以Flume的event格式傳遞給一個或者多個通道channal,Flume提供多種資料接收的方式,比如Avro,Thrift,twitter1%等
Channel:
channal是一種短暫的儲存容器,它將從source處接收到的event格式的資料快取起來,直到它們被sinks消費掉,它在source和sink間起著一共橋樑的作用,channal是一個完整的事務,這一點保證了資料在收發的時候的一致性. 並且它可以和任意數量的source和sink連結. 支援的型別有: JDBC channel , File System channel , Memort channel等.

sink:
sink將資料儲存到集中儲存器比如Hbase和HDFS,它從channals消費資料(events)並將其傳遞給目標地. 目標地可能是另一個sink,也可能HDFS,HBase.
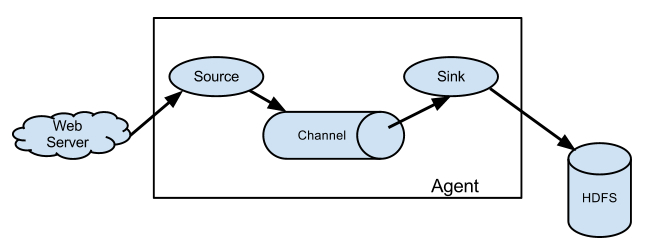
它的組合形式舉例:
以上介紹的flume的主要元件,下面介紹一下Flume外掛:
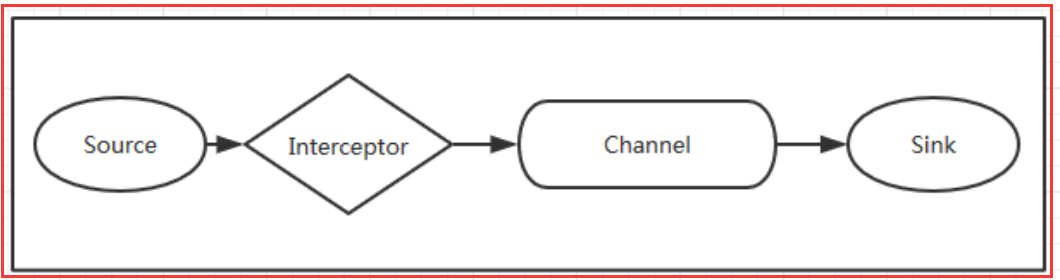
1. Interceptors攔截器
攔截器的位置在Source和Channel之間,當我們為Source指定攔截器後,我們在攔截器中會得到event,根據需求我們可以對event進行保留還是拋棄,拋棄的資料不會進入Channel中。
2. 管道選擇器 channels Selectors
在多管道是被用來選擇使用那一條管道來傳遞資料(events). 管道選擇器又分為如下兩種:
預設管道選擇器: 每一個管道傳遞的都是相同的events
多路複用通道選擇器: 依據每一個event的頭部header的地址選擇管道.
3.sink執行緒
用於啟用被選擇的sinks群中特定的sink,用於負載均衡.
五、Flume使用場景
Flume在英文中的意思是水道, 但Flume更像可以隨意組裝的消防水管,下面根據官方文件,展示幾種Flow。
5.1、多個agent順序連線
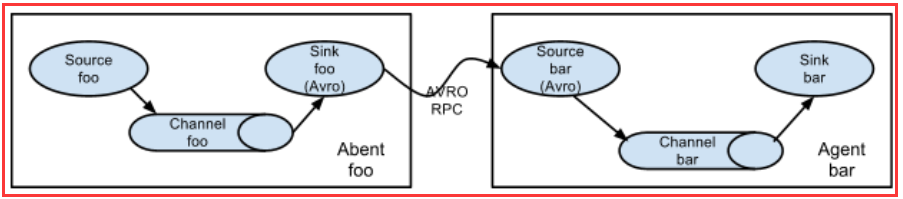
可以將多個Agent順序連線起來,將最初的資料來源經過收集,儲存到最終的儲存系統中。這是最簡單的情況,一般情況下,應該控制這種順序連線的
Agent 的數量,因為資料流經的路徑變長了,如果不考慮failover的話,出現故障將影響整個Flow上的Agent收集服務。
5.2、多個Agent的資料匯聚到同一個Agent
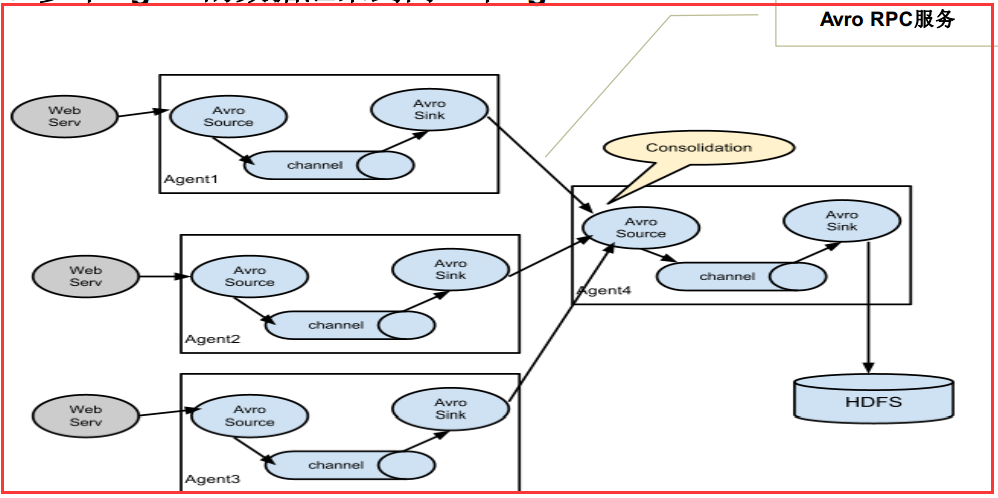
這種情況應用的場景比較多,比如要收集Web網站的使用者行為日誌, Web網站為了可用性使用的負載叢集模式,每個節點都產生使用者行為日誌,可以為
每 個節點都配置一個Agent來單獨收集日誌資料,然後多個Agent將資料最終匯聚到一個用來儲存資料儲存系統,如HDFS上。
5.3、多級流
Flume還支援多級流,什麼多級流?結合在雲開發中的應用來舉個例子,當syslog, java, nginx、 tomcat等混合在一起的日誌流開始流入一個agent
後,可以agent中將混雜的日誌流分開,然後給每種日誌建立一個自己的傳輸通道。

5.4、load balance功能
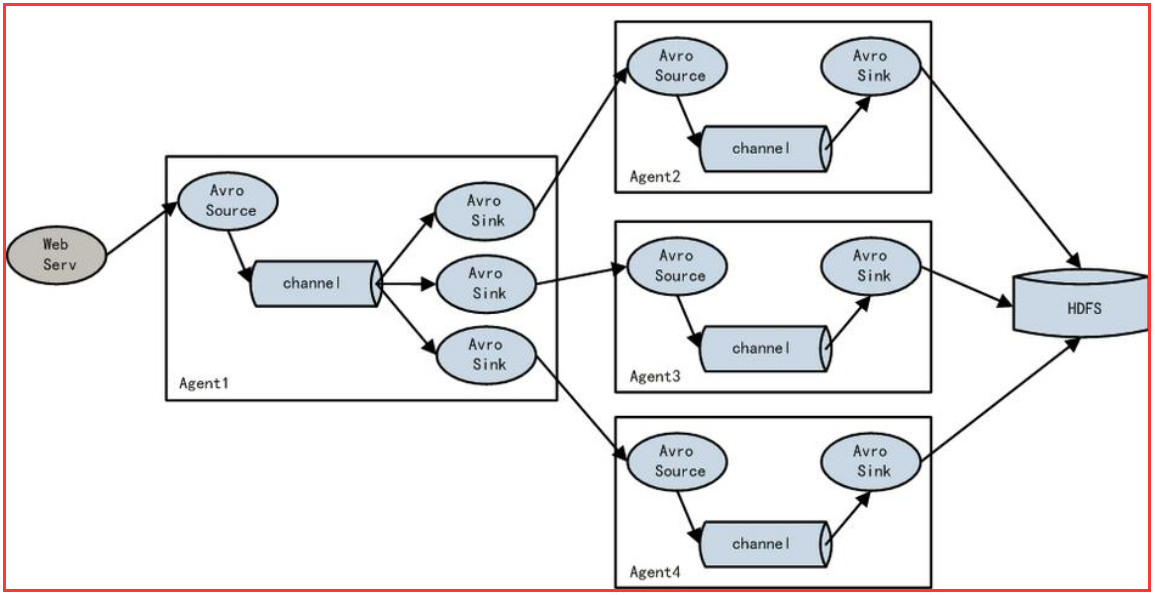
上圖Agent1是一個路由節點,負責將Channel暫存的Event均衡到對應的多個Sink元件上,而每個Sink元件分別連線到一個獨立的Agent上 。
六.Flume與Kafka對比
kafka和flume都是日誌系統,kafka是分散式訊息中介軟體,自帶儲存,提供push和pull存取資料功能。flume分為agent(資料採集器),collector(資料簡單處理和寫入),storage(儲存器)三部分,每一部分都是可以定製的。比如agent採用RPC(Thrift-RPC)、text(檔案)等,storage指定用hdfs做。
Kafka 是一個非常通用的系統。你可以有許多生產者和很多的消費者共享多個主題Topics。相比之下,Flume是一個專用工具被設計為旨在往HDFS,HBase傳送資料。它對HDFS有特殊的優化,並且集成了Hadoop的安全特性。所以,Cloudera 建議如果資料被多個系統消費的話,使用kafka;如果資料被設計給Hadoop使用,使用Flume。
Flume可以使用攔截器實時處理資料。這些對資料遮蔽或者過量是很有用的。Kafka需要外部的流處理系統才能做到。
Kafka和Flume都是可靠的系統,通過適當的配置能保證零資料丟失。然而,Flume不支援副本事件。於是,如果Flume代理的一個節點崩潰了,即使使用了可靠的檔案管道方式,你也將丟失這些事件直到你恢復這些磁碟。如果你需要一個高可靠行的管道,那麼使用Kafka是個更好的選擇。
Flume和Kafka可以很好地結合起來使用。如果你的設計需要從Kafka到Hadoop的流資料,使用Flume代理並配置Kafka的Source讀取資料也是可行的:你沒有必要實現自己的消費者。你可以直接利用Flume與HDFS及HBase的結合的所有好處。你可以使用Cloudera Manager對消費者的監控,並且你甚至可以新增攔截器進行一些流處理。kafka做日誌快取應該是更為合適的,但是 flume的資料採集部分做的很好,可以定製很多資料來源,減少開發量。所以比較流行flume+kafka模式,如果為了利用flume寫hdfs的能力,也可以採用kafka+flume的方式。
相關推薦
Flume概念與原理、與Kafka優勢對比
1 .背景 flume是由cloudera軟體公司產出的可分散式日誌收集系統,後與2009年被捐贈了apache軟體基金會,為hadoop相關元件之一。尤其近幾年隨著flume的不斷被完善以及
Flume概念與原理
一.什麼是Flume? apache Flume 是一個從可以收集例如日誌,事件等資料資源,並將這些數量龐大的資料從各項資料資源中集中起來儲存的工具/服務,或者數集中機制。flume具有高可用,分散式,配置工具,其設計的原理也是基於將資料流,如日誌資料從各種網
Bloom filter(布隆過濾器)概念與原理
概念 int 復雜 gravity water pac 基數 AS class https://en.wikipedia.org/wiki/Bloom_filter 寫在前面 在大數據與雲計算發展的時代,我們經常會碰到這樣的問題。我們是否能高效的判斷一個用
Java執行緒詳解(1)-概念與原理
一、程序與執行緒 程序是指一個記憶體中執行的應用程式,每個程序都有自己獨立的一塊記憶體空間,即程序空間或(虛空間)。程序不依賴於執行緒而獨立存在,一個程序中可以啟動多個執行緒。比如在Windows系統中,一個執行的exe就是一個程序。 執行
ChainDesk:初識鏈碼-鏈碼概念與原理
作者:ChainDesk韓小東,ChainDesk區塊鏈行業分析師, ChainDesk區塊鏈工程師 目標 1.認識 Hyperledger Fabric 中的鏈碼(智慧合約) 2.明確系統鏈碼的種類及作用 3.熟知鏈碼的生命週期管理 任
Java多執行緒程式設計總結筆記——03概念與原理
作業系統中執行緒和程序的概念 現在的作業系統是多工作業系統。多執行緒是實現多工的一種方式。 程序是指一個記憶體中執行的應用程式,每個程序都有自己獨立的一塊記憶體空間,一個程序中可以啟動多個執行緒。比如在Windows系統中,一個執行的exe就是一個程序。執行
iOS/OS X記憶體管理(一):基本概念與原理
在Objective-C的記憶體管理中,其實就是引用計數(reference count)的管理。記憶體管理就是在程式需要時程式設計師分配一段記憶體空間,而當使用完之後將它釋放。如果程式設計師對記憶體資源使用不當,有時不僅會造成記憶體資源浪費,甚至會導致程式crach。我們將會從引用計數和記憶體管理
Elasticsearch最佳實踐之核心概念與原理
每一個系統都擁有很多概念,這些概念是作者在設計與實現時為不同的模組或功能做的定義。概念本身只是一個名詞,往往會跟隨作者的喜好不同而不同,重要的是理解其設計的初衷以及要表達的實際內容,否則很快就會忘記其意義。作為專欄文章的第二篇,本文將從多個方面對Elasticsearch的核心概念進
iOS/OS X記憶體管理(一):基本概念與原理
CSDN移動將持續為您優選移動開發的精華內容,共同探討移動開發的技術熱點話題,涵蓋移動應用、開發工具、移動遊戲及引擎、智慧硬體、物聯網等方方面面。如果您想投稿、尋求《近匠》報道,或給文章挑錯,歡迎傳送郵件至tangxy#csdn.net(請把#改成@)。 在Objective-C的記憶體管理中,其實就
區塊鏈技術核心概念與原理理解
區塊鏈的前世今生 說到區塊鏈,就不得不提及密碼朋克。 密碼朋克萌芽於1970年代、正式發起於1993年。 認為保護個人隱私是自由社會的重要基石,反對政府、公司對個人隱私的侵害。政權的基礎經常建立在控制資料上,通過此類控制可以害人,壓迫人,或讓人閉嘴 以程式碼和密碼學為
Java-----IO流的概念與原理
IO流的概念與原理 概念: 流:流動,流向,從一端移動到另一端, 源頭與目的地。 程式 與 檔案|陣列|網路連線|資料庫 ,以程式為中心 IO流分類 流向: 輸入流與輸
影象語義分割的概念與原理以及常用的方法
1影象語義分割的概念 1.1影象語義分割的概念與原理 影象語義分割可以說是影象理解的基石性技術,在自動駕駛系統(具體為街景識別與理解)、無人機應用(著陸點判斷)以及穿戴式裝置應用中舉足輕重。我們都知道,影象是由許多畫素(Pixel)組成,而「語義分割」顧名思義就
一、zookeeper詳解概念與原理(總結的乾貨)
ZK總結: zookeeper(以下就用ZK代替)是一個分散式協調系統,主要有兩大功能,檔案系統和通知系統。 1、zk(分散式高性協調系統): 功能: 配置服務 叢集管理 名字服務 分散式同步 釋出訂閱(註冊中心) 資料庫動態切換 分散式日誌收集 分散式
Hbase學習之概念與原理
兩個 都是 block 快速 關於 圖片 存在 獲取 寫到 一、hbase與列式存儲 hbase最早起源於谷歌的一篇BigTable的論文,它是由java編寫的、開源的一個nosql數據庫,同時它也是一個列式存儲的、支持分布式(基於hdfs)的數據庫。什麽是列式存儲呢?
flume監控與監控原理
Flume監控流程 首先在flume-ng-node中org.apache.flume.node.Application的main方法中,有兩個方法分別是startAllComponents()和startAllComponents(conf)方法 其中startAllComponent
容器概念與Linux Container原理
一、容器與LxC 在像KVM等眾多主機虛擬化解決方案中,對每一個虛擬機器例項提供的是從底層硬體開始一直到上層的環境,在硬體級進行資源劃分。虛擬機器的核心是執行在硬體核心之上的。由於每個虛擬例項都有自己的執行核心,所以各例項之間有非常好的隔離性。 但在某些場景中使用KVM等虛擬機器過於笨重,例如使用
《微機原理與介面技術》第三章——介面概念和原理
雖然寫這個部落格主要目的是為了給我自己做一個思路記憶錄,但是如果你恰好點了進來,那麼先對你說一聲歡迎。我並不是什麼大觸,只是一個菜菜的學生,如果您發現了什麼錯誤或者您對於某些地方有更好的意見,非常歡迎您的斧正! 目錄 第1節 介面/埠的定義 第2節 埠
AOP概念與執行原理
引言: AOP指的就是面向切面程式設計,在實際的開發和工作中很多地方都深有體現,比如許可權控制,控制全域性狀態等。接下來會詳細闡述AOP的概念,給出對應的DEMO來深入學習實踐,探討AOP的意義。 技術點: 1、反射(reflect) 在執行狀態
Linux程序管理之1 程序概念與作業系統基礎原理
計算機硬體層面之上是作業系統,狹義的作業系統主要指系統核心,核心有以下作用:程序管理、檔案系統、網路管理、記憶體管理、驅動程式、安
理解Spring(二):AOP 的概念與實現原理
[TOC] ## 什麼是 AOP AOP(Aspect Oriented Programming,面向切面程式設計)是一種程式設計正規化,它是對 OOP(Object Oriented Programming,面向物件程式設計)的一個補充。 OOP 允許我們通過類來定義物件的屬性和行為,由於物件的行