
C++實現K-means,聚類原理解析(並用在圖片畫素點聚類)
最近用到影象中的點的聚類,於是就寫了一個k-means的類。
驗證的過程是將一幅圖的所有點的(B, G, R)作為資料點,進行聚類。
算出K箇中心類後,對影象中的每個點進行重新上色。按照類別給給每類生成一種隨機色彩。
使用該類,可以自定義聚類中心K的個數、資料維度N的大小。
資料型別可以是float、int。
同時在迭代過程中,可以選擇輸出每次迭代的中心點資訊等。
下面分以下幾個部分:
一,K-means的思路
二,基本公式與程式實現細節
三,參考
四,影象處理結果
----------------------------------------------------------------------------------------------------------------------------
K-means 演算法是一種簡單有效的無監督學習方法,它可以有效地將多維空間(用N表示)中的點聚成一個個緊密的簇。
K-means演算法的優化目標是使求出K箇中心點,使每一個點到該點的歐氏距離平方之和儘量小(不知道現在有沒有什麼演算法能保證一定得到全域性最優解)。
簡單來說就是把一個分到一個類中的所有資料點的每一維相加,得一個向量。然後,該向量的每一維除以該類的點的個數。這樣得的向量就是該類的中心(centroid).
演算法的思路如下:
1. 初始化K箇中心點。
這K個點可以是在所有輸入資料點中隨機抽取的,也可以是取前K個點,也可以是從N維空間中任意一個點。這些點和資料點之間的距離只要不是相差的太離譜都沒有關係。
2. 對任意一個數據點,求與它最近的中心點,並認為該資料點屬於該中心點所代表的類。對於M(假設共有M個數據點)個數據點,分別計算每個點與K個當前的中心點的歐氏距離平方值,點x_i與哪個中心點(如c_j)的歐氏距離平方最小那麼它就分成該類。(該過程可以求出一些指標,用於終止程式。如,求出整體歐氏距離之和)
一般暴力的方法是要計算M * K次歐氏距離。《An Efficient k-Means Clustering Algorithm:Analysis and Implementation》 提供了一種利用KD樹的超子空間到K個點心點的距離對中心點進行減枝的方法。它的主要思想是,將一個KD樹中的子空間作為一個超球面的中心點,以K箇中心點中到子空間中心最近的距離為半徑形成了一個新的超球面,用這個超球面將當前的K箇中心點分成兩部分:與該子空間的最近中心點的待選集合與不可能是該子空間中任意一點的最近中心點的集合。
3. 更新每個類的中心點。
4. 由 2 得出的指標判斷是否可以終止:否,進行 2 ;是,終止,並給出中心點資訊。
----------------------------------------------------------------------------------------------------------------------------
程式實現細節:
0. K-means類定義。這個程式的一部分目的也是為了測試類模版,原本想相容多種資料型別(float、int),到最後才發現主要還是對float型別做處理。(所以使用類模版在這個程式中有點雞肋。完全可以用float代替。維度N也是同樣的,維度N和待求中心點的個數K都可以在類宣告時候定義)
template <typename T, int N> class KMeansTest
{
private:
vector<vector<T>> centers;// 儲存中心點
bool data_is_ok(vector<vector<T>> points, int k);
T calculate_center_once(vector<vector<T>> points);// calculate centers for once, and return the total sum
int k_centers = 0;
T Total_Sum = 0; // sum of square, or square root of sum
T Total_Sum_Sqrt = 0; // sum of square, or square root of sum
public:
int end_modal = 0;
bool random_initial_centers = false; // trye: get random points as centers; else, get top k points as initial centers.
bool show_info_flag = false; // true: show kmeans object centers' information; false: show output only.
KMeansTest();
KMeansTest(vector<vector<T>> points, int k);
void init_k(vector<vector<T>> points, int k);
int get_centers(vector<T> point); // return the center index and center point
void show_info();
void sort_ascend(); // sort average of each point in ascend order.
};1. 初始化。我設定了兩種可以初始化的方式:取前K個點;隨機取K個點。程式碼如下:
if (random_initial_centers) {
for (int i = 0; i < k; i++) {
int iSecret;
srand (time(0)+i);// use current time as seed for random generator
iSecret = rand() % points.size();
centers.push_back(points[iSecret]);
}
}
else
{
for (int i = 0; i < k; i++) {
centers.push_back(points[i]);
}
}2. 尋找最近中心點。我用的暴力的列舉法,計算每一個數據點與當前的所有的點心點的距離,找最小的那個。
T total_sum = 0; //
// initialize clusters storage
// vector<vector<vector<T>>> clusters(N, vector<vector<T>>);
map<int, vector<vector<T>>> clusters;
// calculate square sum
for (typename vector<vector<T>>::iterator it = points.begin(); it!=points.end(); it++) {
////////////// BEGIN: find the nearest center, and the minimum squared distance///////////////
T min = ((*it)[0]-centers[0][0]) * ((*it)[0]-centers[0][0]); // how to find the maximum of Type T, and initialize 0 to T?
//
for (int i=1; i<N; i++) {
min += ((*it)[i]-centers[0][i]) * ((*it)[i]-centers[0][i]);
}
// cout<<"Begin min:"<<min<<endl;
int min_i = 0;// the nearest center's index
for (int i = 1; i<k_centers; i++) { // k, centers
// test
T sum = ((*it)[0]-centers[i][0]) * ((*it)[0]-centers[i][0]);
// cout<<"sum: "<<sum<<"\t";
for (int j = 1; j<N; j++) { // N, dimension
// WRONG FORMAT: sum += (*it[j]-centers[i][j]) * (*it[j]-centers[i][j]);
sum += ((*it)[j]-centers[i][j]) * ((*it)[j]-centers[i][j]);
// cout<<sum<<"\t";
}
// cout<<"compare sum and min||sum:"<<sum<<"||min:"<<min<<"||sum<min:"<<(sum<min)<<endl;
if (sum < min) {
// waitKey(0);
min = sum;
min_i = i;
// cout<<"EXCANG: min:"<<min<<"\t min_i:"<<min_i<<"\t";
}
// cout<<endl;
}
/////////////// END: find the nearest center, and the minimum squared distance///////////////
/////////////// store points for cluster min_i /////////////////////////
clusters[min_i].push_back(*it); // save point to cluster min_i
total_sum += min;
// cout<<"min: "<<min<<"\ttotal_sum:"<<total_sum<<endl;
}
3. 更新中心點。
//////////////////// update centers /////////////////////
for (int i = 0; i < k_centers; i++) {
if (clusters.find(i)==clusters.end()) // if there is no point assigned to this center, do nothing about it. You can also change this center by random, or some also policy.®
{
continue;
}
vector<T> center = clusters[i][0];
int c_i_size = (int)clusters[i].size(); // might be wrong , when initial centers are same
// if there is no point in cluster[i], continue
// if (c_i_size==0) {
// continue;
// }
for (int j=1; j<c_i_size; j++) {
for (int d = 0; d < N; d++) {
center[d] += clusters[i][j][d]; // might be wrong , when initial centers are same.
}
}
// update centers
centers[i].clear();
for (int d = 0; d < N; d++) {
centers[i].push_back(center[d]/c_i_size);
}
}
Total_Sum_Sqrt = sqrt(total_sum);
// Total_Sum = total_sum;
4. 終止步驟 2 和 3 的迭代過程的條件可以自己選擇,比如:
a. 設定迭代次數
b. 分配給每個類的點數不再變動
c. 中心點不再變動
d. 整體歐氏距離平方和不再變動
e. 整體歐氏距離平方和小於某個閾值
在這裡我用了條件 d,同時我也在尋找過程中記錄了整體歐氏距離平方和最小情況下的中心點資訊。
實踐經驗是:K-means收斂挺快,還沒遇到過無限迭代的情況;整體歐氏距離平方和有時候會先下降到一定程度,然後再稍稍上升一點,目前還不知道為什麼;下面這兩種方式先出來的中心點一般差別不大,在實驗的圖片上的效果看不出差別。
程式碼如下:
switch (end_modal) {
case 0:
{
do{
pre_sum = total_sum;
// show_info();
total_sum = calculate_center_once(points);
}while (pre_sum-total_sum);
}
break;
case 1:
{
T min_sum = total_sum;
tem_centers = centers;
do{
pre_sum = total_sum;
show_info();
total_sum = calculate_center_once(points);
if (min_sum > total_sum) {
min_sum = total_sum;
// tem_centers.clear();
tem_centers = centers;
}
}while (pre_sum-total_sum);
// centers.clear();
centers = tem_centers;
Total_Sum_Sqrt = min_sum;
}
break;
default:
break;
}
----------------------------------------------------------------------------------------------------------------------------
同時,我對一張圖片進行了一些測試。
原圖:

聚3類:
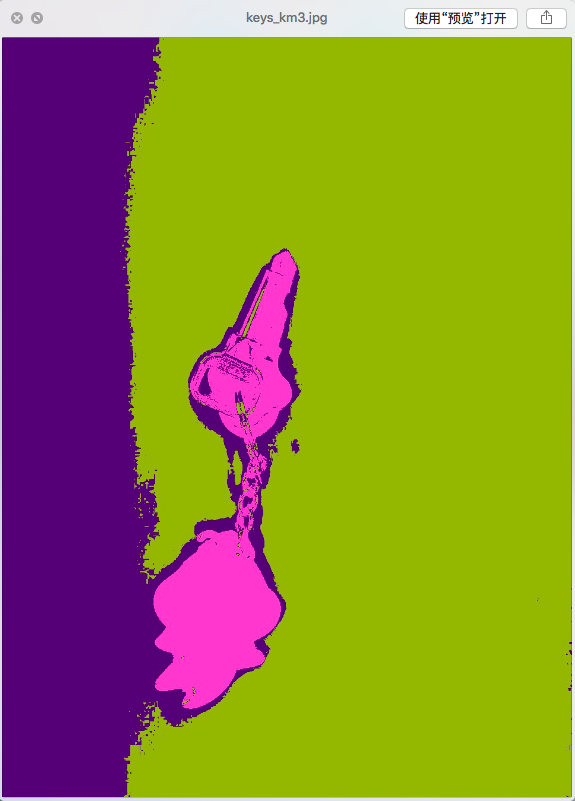
聚4類:

聚7類:

聚10類:

聚20類:

相關推薦
C++實現K-means,聚類原理解析(並用在圖片畫素點聚類)
最近用到影象中的點的聚類,於是就寫了一個k-means的類。 驗證的過程是將一幅圖的所有點的(B, G, R)作為資料點,進行聚類。 算出K箇中心類後,對影象中的每個點進行重新上色。按照類別給給每類生成一種隨機色彩。 使用該類,可以自定義聚類中心K的個數、資料維度N的大
音樂、視訊播放模式切換實現方案及原理解析(基於vue、vuex、h5 audio)
音樂、視訊播放模式切換實現方案及原理解析(基於vue、vuex、h5 audio) 播放模式有三種: 順序播放 隨機播放 單曲迴圈 定義為一個playMode物件並向外暴露,內含三種播放模式,即為: export const playMode = { sequen
如何將一個shape為(10000,3072)的陣列(畫素點為32x32)轉換為相應的圖片
10000行代表有10000張圖片,每一行有3072個數據,可以理解為32X32X3代表了畫素為32X32的RGB三通道彩色圖片 例如,現在要取第2張圖片 image是一個(10000,3072)的陣列 image[i]取出第i行,然後分別取出RGB的三個1024
java實現K-means演算法,k-means聚類演算法原理
/** * 需要所有point 以及族中心list * * @author:Yien * @when:2018年5月20日下午3:14:09 * @Description:TOD
在Spark SQL對人類資料實現K-Means聚類,並對聚類中心格式化輸出
簡介 本篇博文對UCI提供的 Machine-Learning-Databases 資料集進行資料分析,並通過K-Means模型實現聚類,最後格式化輸出聚類中心點。 本文主要包括以下內容: 通過VectorAssembler來將多列資料合成一列features
通過IDEA及hadoop平臺實現k-means聚類算法
綜合 tle tostring html map apache cnblogs cos textfile 有段時間沒有操作過,發現自己忘記一些步驟了,這篇文章會記錄相關步驟,並隨時進行補充修改。 1 基礎步驟,即相關環境部署及數據準備 數據文件類型為.csv文件,excel
使用Java實現K-Means聚類演算法
第一次寫部落格,隨便寫寫。 關於K-Means介紹很多,還不清楚可以查一些相關資料。 個人對其實現步驟簡單總結為4步: 1.選出k值,隨機出k個起始質心點。 2.分別計算每個點和k個起始質點之間的距離,就近歸類。 3.最終中心點集可以劃分為k類,
利用Python實現K-Means聚類並進行圖形化展示
利用K-means進行聚類,顯示聚類結果的各類別的數量,最終進行圖形化展示 。 import pandas as pd import numpy as np import matplotlib.pyplot as plt from scipy import stats import c
Python實現K-Means聚類演算法
宣告:程式碼的執行環境為Python3。Python3與Python2在一些細節上會有所不同,希望廣大讀者注意。本部落格以程式碼為主,程式碼中會有詳細的註釋。相關文章將會發布在我的個人部落格專欄《Python從入門到深度學習》,歡迎大家關注~
JAVA實現K-means聚類
個人部落格站已經上線了,網址 www.llwjy.com ~歡迎各位吐槽~-------------------------------------------------------------------------------------------------
java實現k-means演算法(用的鳶尾花iris的資料集,從mysq資料庫中讀取資料)
k-means演算法又稱k-均值演算法,是機器學習聚類演算法中的一種,是一種基於形心的劃分方法,其中每個簇的中心都用簇中所有物件的均值來表示。其思想如下: 輸入: k:簇的數目;D:包含n個物件的資料集。輸出:k個簇的集合。 方法: 從D中隨機選擇幾個物件作為起始質心
C#實現軟體授權,限定MAC執行(軟體license管理,簡單軟體註冊機制)
最近做了一個綠色免安裝軟體,領導臨時要求加個註冊機制,不能讓現場工程師隨意複製。事出突然,只能在現場開發(離開現場軟體就不受我們控了)。花了不到兩個小時實現了簡單的註冊機制,稍作整理。 基本原理:1.軟體一執行就把計算機的CPU、主機板、BIOS、MAC地址記錄下來,然後加密(key=key1)生成
spark 實現K-means演算法
spark 實現K-means演算法 package kmeans; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFou
C#實現K-近鄰(KNN)演算法
KNN(k-nearest-neighbor)演算法的思想是找到在輸入新資料時,找到與該資料最接近的k個鄰居,在這k個鄰居中,找到出現次數最多的類別,對其進行歸類。 Iris資料集是常用的分類實驗資料集,由Fisher, 1936收集整理。Iris也稱鳶尾花卉資料集,是一類多重變數分析的資料
C#實現SMTP伺服器,使用TCP命令實現,功能比較完善
using System;using System.Text;using System.IO;using System.Net;using System.Net.Sockets;using System.Collections; namespace SkyDev.Web.Ma
【機器學習實戰之一】:C++實現K-近鄰演算法KNN
本文不對KNN演算法做過多的理論上的解釋,主要是針對問題,進行演算法的設計和程式碼的註解。 KNN演算法: 優點:精度高、對異常值不敏感、無資料輸入假定。 缺點:計算複雜度高、空間複雜度高。 適用資料範圍:數值型和標稱性。 工作原理:存在一個樣本資料集合,也稱作訓練樣本集,
python 手寫實現k-means
今天手寫實現了k-means,目的是加深對這個演算法原理的理解,有不足的地方請多指教。ris鳶尾花資料集包含3個不同品種的鳶尾花(Setosa,Versicolour,and Virginica)資料,花瓣和萼片長度,儲存在一個150*4的 numpy.ndarry中150行
Python實現K-means程式碼詳解(新手上路)
#coding=utf-8 2 from numpy import * 3 4 def loadDataSet(fileName): 5 dataMat = [] 6 fr = open(fileName) 7 for line in fr.readli
譜聚類原理簡述(含實驗程式碼)
Spectral clustering(譜聚類) 是一種基於圖論的聚類方法,它能夠識別任意形狀的樣本空間並收斂於全域性最優解。其基本的思想是將樣本資料進行相似性計算得到相似度矩陣,然後將相似矩陣轉換到Laplacian 矩陣 (拉普拉斯矩陣),做 Laplacian 矩陣
C# 實現MDI子窗體只打開一個(開啟新的視窗,關閉其他視窗)
1.private Form m_CurrentMdiChild;//宣告窗體 2.開啟你想要的視窗private void ShowForm(){Form1 frm = new Form1();frm.ShowMdiChild(frm)