
大規模機器學習:SGD,mini-batch和MapReduce
機器學習在這幾年得到快速發展,一個很重要的原因是 Large Dataset(大規模資料),這節課就來介紹用機器學習演算法處理大規模資料的問題。
關於資料的重要性,有一句話是這麼說的:
It’s not who has the best algorithm that wins.
It’s who has the most data.
然而,當資料量過大時,計算的複雜度會增加,計算成本也會提高。假如資料量是一百萬,使用梯度下降演算法來訓練引數,每走一步,需要對百萬資料進行求和計算,這樣的計算量是極大的。但現實問題總是有大量資料,比如全國的車輛、網民等等。那麼,我們就有必要研究一下如何更好地處理大規模資料。
方案一:Stochastic Gradient Descent
以 linear regression 為例,先開看看我們原來的梯度下降演算法:
圖中給出了要求的model h(x)、目標函式J、以及梯度下降演算法(迴圈部分)。迭代的過程:每一步使用所有資料計算θ,並重新賦值,然後下一步再使用所有資料和上一步求得的θ更新θ。圖中右側,中心點是最優點,θ從起始點,每迭代一步就像中心點移動一步,最終走到中心點求出θ最優值。這裡的問題是,每迭代一步,就需要計算所有資料(如百萬資料)。
上述梯度下降演算法也叫 batch gradient descent 。下面我們做些改進,以適應大資料的情況。

上圖右側,我們改變了迭代形式。對於訓練集中每個資料,fit θ,使得模型符合這個資料,然後用第二個資料走同樣步驟,以此類推。也就是說,每個資料都能獲得目前為止最優的θ。這樣的迭代,我們稱為 stochastic gradient descent 。
需要注意:迭代之前,需要 randomly shuffle training example. 因為資料的不同使用次序,得到的結果不盡相同。
下面給出該演算法的步驟和演示圖:
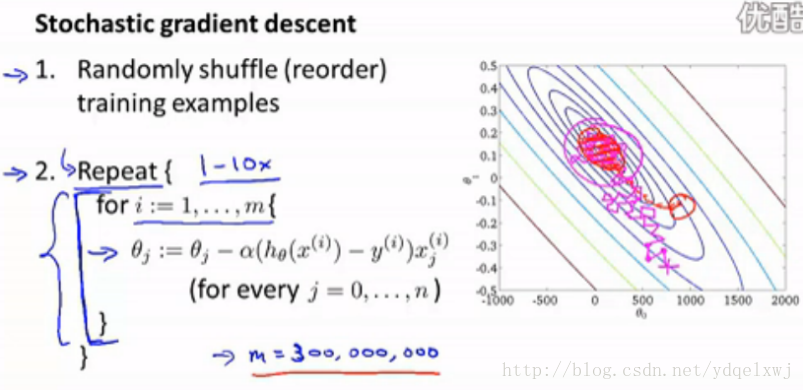
從演示圖可以看出,θ最後可能圍繞最優點左右搖擺而達不到最優點。θ甚至可能不會converge。那麼,怎麼檢查θ能否converge呢?
每迭代n個數據(eg.1000),使用目前得到的θ,計算這n個數據的cost,並繪製在橫座標為迭代次數、縱座標為cost的座標系中。隨著迭代次數增加,座標系中的曲線越來越長。觀察曲線形狀,如果一直呈下降趨勢,那麼說明可以converge,如果一直上下搖擺或者上升趨勢,就說明無法converge。對於後者,可以隨著迭代次數的增加逐漸減小α(學習速度),就可以保證θ可以converge。
一個應用:Online learning
Online learning 是根據不斷湧入的新資料更新θ從而改進我們的model。例如一個貨運訂單系統,使用者輸入出發地、目的地,網站會給出價格,使用者會選擇下單或取消。這裡的model就是,給出使用者特徵和出發地、目的地,通過model得出適當價格。這是一個 logistic regress 問題。每當有一個使用者進行上述行為,我們的訓練集就動態增加了一個數據,這樣就可以使用 stochastic gradient descent 動態優化model。
方案二: Mini-Batch Gradient Descent
在 batch gradient descent 中,我們每次迭代使用全部m個數據。
在 stochastic gradient descent 中,每次迭代使用1個數據。
在 Mini-Batch Gradient Descent 中,每次迭代用b(2-m)個數據,算作一種折中方案。b即為 mini-batch 。
結合上面兩個演算法,第三個演算法很容易理解,如下:

方案三:Map Reduce and Data Parallelism
當資料量很大,我們又希望使用 batch gradient descent 時,可以將資料分割並分佈到不同 的機器上進行區域性運算,然後彙總。
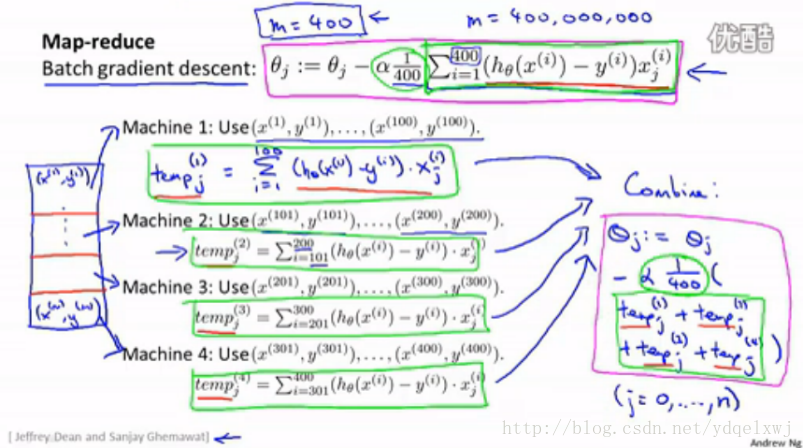
圖中,把迭代式加和的部分分割開,400個數據分佈到4臺機器上,每臺機器同步處理100個數據,
最後將四個結果再相加,得到迭代式中加和項的結果。
總的來說,對於大資料,或者分佈到不同機器上同步處理,或者使用單資料迭代的演算法。
相關推薦
大規模機器學習:SGD,mini-batch和MapReduce
機器學習在這幾年得到快速發展,一個很重要的原因是 Large Dataset(大規模資料),這節課就來介紹用機器學習演算法處理大規模資料的問題。 關於資料的重要性,有一句話是這麼說的: It’s not who has the best algorithm that wins. It’s who h
機器學習:Regression,第一個簡單的示例,多項式迴歸
# -*- coding: utf-8 -*- # 匯入需要的庫 import numpy as np import matplotlib.pyplot as plt # 定義儲存輸入資料x,目標資料y x,y = [],[] # 遍歷資料集,並把資料按照順序存在對應的list #
概率統計與機器學習:期望,方差,數學期望,樣本均值,樣本方差之間的區別
1.樣本均值:我們有n個樣本,每個樣本的觀測值為Xi,那麼樣本均值指的是 1/n * ∑x(i),求n個觀測值的平均值 2.數學期望:就是樣本均值,是隨機變數,即樣本數其實並不是確定的 PS:從概率
機器學習:支援向量機SVM和人工神經網路ANN的比較
在統計學習理論中發展起來的支援向量機(Support Vector Machines, SVM)方法是一種新的通用學習方法,表現出理論和實踐上的優勢。SVM在非線性分類、函式逼近、模式識別等應用中有非常好的推廣能力,擺脫了長期以來形成的從生物仿生學的角度構建學習機器的束縛。
Ng第十七課:大規模機器學習(Large Scale Machine Learning)
在線 src 化簡 ima 機器學習 learning 大型數據集 machine cnblogs 17.1 大型數據集的學習 17.2 隨機梯度下降法 17.3 微型批量梯度下降 17.4 隨機梯度下降收斂 17.5 在線學習 17.6 映射化簡和數據並行
斯坦福大學公開課機器學習:Neural Networks,representation: non-linear hypotheses(為什麽需要做非線性分類器)
繼續 例子 產生 成本 log repr 概率 .cn 成了 如上圖所示,如果用邏輯回歸來解決這個問題,首先需要構造一個包含很多非線性項的邏輯回歸函數g(x)。這裏g仍是s型函數(即 )。我們能讓函數包含很多像這的多項式,當多項式足夠多時,那麽你也許能夠得到可以
斯坦福大學公開課機器學習:machine learning system design | data for machine learning(數據量很大時,學習算法表現比較好的原理)
ali 很多 好的 info 可能 斯坦福大學公開課 數據 div http 下圖為四種不同算法應用在不同大小數據量時的表現,可以看出,隨著數據量的增大,算法的表現趨於接近。即不管多麽糟糕的算法,數據量非常大的時候,算法表現也可以很好。 數據量很大時,學習算法表現比
機器學習:K近鄰演算法,kd樹
https://www.cnblogs.com/eyeszjwang/articles/2429382.html kd樹詳解 https://blog.csdn.net/v_JULY_v/article/details/8203674 一、K-近鄰演算法(KNN)概述
機器學習筆記 第4課:偏差,方差和權衡
經由偏差 - 方差的權衡,我們可以更好地理解機器學習演算法。 偏差(bias)是模型所做的簡化假設,其目的是更容易地學習目標函式。 通常,引數演算法具有高偏差。它們學習起來很快,且易於理解,但通常不太靈活。反過來,它們對複雜問題的預測效能較低,無法滿足演算法偏差的簡化假設。 決策樹是一種
機器學習:訓練集,驗證集與測試集
來源:http://mooc.study.163.com/learn/2001281003?tid=2001391036#/learn/content?type=detail&id=2001702114&cid=2001693028 作用 訓練集:用於訓練模型的
機器學習筆記(十六):大規模機器學習
目錄 1)Learning with large datasets 2)Stochastic gradient descent 3)Mini-batch gradient descent 4)Stochastic gradient descent convergence 1)
機器學習:整合學習(ensemble),bootstrap,Bagging,隨機森林,Boosting
文章目錄 整合學習的樸素思想 Bootstrap理論 Bagging 隨機森林 Boosting 整合學習的樸素思想 整合學習基於這樣的思想:對於比較複雜的任務,綜合許多人的意見來進行決策會比“一家獨大”要更好。換句話說、就
機器學習:決策樹過擬合與剪枝,決策樹程式碼實現(三)
文章目錄 楔子 變數 方法 資料預處理 剪枝 獲取待剪集: 針對ID3,C4.5的剪枝 損失函式的設計 基於該損失函式的演算法描述 基於該損失函式的程式碼實
機器學習:結點的實現,決策樹程式碼實現(二)
文章目錄 楔子 定義變數: 定義方法 獲得劃分的feature 生成結點 停止條件及其處理 fit() 生成樹剪枝 楔子 前面已經實現了各種資訊量的計算,那麼我們劃分的基本有了,那
機器學習:資訊熵,基尼係數,條件熵,條件基尼係數,資訊增益,資訊增益比,基尼增益,決策樹程式碼實現(一)
文章目錄 初始化,涉及到使用的變數: 資訊熵 定義公式,經驗公式 程式碼: 基尼係數 定義公式,經驗公式 程式碼: 條件熵,條件基尼係數 條件熵定義公式,經驗公式
機器學習:樸素貝葉斯分類器,決策函式向量化處理,mask使用技巧
文章目錄 前面實現的樸素貝葉斯分類器,決策函式是非向量化的: 藉助於numpy向量化處理,相當於平行計算,注意mask使用技巧,用途較廣: 前面實現的樸素貝葉斯分類器,決策函式是非向量化的: 前面提到過大資料處理,儘量避免個人的遍歷等一些函式
機器學習:樸素貝葉斯分類器程式碼實現,決策函式非向量化方式
文章目錄 樸素貝葉斯離散型的演算法描述: 程式碼實現: 實現一個NaiveBayes的基類,以便擴充套件: 實現離散型樸素貝葉斯MultiomialNB類: 實現從檔案中讀取資料: 測試資料: 程式碼測試:
機器學習:貝葉斯分類器,樸素貝葉斯,拉普拉斯平滑
數學基礎: 數學基礎是貝葉斯決策論Bayesian DecisionTheory,和傳統統計學概率定義不同。 頻率學派認為頻率是是自然屬性,客觀存在的。 貝葉斯學派,從觀察這出發,事物的客觀隨機性只是觀察者不知道結果,也就是觀察者的知識不完備,對於知情者而言,事物沒有隨機性,隨機
概率統計與機器學習:獨立同分布,極大似然估計,線性最小二乘迴歸
獨立同分布 獨立性 概念:事件A,B發生互不影響 公式:P(XY)=P(X)P(Y) , 即事件的概率等於各自事件概率的乘積 舉例: 正例:兩個人同時向上拋硬幣,兩個硬幣均為正面的概率 反例:獅子在某地區出現的概率為X,老虎出現概率為Y,同時出現
機器學習公開課筆記(10):大規模機器學習
批梯度下降 (Batch Gradient Descent) 以線性迴歸為例,用梯度下降演算法進行引數更新的公式為$$\theta_j=\theta_j-\alpha\frac{1}{m}\sum\limits_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})x_j^{(i)}$$可