
solr叢集搭建和 java呼叫 solr叢集
solrClund 是solr提供的分散式搜尋方案
solrClund 是基於solr和zookeeper的分散式搜尋方案,
主要思想是使用zookeeper作為叢集的配置中心
特色功能:
1.集中式的配置資訊
2.自動容錯
3.近實時搜尋
4.查詢時自動負載均衡
zookeeper:動物園管理員,用於管hadoop(大象)、Hive(蜜蜂)的管理員
SolrCloud結構
需要由多臺伺服器共同完成索引和搜尋任務
實現的思路是將索引資料進行shard(分片) 拆分,每個分片由多臺的伺服器共
同完成。當一個索引或搜尋請求過來時會分別從不同的shard的伺服器中操作
索引。
solrCloud需要 solr基於zookeeper部署,zookeeper是一個叢集管理軟體,
由solrCloud需要由多臺伺服器組成。由zookeeper來進行協調管理
多個分片相加起來才是一個完成的索引庫
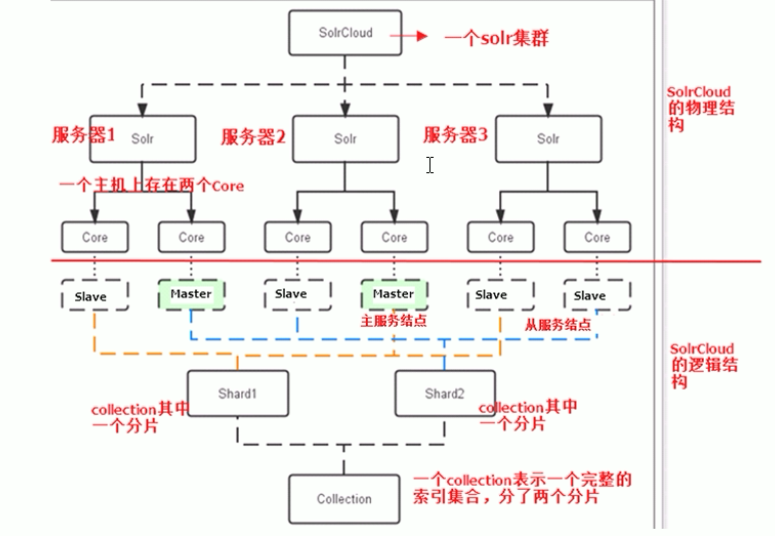
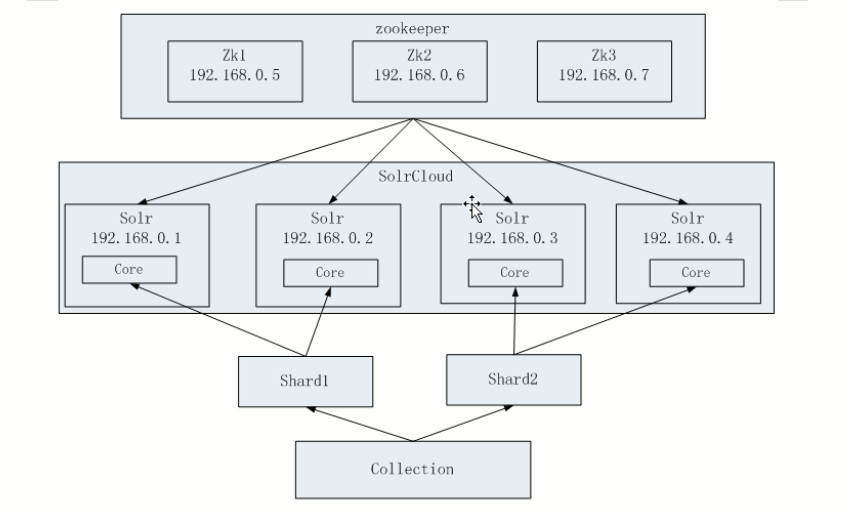
伺服器數量:
zookeeper:3臺伺服器
solr:4臺伺服器
叢集搭建
zookeeper叢集:
zookeeper有一個選舉機制,選舉誰是leader,誰是follower,成為主
節點,需要得到半數以上的投票。所以儘可能為奇數節點
1.建立三個zookeeper例項:
2.分別在zookeeper資料夾下,建立data資料夾,下面建立myid(內容為1、2、3)
3.在E:\solr\solrColud\zookeeper1\conf 下將zoo_sample.cfg更名為zoo.cfg
#myid檔案的位置
dataDir=E:/solr/solrColud/zookeeper1/data 4.啟動zookeeper,三臺都啟動成功,則不再報錯
solr例項
1.啟動4個tomcat例項
2.搭建4個單機版solr例項
3.需改tomcat的埠號:
8080
8081
8082
8083
4.需改solrhome的位置
叢集搭建
1.讓zookeeper叢集集中管理配置檔案,把配置檔案上傳到zookeeper
2.將E:\solr\solrColud\solrhome1\collection1\conf 下面的內容上傳到zookeeper叢集中
3.在cmd 中 ,命令上傳檔案:
java -classpath E:\solr\solrColud\apache-tomcat1\webapps\solr\WEB-INF\lib/* org.apache.solr.cloud.ZkCLI -zkhost 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183 -cmd upconfig -confdir E:\solr\solrColud\solrhome1\collection1\conf -confname myconf4.檢視上傳的檔案:有myconf說明上傳成功

5.修改每個solrhome下的solr.xml檔案
<solr>
<solrcloud>
//solr每個例項對應的ip
<str name="host">${host:127.0.0.1}</str>
//tomcal的埠
<int name="hostPort">${jetty.port:8080}</int>
<str name="hostContext">${hostContext:solr}</str>
<int name="zkClientTimeout">${zkClientTimeout:30000}</int>
<bool name="genericCoreNodeNames">${genericCoreNodeNames:true}</bool>
</solrcloud>
<shardHandlerFactory name="shardHandlerFactory"
class="HttpShardHandlerFactory">
<int name="socketTimeout">${socketTimeout:0}</int>
<int name="connTimeout">${connTimeout:0}</int>
</shardHandlerFactory>
</solr>6.告訴每個solr例項,zookeeper叢集的位置
修改每一臺 tomcat的bin目錄下catalina.bat檔案中加入DzkHost指定
zookeeper伺服器地址
set JAVA_OPTS="-DzkHost=127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183"7.啟動所有tomcat
8.訪問solr
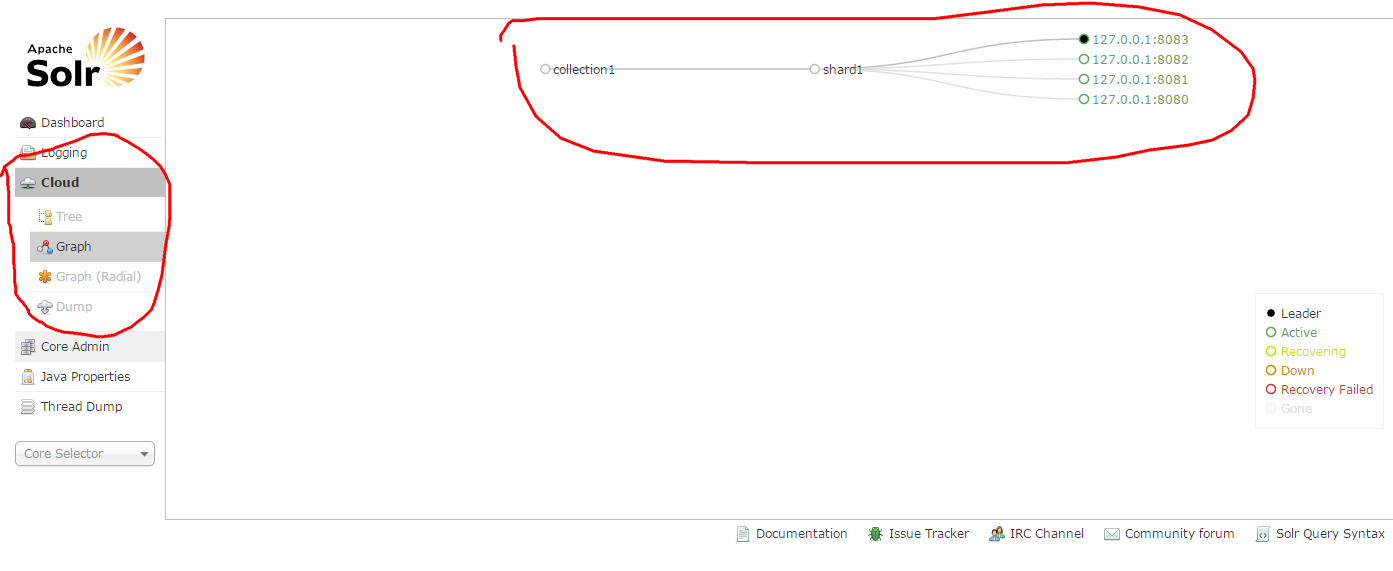
9.現在只有一片,1個主,三個備
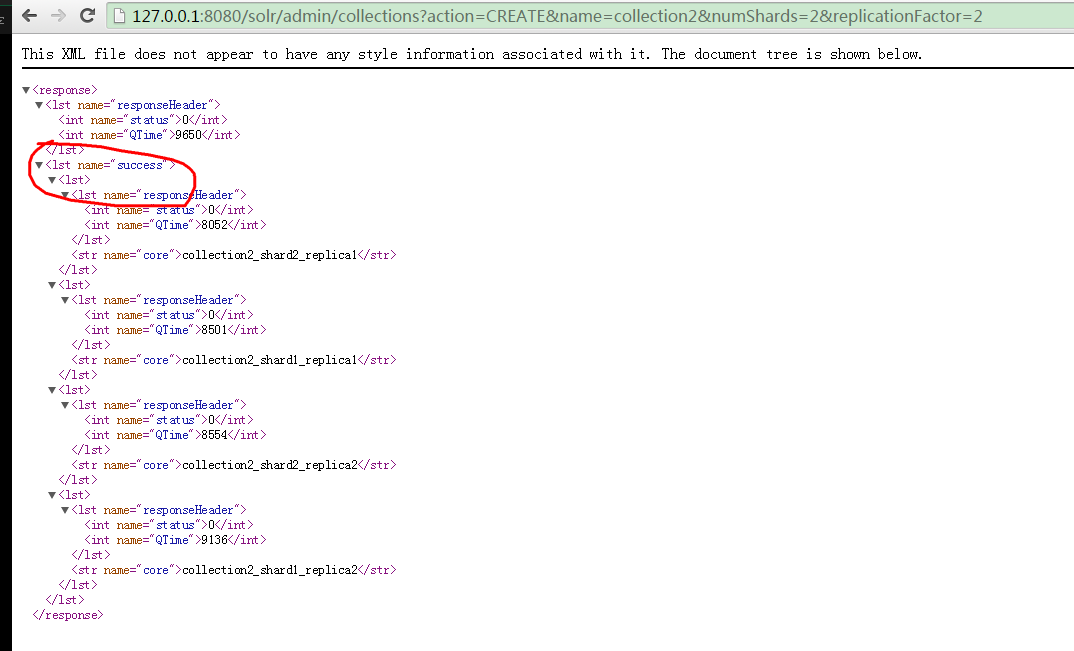
10.使用命令進行分片,兩分的叢集
http://127.0.0.1:8080/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=2
11.表示建立切片成功,每一片都是一主一備
12刪除叢集的命令:
http://127.0.0.1:8080/solr/admin/collections?action=DELETE&name=collection1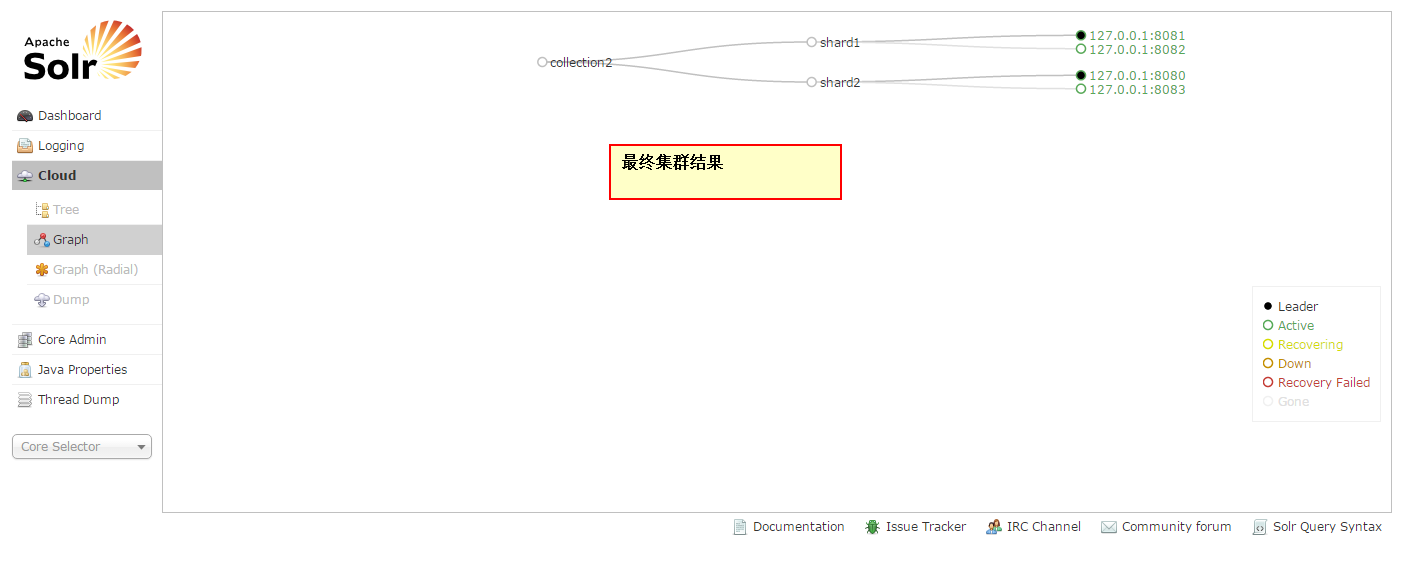
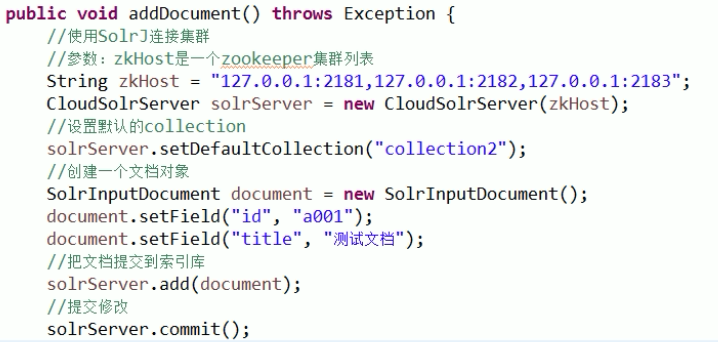
java呼叫 solr叢集
//新增文件
相關推薦
solr叢集搭建和 java呼叫 solr叢集
solrClund 是solr提供的分散式搜尋方案 solrClund 是基於solr和zookeeper的分散式搜尋方案, 主要思想是使用zookeeper作為叢集的配置中心 特色功能: 1.集中式的配置資訊 2.自動容錯 3.近實時搜尋 4.查
kafka叢集搭建和使用Java寫kafka生產者消費者
http://czj4451.iteye.com/blog/2041096 server.properties 需要配置 broker.id=110 host.name=192.168.1.108 zookeeper.connect=192.168.1.108:2181 log.dirs=/
MongoDB叢集搭建與java程式碼操作MongoDB示例
MongoDB叢集搭建與java程式碼操作MongoDB示例 MongoDB叢集搭建過程 java使用MongoDB叢集Demo MongoDB叢集搭建過程 1. MongoDB Replica set叢集搭建準備(主從仲裁) 介
Zookeeper叢集搭建和Kafka叢集的搭建
Zookeeper!!! 一、Zookeeper叢集搭建步驟 0)叢集規劃 在hadoop01、hadoop02和hadoop03三個節點上部署Zookeeper。 1)解壓安裝 (1)解壓zookeeper安裝包到/home/hadoop/insatll/目錄下 [[email
zookeeper叢集搭建和常用命令(筆記)
1.下載zookeeper安裝包 linux的套路是,一般都會把安裝檔案放到/opt下 wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeepe
在Flink叢集搭建和使用中遇到的坑
一、專案概況 使用Flink測試中間狀態設定checkpoint和從checkpoint中恢復。 二、搭建中出現的問題 Flink的叢集搭建中需要配置中間狀態快取的路徑(專案中使用到的是在hdfs中儲存中間狀態) 在叢集中需要配置的專案是(如果需要中間狀態的儲存,這個必須的):
ZooKeeper 叢集搭建和使用
ZooKeeper 叢集搭建 1,ZooKeeper 叢集搭建須知 節點數奇數臺 2,下載安裝包 3,上傳並解壓 解壓:tar -zxvf zookeeper-3.4.10.tar.gz 4,修改配置檔案zoo.cfg 進入 ZOOKEEPER_HO
HAproxy叢集搭建和配置
1.準備四臺web伺服器30.40.50.60, 一臺20排程器,一臺10測試主機 搭建httpd+mysql+php 網站 根目錄下建立三個檔案 [[email protected] ~]# echo 192.168.4.50 > /var/www/html
redis詳解——redis叢集搭建和使用(二)
上一章我寫到redis簡單的介紹和如何單機的使用,當我們redis相當重要的時候那麼接下來就需要搭建一個叢集了。 1 Redis叢集的介紹 1.1 redis-cluster(叢集)架構圖 架構細節: (1)所有的redis節點彼此互聯(PING-PONG機制),
HBase 叢集搭建和高可用配置
HBase叢集建立在hadoop叢集基礎之上,所以在搭建HBase叢集之前需要把Hadoop叢集搭建起來,並且要考慮二者的相容性.現在就以3臺機器為例,搭建一個簡單的叢集. 1.進入hbase的配置目錄,在hbase-env.sh檔案裡面加入java環境變數.即: JAVA_HOME=exp
Centos7 實現Hadoop-2.9.1分散式叢集搭建和部署(三臺機器)
一、準備三臺虛擬機器hadoop 192.168.131.128 localhost131 192.168.131.131 localhost134 192.168.131.134(以上是我的三臺虛擬機器的hostname 和 ip)hadoop 是 master 的 hos
Linux rhel7.0 pacemaker叢集搭建和配置
一 叢集環境介紹 一 Linux 叢集發展史 高可用叢集的層次結構1 訊息/基礎架構 corosync 2 成員關係 :監聽心跳資訊,並進行處理成員關係和計算成員關係的票數等資訊3 資源管理 VIP 磁碟 檔案系統 CRM (群集資源管理器)等,有些策略引擎(有些資源是放置在同一個節點和其依賴關係) 和資
RabbitMQ3.6.5叢集搭建和遇到的問題
RabbitMQ3.6.5叢集搭建 搭建環境: 非單機叢集,使用VMware Workstation建立三臺獨立的虛擬機器(橋接模式)。ip地址分別為:192.168.0.113 、192.168.0.116、 192.168.0.119 搭
hadoop學習第二天~Hadoop2.6.5完全分散式叢集搭建和測試
環境配置: 系統 centos7 節點 192.168.1.111 namenode 192.168.1.115 datanode2 192.168.1.116 datanode3 java 環境 :
ElasticSearch 叢集搭建和視覺化外掛安裝
文章目錄 1.單機版的搭建 1) 進入bin目錄下,直接執行elasticsearch 命令 2) 訪問 http://localhost:9200/
kafka叢集配置和java編寫生產者消費者操作例子
kafka 安裝 修改配置檔案 java操作kafka kafka kafka的操作相對來說簡單很多 安裝 下載kafka http://kafka.apache.org/downloads tar -zxvf kafka_2.12-2.1
Redis 叢集搭建和簡單使用教程
##一臺機器<br>ps -ef | grep redis root 61020 1 0 02:14 ? 00:00:01 redis-server 127.0.0.1:7000 [cluster] root 61024 1 0 02:14 ? 00:00:01 redis-ser
zk叢集搭建以及java客戶端連線zk
專案終於不忙了.閒來無事,想起上次面試被人問了一個zk把我給問住了.看來要好好了解一下zk了.於是開始了zk的學習之路. 首先帶大家搭建一下zk叢集環境,這個很簡單,我就不說那麼詳細了, 首先準備三臺機器,來安裝zk叢集 要有root許可權,因為要改hosts 下
hdfs偽分散式叢集搭建和部署詳解
大家好,這是我的第一篇技術部落格,也是第一篇部落格,請大家多多支援。我寫部落格的初衷無非是對所學知識的回顧和總結,同時能與廣大的讀者一起探討,共同進步,這是一件非常令人開心的事。 部落格的內容大都是大資料技術相關,今天要說的是hadoop,以後會可能還會更新
Redis 叢集搭建和測試教程
請注意,本教程使用於Redis3.0(包括3.0)以上版本 Redis叢集介紹 Redis 叢集是一個提供在多個Redis間節點間共享資料的程式集。 Redis叢集並不支援處理多個keys的命令,因為這需要在不同的節點間移動資料,從而達不到像Redis那樣的效能,在高