
基於Flume的美團日誌收集系統(一)架構和設計
阿新 • • 發佈:2019-01-28
美團的日誌收集系統負責美團的所有業務日誌的收集,並分別給Hadoop平臺提供離線資料和Storm平臺提供實時資料流。美團的日誌收集系統基於Flume設計和搭建而成。
《基於Flume的美團日誌收集系統》將分兩部分給讀者呈現美團日誌收集系統的架構設計和實戰經驗。
第一部分架構和設計,將主要著眼於日誌收集系統整體的架構設計,以及為什麼要做這樣的設計。
第二部分改進和優化,將主要著眼於實際部署和使用過程中遇到的問題,對Flume做的功能修改和優化等。
1 日誌收集系統簡介
日誌收集是大資料的基石。
許多公司的業務平臺每天都會產生大量的日誌資料。收集業務日誌資料,供離線和線上的分析系統使用,正是日誌收集系統的要做的事情。高可用性,高可靠性和可擴充套件性是日誌收集系統所具有的基本特徵。
目前常用的開源日誌收集系統有Flume, Scribe等。Flume是Cloudera提供的一個高可用的,高可靠的,分散式的海量日誌採集、聚合和傳輸的系統,目前已經是Apache的一個子專案。Scribe是Facebook開源的日誌收集系統,它為日誌的分散式收集,統一處理提供一個可擴充套件的,高容錯的簡單方案。
2 常用的開源日誌收集系統對比
3 美團日誌收集系統架構
美團的日誌收集系統負責美團的所有業務日誌的收集,並分別給Hadoop平臺提供離線資料和Storm平臺提供實時資料流。美團的日誌收集系統基於Flume設計和搭建而成。目前每天收集和處理約T級別的日誌資料。
下圖是美團的日誌收集系統的整體框架圖。
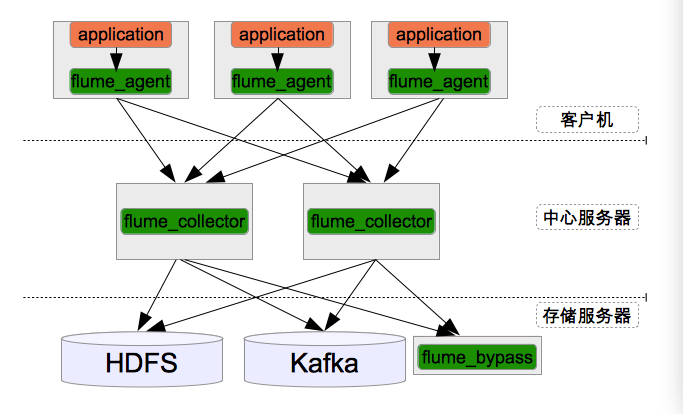
a. 整個系統分為三層:Agent層,Collector層和Store層。其中Agent層每個機器部署一個程序,負責對單機的日誌收集工作;Collector層部署在中心伺服器上,負責接收Agent層傳送的日誌,並且將日誌根據路由規則寫到相應的Store層中;Store層負責提供永久或者臨時的日誌儲存服務,或者將日誌流導向其它伺服器。 b. Agent到Collector使用LoadBalance策略,將所有的日誌均衡地發到所有的Collector上,達到負載均衡的目標,同時並處理單個Collector失效的問題。 c. Collector層的目標主要有三個:SinkHdfs, SinkKafka和SinkBypass。分別提供離線的資料到Hdfs,和提供實時的日誌流到Kafka和Bypass。其中SinkHdfs又根據日誌量的大小分為SinkHdfs_b,SinkHdfs_m和SinkHdfs_s三個Sink,以提高寫入到Hdfs的效能,具體見後面介紹。 d. 對於Store來說,Hdfs負責永久地儲存所有日誌;Kafka儲存最新的7天日誌,並給Storm系統提供實時日誌流;Bypass負責給其它伺服器和應用提供實時日誌流。 下圖是美團的日誌收集系統的模組分解圖,詳解Agent, Collector和Bypass中的Source, Channel和Sink的關係。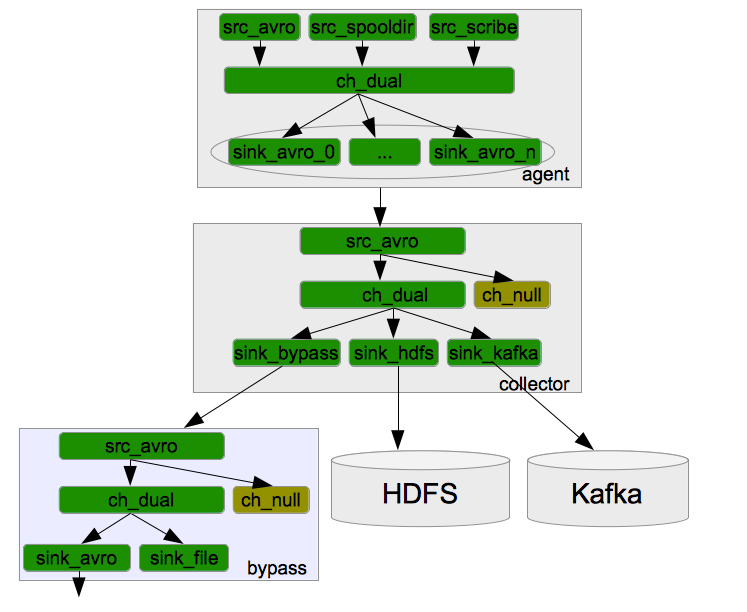
a. 模組命名規則:所有的Source以src開頭,所有的Channel以ch開頭,所有的Sink以sink開頭; b. Channel統一使用美團開發的DualChannel,具體原因後面詳述;對於過濾掉的日誌使用NullChannel,具體原因後面詳述; c. 模組之間內部通訊統一使用Avro介面; 4 架構設計考慮 下面將從可用性,可靠性,可擴充套件性和相容性等方面,對上述的架構做細緻的解析。 4.1 可用性(availablity) 對日誌收集系統來說,可用性(availablity)指固定週期內系統無故障執行總時間。要想提高系統的可用性,就需要消除系統的單點,提高系統的冗餘度。下面來看看美團的日誌收集系統在可用性方面的考慮。 4.1.1 Agent死掉 Agent死掉分為兩種情況:機器宕機或者Agent程序死掉。 對於機器宕機的情況來說,由於產生日誌的程序也同樣會死掉,所以不會再產生新的日誌,不存在不提供服務的情況。 對於Agent程序死掉的情況來說,確實會降低系統的可用性。對此,我們有下面三種方式來提高系統的可用性。首先,所有的Agent在supervise的方式下啟動,如果程序死掉會被系統立即重啟,以提供服務。其次,對所有的Agent進行存活監控,發現Agent死掉立即報警。最後,對於非常重要的日誌,建議應用直接將日誌寫磁碟,Agent使用spooldir的方式獲得最新的日誌。 4.1.2 Collector死掉 由於中心伺服器提供的是對等的且無差別的服務,且Agent訪問Collector做了LoadBalance和重試機制。所以當某個Collector無法提供服務時,Agent的重試策略會將資料傳送到其它可用的Collector上面。所以整個服務不受影響。 4.1.3 Hdfs正常停機 我們在Collector的HdfsSink中提供了開關選項,可以控制Collector停止寫Hdfs,並且將所有的events快取到FileChannel的功能。 4.1.4 Hdfs異常停機或不可訪問 假如Hdfs異常停機或不可訪問,此時Collector無法寫Hdfs。由於我們使用DualChannel,Collector可以將所收到的events快取到FileChannel,儲存在磁碟上,繼續提供服務。當Hdfs恢復服務以後,再將FileChannel中快取的events再發送到Hdfs上。這種機制類似於Scribe,可以提供較好的容錯性。 4.1.5 Collector變慢或者Agent/Collector網路變慢 如果Collector處理速度變慢(比如機器load過高)或者Agent/Collector之間的網路變慢,可能導致Agent傳送到Collector的速度變慢。同樣的,對於此種情況,我們在Agent端使用DualChannel,Agent可以將收到的events快取到FileChannel,儲存在磁碟上,繼續提供服務。當Collector恢復服務以後,再將FileChannel中快取的events再發送給Collector。 4.1.6 Hdfs變慢 當Hadoop上的任務較多且有大量的讀寫操作時,Hdfs的讀寫資料往往變的很慢。由於每天,每週都有高峰使用期,所以這種情況非常普遍。 對於Hdfs變慢的問題,我們同樣使用DualChannel來解決。當Hdfs寫入較快時,所有的events只經過MemChannel傳遞資料,減少磁碟IO,獲得較高效能。當Hdfs寫入較慢時,所有的events只經過FileChannel傳遞資料,有一個較大的資料快取空間。 4.2 可靠性(reliability) 對日誌收集系統來說,可靠性(reliability)是指Flume在資料流的傳輸過程中,保證events的可靠傳遞。 對Flume來說,所有的events都被儲存在Agent的Channel中,然後被髮送到資料流中的下一個Agent或者最終的儲存服務中。那麼一個Agent的Channel中的events什麼時候被刪除呢?當且僅當它們被儲存到下一個Agent的Channel中或者被儲存到最終的儲存服務中。這就是Flume提供資料流中點到點的可靠性保證的最基本的單跳訊息傳遞語義。 那麼Flume是如何做到上述最基本的訊息傳遞語義呢? 首先,Agent間的事務交換。Flume使用事務的辦法來保證event的可靠傳遞。Source和Sink分別被封裝在事務中,這些事務由儲存event的儲存提供或者由Channel提供。這就保證了event在資料流的點對點傳輸中是可靠的。在多級資料流中,如下圖,上一級的Sink和下一級的Source都被包含在事務中,保證資料可靠地從一個Channel到另一個Channel轉移。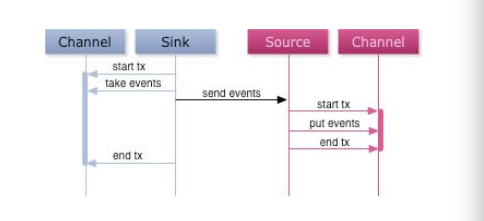
其次,資料流中 Channel的永續性。Flume中MemoryChannel是可能丟失資料的(當Agent死掉時),而FileChannel是永續性的,提供類似mysql的日誌機制,保證資料不丟失。 4.3 可擴充套件性(scalability) 對日誌收集系統來說,可擴充套件性(scalability)是指系統能夠線性擴充套件。當日志量增大時,系統能夠以簡單的增加機器來達到線性擴容的目的。 對於基於Flume的日誌收集系統來說,需要在設計的每一層,都可以做到線性擴充套件地提供服務。下面將對每一層的可擴充套件性做相應的說明。 4.3.1 Agent層 對於Agent這一層來說,每個機器部署一個Agent,可以水平擴充套件,不受限制。一個方面,Agent收集日誌的能力受限於機器的效能,正常情況下一個Agent可以為單機提供足夠服務。另一方面,如果機器比較多,可能受限於後端Collector提供的服務,但Agent到Collector是有Load Balance機制,使得Collector可以線性擴充套件提高能力。 4.3.2 Collector層 對於Collector這一層,Agent到Collector是有Load Balance機制,並且Collector提供無差別服務,所以可以線性擴充套件。其效能主要受限於Store層提供的能力。 4.3.3 Store層 對於Store這一層來說,Hdfs和Kafka都是分散式系統,可以做到線性擴充套件。Bypass屬於臨時的應用,只對應於某一類日誌,效能不是瓶頸。 4.4 Channel的選擇 Flume1.4.0中,其官方提供常用的MemoryChannel和FileChannel供大家選擇。其優劣如下: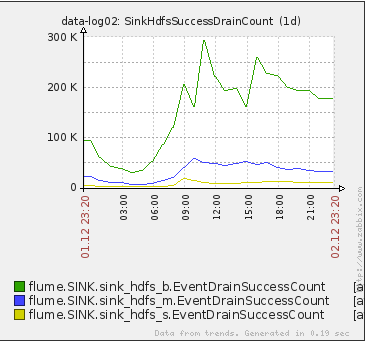
下面是Flume Collector的FileChannel中擁堵的events資料量截圖:
5.2 flume寫hfds狀態的監控 Flume寫入Hdfs會先生成tmp檔案,對於特別重要的日誌,我們會每15分鐘左右檢查一下各個Collector是否都產生了tmp檔案,對於沒有正常產生tmp檔案的Collector和日誌我們需要檢查是否有異常。這樣可以及時發現Flume和日誌的異常. 5.3 日誌大小異常監控 對於重要的日誌,我們會每個小時都監控日誌大小周同比是否有較大波動,並給予提醒,這個報警有效的發現了異常的日誌,且多次發現了應用方日誌傳送的異常,及時給予了對方反饋,幫助他們及早修復自身系統的異常。 通過上述的講解,我們可以看到,基於Flume的美團日誌收集系統已經是具備高可用性,高可靠性,可擴充套件等特性的分散式服務
a. 整個系統分為三層:Agent層,Collector層和Store層。其中Agent層每個機器部署一個程序,負責對單機的日誌收集工作;Collector層部署在中心伺服器上,負責接收Agent層傳送的日誌,並且將日誌根據路由規則寫到相應的Store層中;Store層負責提供永久或者臨時的日誌儲存服務,或者將日誌流導向其它伺服器。 b. Agent到Collector使用LoadBalance策略,將所有的日誌均衡地發到所有的Collector上,達到負載均衡的目標,同時並處理單個Collector失效的問題。 c. Collector層的目標主要有三個:SinkHdfs, SinkKafka和SinkBypass。分別提供離線的資料到Hdfs,和提供實時的日誌流到Kafka和Bypass。其中SinkHdfs又根據日誌量的大小分為SinkHdfs_b,SinkHdfs_m和SinkHdfs_s三個Sink,以提高寫入到Hdfs的效能,具體見後面介紹。 d. 對於Store來說,Hdfs負責永久地儲存所有日誌;Kafka儲存最新的7天日誌,並給Storm系統提供實時日誌流;Bypass負責給其它伺服器和應用提供實時日誌流。 下圖是美團的日誌收集系統的模組分解圖,詳解Agent, Collector和Bypass中的Source, Channel和Sink的關係。
a. 模組命名規則:所有的Source以src開頭,所有的Channel以ch開頭,所有的Sink以sink開頭; b. Channel統一使用美團開發的DualChannel,具體原因後面詳述;對於過濾掉的日誌使用NullChannel,具體原因後面詳述; c. 模組之間內部通訊統一使用Avro介面; 4 架構設計考慮 下面將從可用性,可靠性,可擴充套件性和相容性等方面,對上述的架構做細緻的解析。 4.1 可用性(availablity) 對日誌收集系統來說,可用性(availablity)指固定週期內系統無故障執行總時間。要想提高系統的可用性,就需要消除系統的單點,提高系統的冗餘度。下面來看看美團的日誌收集系統在可用性方面的考慮。 4.1.1 Agent死掉 Agent死掉分為兩種情況:機器宕機或者Agent程序死掉。 對於機器宕機的情況來說,由於產生日誌的程序也同樣會死掉,所以不會再產生新的日誌,不存在不提供服務的情況。 對於Agent程序死掉的情況來說,確實會降低系統的可用性。對此,我們有下面三種方式來提高系統的可用性。首先,所有的Agent在supervise的方式下啟動,如果程序死掉會被系統立即重啟,以提供服務。其次,對所有的Agent進行存活監控,發現Agent死掉立即報警。最後,對於非常重要的日誌,建議應用直接將日誌寫磁碟,Agent使用spooldir的方式獲得最新的日誌。 4.1.2 Collector死掉 由於中心伺服器提供的是對等的且無差別的服務,且Agent訪問Collector做了LoadBalance和重試機制。所以當某個Collector無法提供服務時,Agent的重試策略會將資料傳送到其它可用的Collector上面。所以整個服務不受影響。 4.1.3 Hdfs正常停機 我們在Collector的HdfsSink中提供了開關選項,可以控制Collector停止寫Hdfs,並且將所有的events快取到FileChannel的功能。 4.1.4 Hdfs異常停機或不可訪問 假如Hdfs異常停機或不可訪問,此時Collector無法寫Hdfs。由於我們使用DualChannel,Collector可以將所收到的events快取到FileChannel,儲存在磁碟上,繼續提供服務。當Hdfs恢復服務以後,再將FileChannel中快取的events再發送到Hdfs上。這種機制類似於Scribe,可以提供較好的容錯性。 4.1.5 Collector變慢或者Agent/Collector網路變慢 如果Collector處理速度變慢(比如機器load過高)或者Agent/Collector之間的網路變慢,可能導致Agent傳送到Collector的速度變慢。同樣的,對於此種情況,我們在Agent端使用DualChannel,Agent可以將收到的events快取到FileChannel,儲存在磁碟上,繼續提供服務。當Collector恢復服務以後,再將FileChannel中快取的events再發送給Collector。 4.1.6 Hdfs變慢 當Hadoop上的任務較多且有大量的讀寫操作時,Hdfs的讀寫資料往往變的很慢。由於每天,每週都有高峰使用期,所以這種情況非常普遍。 對於Hdfs變慢的問題,我們同樣使用DualChannel來解決。當Hdfs寫入較快時,所有的events只經過MemChannel傳遞資料,減少磁碟IO,獲得較高效能。當Hdfs寫入較慢時,所有的events只經過FileChannel傳遞資料,有一個較大的資料快取空間。 4.2 可靠性(reliability) 對日誌收集系統來說,可靠性(reliability)是指Flume在資料流的傳輸過程中,保證events的可靠傳遞。 對Flume來說,所有的events都被儲存在Agent的Channel中,然後被髮送到資料流中的下一個Agent或者最終的儲存服務中。那麼一個Agent的Channel中的events什麼時候被刪除呢?當且僅當它們被儲存到下一個Agent的Channel中或者被儲存到最終的儲存服務中。這就是Flume提供資料流中點到點的可靠性保證的最基本的單跳訊息傳遞語義。 那麼Flume是如何做到上述最基本的訊息傳遞語義呢? 首先,Agent間的事務交換。Flume使用事務的辦法來保證event的可靠傳遞。Source和Sink分別被封裝在事務中,這些事務由儲存event的儲存提供或者由Channel提供。這就保證了event在資料流的點對點傳輸中是可靠的。在多級資料流中,如下圖,上一級的Sink和下一級的Source都被包含在事務中,保證資料可靠地從一個Channel到另一個Channel轉移。
其次,資料流中 Channel的永續性。Flume中MemoryChannel是可能丟失資料的(當Agent死掉時),而FileChannel是永續性的,提供類似mysql的日誌機制,保證資料不丟失。 4.3 可擴充套件性(scalability) 對日誌收集系統來說,可擴充套件性(scalability)是指系統能夠線性擴充套件。當日志量增大時,系統能夠以簡單的增加機器來達到線性擴容的目的。 對於基於Flume的日誌收集系統來說,需要在設計的每一層,都可以做到線性擴充套件地提供服務。下面將對每一層的可擴充套件性做相應的說明。 4.3.1 Agent層 對於Agent這一層來說,每個機器部署一個Agent,可以水平擴充套件,不受限制。一個方面,Agent收集日誌的能力受限於機器的效能,正常情況下一個Agent可以為單機提供足夠服務。另一方面,如果機器比較多,可能受限於後端Collector提供的服務,但Agent到Collector是有Load Balance機制,使得Collector可以線性擴充套件提高能力。 4.3.2 Collector層 對於Collector這一層,Agent到Collector是有Load Balance機制,並且Collector提供無差別服務,所以可以線性擴充套件。其效能主要受限於Store層提供的能力。 4.3.3 Store層 對於Store這一層來說,Hdfs和Kafka都是分散式系統,可以做到線性擴充套件。Bypass屬於臨時的應用,只對應於某一類日誌,效能不是瓶頸。 4.4 Channel的選擇 Flume1.4.0中,其官方提供常用的MemoryChannel和FileChannel供大家選擇。其優劣如下:
- MemoryChannel: 所有的events被儲存在記憶體中。優點是高吞吐。缺點是容量有限並且Agent死掉時會丟失記憶體中的資料。
-
FileChannel: 所有的events被儲存在檔案中。優點是容量較大且死掉時資料可恢復。缺點是速度較慢。
-
DualChannel:基於 MemoryChannel和 FileChannel開發。當堆積在Channel中的events數小於閾值時,所有的events被儲存在MemoryChannel中,Sink從MemoryChannel中讀取資料; 當堆積在Channel中的events數大於閾值時, 所有的events被自動存放在FileChannel中,Sink從FileChannel中讀取資料。這樣當系統正常執行時,我們可以使用MemoryChannel的高吞吐特性;當系統有異常時,我們可以利用FileChannel的大快取的特性。
下面是Flume Collector的FileChannel中擁堵的events資料量截圖:
5.2 flume寫hfds狀態的監控 Flume寫入Hdfs會先生成tmp檔案,對於特別重要的日誌,我們會每15分鐘左右檢查一下各個Collector是否都產生了tmp檔案,對於沒有正常產生tmp檔案的Collector和日誌我們需要檢查是否有異常。這樣可以及時發現Flume和日誌的異常. 5.3 日誌大小異常監控 對於重要的日誌,我們會每個小時都監控日誌大小周同比是否有較大波動,並給予提醒,這個報警有效的發現了異常的日誌,且多次發現了應用方日誌傳送的異常,及時給予了對方反饋,幫助他們及早修復自身系統的異常。 通過上述的講解,我們可以看到,基於Flume的美團日誌收集系統已經是具備高可用性,高可靠性,可擴充套件等特性的分散式服務