
過擬合(定義、出現的原因4種、解決方案7種)
定義
定義:給定一個假設空間H,一個假設h屬於H,如果存在其他的假設h’屬於H,使得在訓練樣例上h的錯誤率比h’小,但在整個例項分佈上h’比h的錯誤率小,那麼就說假設h過度擬合訓練資料。 ———《Machine Learning》Tom M.Mitchell
出現過擬合的原因
1. 訓練集的數量級和模型的複雜度不匹配。訓練集的數量級要小於模型的複雜度;
2. 訓練集和測試集特徵分佈不一致;
3. 樣本里的噪音資料干擾過大,大到模型過分記住了噪音特徵,反而忽略了真實的輸入輸出間的關係;
4. 權值學習迭代次數足夠多(Overtraining),擬合了訓練資料中的噪聲和訓練樣例中沒有代表性的特徵。
解決方案
(simpler model structure、 data augmentation、 regularization、 dropout、early stopping、ensemble、重新清洗資料)
1. simpler model structure
調小模型複雜度,使其適合自己訓練集的數量級(縮小寬度和減小深度)
2. data augmentation
訓練集越多,過擬合的概率越小。在計算機視覺領域中,增廣的方式是對影象旋轉,縮放,剪下,新增噪聲等。
3. regularization
引數太多,會導致我們的模型複雜度上升,容易過擬合,也就是我們的訓練誤差會很小。 正則化是指通過引入額外新資訊來解決機器學習中過擬合問題的一種方法。這種額外資訊通常的形式是模型複雜性帶來的懲罰度。

a)L0範數與L1範數
L0範數是指向量中非0的元素的個數。如果我們用L0範數來規則化一個引數矩陣W的話,就是希望W的大部分元素都是0即讓引數W是稀疏的。
L1範數是指向量中各個元素絕對值之和,也叫“稀疏規則運算元”(Lasso regularization)。為什麼L1範數會使權值稀疏?有人可能會這樣給你回答“它是L0範數的最優凸近似”。實際上,還存在一個更美的回答:任何的規則化運算元,如果他在Wi=0的地方不可微,並且可以分解為一個“求和”的形式,那麼這個規則化運算元就可以實現稀疏。W的L1範數是絕對值,|w|在w=0處是不可微,
為什麼L0和L1都可以實現稀疏,但常用的為L1?
那麼引數稀疏有什麼好處呢?這裡扯兩點:
(1)特徵選擇(Feature Selection):
大家對稀疏規則化趨之若鶩的一個關鍵原因在於它能實現特徵的自動選擇。一般來說,xi的大部分元素(也就是特徵)都是和最終的輸出yi沒有關係或者不提供任何資訊的,在最小化目標函式的時候考慮xi這些額外的特徵,雖然可以獲得更小的訓練誤差,但在預測新的樣本時,這些沒用的資訊反而會被考慮,從而干擾了對正確yi的預測。稀疏規則化運算元的引入就是為了完成特徵自動選擇的光榮使命,它會學習地去掉這些沒有資訊的特徵,也就是把這些特徵對應的權重置為0。
(2)可解釋性(Interpretability):
另一個青睞於稀疏的理由是,模型更容易解釋。例如患某種病的概率是y,然後我們收集到的資料x是1000維的,也就是我們需要尋找這1000種因素到底是怎麼影響患上這種病的概率的。假設我們這個是個迴歸模型:y=w1*x1+w2*x2+…+w1000*x1000+b(當然了,為了讓y限定在[0,1]的範圍,一般還得加個Logistic函式)。通過學習,如果最後學習到的w*就只有很少的非零元素,例如只有5個非零的wi,那麼我們就有理由相信,這些對應的特徵在患病分析上面提供的資訊是巨大的,決策性的。也就是說,患不患這種病只和這5個因素有關,那醫生就好分析多了。但如果1000個wi都非0,醫生面對這1000種因素,累覺不愛。
b)L2範數
除了L1範數,還有一種更受寵幸的規則化範數是L2範數: ||W||2。它也不遜於L1範數,它有兩個美稱,在迴歸裡面,有人把有它的迴歸叫“嶺迴歸”(Ridge Regression),有人也叫它“權值衰減”(weight decay)。 weight decay還有一個好處,它使得目標函式變為凸函式,梯度下降法和L-BFGS都能收斂到全域性最優解。
L2範數是指向量各元素的平方和然後求平方根。我們讓L2範數的規則項||W||2最小,可以使得W的每個元素都很小,都接近於0,但與L1範數不同,它不會讓它等於0,而是接近於0。因為一般認為引數值小的模型比較簡單,能適應不同的資料集,也在一定程度上避免了過擬合現象。可以設想一下對於一個線性迴歸方程,若引數很大,那麼只要資料偏移一點點,就會對結果造成很大的影響;但如果引數足夠小,資料偏移得多一點也不會對結果造成什麼影響,專業一點的說法是『抗擾動能力強』。


4、 dropout
這個方法在神經網路裡面很常用。dropout方法是ImageNet中提出的一種方法,通俗一點講就是dropout方法在訓練的時候讓神經元以一定的概率不工作。具體看下圖:
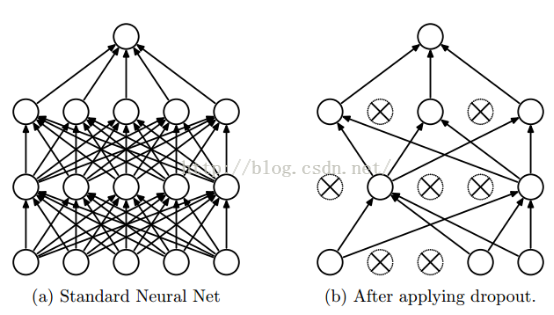
如上圖所示,左邊a圖是沒用用dropout方法的標準神經網路,右邊b圖是在訓練過程中使用了dropout方法的神經網路,即在訓練時候以一定的概率p來跳過一定的神經元。
5、 early stopping
對模型進行訓練的過程即是對模型的引數進行學習更新的過程,這個引數學習的過程往往會用到一些迭代方法,如梯度下降(Gradient descent)學習演算法。Early stopping便是一種迭代次數截斷的方法來防止過擬合的方法,即在模型對訓練資料集迭代收斂之前停止迭代來防止過擬合。
Early stopping方法的具體做法是,在每一個Epoch結束時(一個Epoch集為對所有的訓練資料的一輪遍歷)計算validation data的accuracy,當accuracy不再提高時,就停止訓練。這種做法很符合直觀感受,因為accurary都不再提高了,在繼續訓練也是無益的,只會提高訓練的時間。那麼該做法的一個重點便是怎樣才認為validation accurary不再提高了呢?並不是說validation accuracy一降下來便認為不再提高了,因為可能經過這個Epoch後,accuracy降低了,但是隨後的Epoch又讓accuracy又上去了,所以不能根據一兩次的連續降低就判斷不再提高。一般的做法是,在訓練的過程中,記錄到目前為止最好的validation accuracy,當連續10次Epoch(或者更多次)沒達到最佳accuracy時,則可以認為accuracy不再提高了。此時便可以停止迭代了(Early Stopping)。這種策略也稱為“No-improvement-in-n”,n即Epoch的次數,可以根據實際情況取,如10、20、30……
6、 ensemble
7、重新清洗資料
資料清洗從名字上也看的出就是把“髒”的“洗掉”,指發現並糾正資料檔案中可識別的錯誤的最後一道程式,包括檢查資料一致性,處理無效值和缺失值等。導致過擬合的一個原因也有可能是資料不純導致的,如果出現了過擬合就需要我們重新清洗資料。
相關推薦
過擬合(定義、出現的原因4種、解決方案7種)
定義定義:給定一個假設空間H,一個假設h屬於H,如果存在其他的假設h’屬於H,使得在訓練樣例上h的錯誤率比h’小,但在整個例項分佈上h’比h的錯誤率小,那麼就說假設h過度擬合訓練資料。 ———《Machine Learning》Tom M.Mitchell出現過擬合的原因1.
過擬合(原因、解決方案、原理)
(1)建模樣本抽取錯誤,包括(但不限於)樣本數量太少,抽樣方法錯誤,抽樣時沒有足夠正確考慮業務場景或業務特點,等等導致抽出的樣本資料不能有效足夠代表業務邏輯或業務場景; (2)樣本里的噪音資料干擾過大,大到模型過分記住了噪音特徵,反而忽略了真實的輸入輸出間的關係; (3)建模時的“邏輯假設”到了模型應用時
(轉)正則化為什麼能防止過擬合 正則化為什麼能防止過擬合(重點地方標紅了)
正則化為什麼能防止過擬合(重點地方標紅了) 正則化方法:防止過擬合,提高泛化能力 在訓練資料不夠多時,或者overtraining時,常常會導致overfitting(過擬合)。其直觀的表現如下圖所示,隨著訓練過程的進行,模型複雜度增加,在training data上的error漸漸減小
神經網路之過擬合(附程式碼)
摘要 監督機器學習問題無非就是“minimizeyour error while regularizing your parameters”,也就是在規則化引數的同時最小化誤差。最小化誤差是為了讓我們的模型擬合我們的訓練資料,而規則化引數是防止我們的模型過分擬合我們的訓練資料
機器學習中:過擬合(overfitting)和欠擬合(underfitting)
Underfitting is easy to check as long as you know what the cost function measures. The definition of the cost function in linear regression is half the me
卷積神經網路調參技巧(2)--過擬合(Dropout)
Dropout(丟棄) 首先需要講一下過擬合,訓練一個大型網路時,因為訓練資料有限,很容易出現過擬合。過擬合是指模型的泛化能力差,網路對訓練資料集的擬合能力很好,但是換了其他的資料集,擬合能力就變差了
14過擬合(Overfitting)
過擬合:我們通過訓練集訓練的模型對於訓練樣本的的擬合程度十分高,就會放大一些不必要的特徵,再對測試集進行測試時,就容易造成測試精度很低,也就是模型的泛化能力很弱,這就是過擬合。 那麼我們如何解決過擬合
如何解決過擬合(overfitting)問題?
什麼是過擬合? 為了得到一致假設而使假設變得過度嚴格稱為過擬合。過擬合的模型一般對訓練資料表現很好,而對測試資料表現很差。 如何解決過擬合問題? early stopping:可以設定一個迭代截斷的閾值,到了這個閾值迭代終止;也可以設定兩次迭代之間的accuracy提高
維度災難與過擬合(轉)
平面 效果好 hal 過程 而在 最小 進行 有趣 導致 一、介紹 本篇文章,我們將討論所謂的“維度災難”,並解釋在設計一個分類器時它為何如此重要。在下面幾節中我將對這個概念進行直觀的解釋,並通過一個由於維度災難導致的過擬合的例子來講解。 考慮這樣一個例子,我們有一些圖片,
AI - TensorFlow - 過擬合(Overfitting)
for 區分 技術分享 運用 圖片 environ top col tar 過擬合 過擬合(overfitting,過度學習,過度擬合): 過度準確地擬合了歷史數據(精確的區分了所有的訓練數據),而對新數據適應性較差,預測時會有很大誤差。 過擬合是機器學習中常見的問題
SVM支援向量機系列理論(六) SVM過擬合的原因和SVM模型選擇
6.1 SVM 過擬合的原因 實際我們應用的SVM模型都是核函式+軟間隔的支援向量機,那麼,有以下原因導致SVM過擬合: 選擇的核函式過於powerful,比如多項式核中的Q設定的次數過高 要求的間隔過大,即在軟間隔支援向量機中C的引數過大時,表示比較重視間隔,堅持要資
泛化能力、訓練集、測試集、K折交叉驗證、假設空間、欠擬合與過擬合、正則化(L1正則化、L2正則化)、超引數
泛化能力(generalization): 機器學習模型。在先前未觀測到的輸入資料上表現良好的能力叫做泛化能力(generalization)。 訓練集(training set)與訓練錯誤(training error): 訓練機器學習模型使用的資料集稱為訓練集(tr
什麼是過擬合 (Overfitting) 、解決方法、程式碼示例(tensorflow實現)
過於自負 在細說之前, 我們先用實際生活中的一個例子來比喻一下過擬合現象. 說白了, 就是機器學習模型於自信. 已經到了自負的階段了. 那自負的壞處, 大家也知道, 就是在自己的小圈子裡表現非凡, 不過在現實的大圈子裡卻往往處處碰壁. 所以在這個簡介裡, 我們把自負和過擬合畫上等號
機器學習問題中過擬合出現的原因及解決方案
如果一味的追求模型的預測能力,所選的模型複雜度就會過高,這種現象稱為過擬合。模型表現出來的就是訓練模型時誤差很小,但在測試的時候誤差很大。 一、產生的原因: 1.樣本資料問題 樣本資料太少 樣本抽樣不符合業務場景 樣本中的噪音資料影響 2.模型問題 模型複雜度高,引
神經網路中的過擬合的原因及解決方法、泛化能力、L2正則化
過擬合:訓練好的神經網路對訓練資料以及驗證資料擬合的很好,accuracy很高,loss很低,但是在測試資料上效果很差,即出現了過擬合現象。 過擬合產生的原因: (1)資料集有噪聲 (2)訓練資料不足 (3)訓練模型過度導致模型非常複雜 解決方法: (1)降低模型
欠擬合、過擬合、梯度爆炸、梯度消失等問題的原因與大概解決方法
1、欠擬合:是一種不能很好擬合數據的的現象。 導致結果:其會導致網路的訓練的準確度不高,不能很好的非線性擬合數據,進行分類。 造成原因:這種現象很可能是網路層數不夠多,不夠深,導致其非線性不夠好。從而對於少量樣本能進行很好的擬合,而較多樣本無法很好的擬合。其實,現
統計學習方法——模型的選擇與評估(過擬合、泛化能力)
參考書目及論文:《統計學習方法》——李航、A Tutorial on Support Vector Machine for Pattern Recognition 監督學習的目的是找到一個輸入輸出對映(模型),使得這個模型不僅對訓練資料有很好的擬合能力,對於未知資料,它也
出現過擬合與欠擬合的原因以及解決方案
非線性 訓練數據 機器學習算法 由於 www. 課程 判斷 自身 深度 在學習李宏毅機器學習的課程中,在第二課中遇到了兩個概念:過擬合(overfitting)和欠擬合(underfitting),老師對於這兩個概念產生的原因以及解決方案沒有提及太多,所以今天就讓我們一起學
機器學習(ML)七之模型選擇、欠擬合和過擬合
訓練誤差和泛化誤差 需要區分訓練誤差(training error)和泛化誤差(generalization error)。前者指模型在訓練資料集上表現出的誤差,後者指模型在任意一個測試資料樣本上表現出的誤差的期望,並常常通過測試資料集上的誤差來近似。計算訓練誤差和泛化誤差可以使用之前介紹過的損失函式,例如線
斯坦福大學公開課機器學習: advice for applying machine learning - evaluatin a phpothesis(怎麽評估學習算法得到的假設以及如何防止過擬合或欠擬合)
class 中一 技術分享 cnblogs 訓練數據 是否 多個 期望 部分 怎樣評價我們的學習算法得到的假設以及如何防止過擬合和欠擬合的問題。 當我們確定學習算法的參數時,我們考慮的是選擇參數來使訓練誤差最小化。有人認為,得到一個很小的訓練誤差一定是一件好事。但其實,僅