
維度災難與過擬合(轉)
一、介紹
本篇文章,我們將討論所謂的“維度災難”,並解釋在設計一個分類器時它為何如此重要。在下面幾節中我將對這個概念進行直觀的解釋,並通過一個由於維度災難導致的過擬合的例子來講解。
考慮這樣一個例子,我們有一些圖片,每張圖片描繪的是小貓或者小狗。我們試圖構建一個分類器來自動識別圖片中是貓還是狗。要做到這一點,我們首先需要考慮貓、狗的量化特征,這樣分類器算法才能利用這些特征對圖片進行分類。例如我們可以通過毛皮顏色特征對貓狗進行識別,即通過圖片的紅色程度、綠色程度、藍色程度不同,設計一個簡單的線性分類器:
紅、綠、藍三種顏色我們稱之為特征Features,但僅僅利用這三個特征,還不能得到一個完美的分類器。因此,我們可以增加更多的特征來描述圖片。例如計算圖片X和Y方向的平均邊緣或者梯度密度。現在總共有5個特征來構建我們的分類器了。
為了得到更好的分類效果,我們可以增加更多特征,例如顏色、紋理分布和統計信息等。也許我們能得到上百個特征,但是分類器的效果會變得更好嗎?答案有些令人沮喪:並不能!事實上,特征數量超過一定值的時候,分類器的效果反而下降。圖1顯示了這種變化趨勢,這就是“維度災難”。
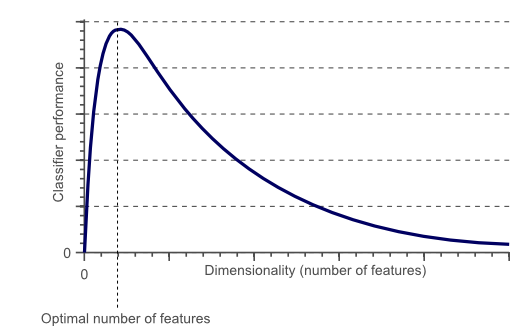
圖1. 隨著維度增加,分類器性能提升;維度增加到某值後,分類器性能下降
下一節我們將解釋為什麽產生這條曲線並討論如何避免這種情況發生。
二、維度災難與過擬合
在之前引入的貓和狗的例子中,我們假設有無窮多的貓和狗的圖片,然而,由於時間和處理能力限制,我們只得到10張圖片(貓的圖片或者狗的圖片)。我們的最終目標是基於這10張圖片構建一個分類器,能夠正確對10個樣本之外的無限多的圖片進行正確分類。
現在,讓我們使用一個簡單的線性分類器來嘗試得到一個好的分類器。如果只使用一個特征,例如使用圖片的平均紅色程度red。

圖2. 單個特征對訓練樣本分類效果不佳
圖2展示了只使用一個特征並不能得到一個最佳的分類結果。因此,我們覺得增加第二個特征:圖片的平均綠色程度green。

圖3. 增加第二個特征仍然不能線性分割,即不存在一條直線能夠將貓和狗完全分開。
最後,我們決定再增加第三個特征:圖片的平均藍色程度,得到了三維特征空間:

圖4. 增加第三個特征實現了線性可分,即存在一個平面完全將貓和狗分開來。
在三維特征空間,我們可以找到一個平面將貓和狗完全分開。這意味著三個特征的線性組合可以對10個訓練樣本進行最佳的分類。
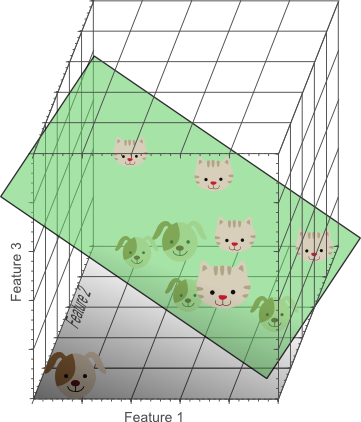
圖5. 特征越多,越有可能實現正確分類
以上的例子似乎證明了不斷增加特征數量,直到獲得最佳分類效果,是構建一個分類器的最好方法。但是我們認為情況並非如此。我們需要註意一個問題:隨著特征維度的增加,訓練樣本的在特征空間的密度是如何呈指數型下降的?
在1D空間中(圖2所示),10個訓練樣本完全覆蓋了1D特征空間,特征空間寬度為5。因此,1D下的樣本密度是10/5=2。而在2D空間中(圖3所示),同樣是10個訓練樣本,它構成的2D特征空間面積為5x5=25.因此,2D下的樣本密度是10/25=0.4。最後在3D空間中,10個訓練樣本構成的特征空間大小為5x5x5=125,因此,3D下的樣本密度為10/125=0.08。
如果我們繼續增加特征,整個特征空間維度增加,並變得越來越稀疏。由於稀疏性,我們更加容易找到一個超平面來實現分類。這是因為隨著特征數量變得無限大,訓練樣本在最佳超平面的錯誤側的可能性將會變得無限小。然而,如果我們將高維的分類結果投影到低維空間中,將會出現一個嚴重的問題:

圖6. 使用太多特征導致過擬合。分類器學習了過多樣本數據的異常特征(噪聲),而對新數據的泛化能力不好。
圖6展示了3D的分類結果投影到2D特征空間的樣子。樣本數據在3D是線性可分的,但是在2D卻並非如此。事實上,增加第三個維度來獲得最佳的線性分類效果,等同於在低維特征空間中使用非線性分類器。其結果是,分類器學習了訓練數據的噪聲和異常,而對樣本外的數據擬合效果並不理想,甚至很差。
這個概念稱為過擬合,是維度災難的一個直接後果。圖7展示了一個只用2個特征進行分類的線性分類器的二維平面圖。

圖7. 盡管訓練樣本不能全都分類正確,但這個分類器的泛化能力比圖5要好。
盡管圖7中的簡單的線性分類器比圖5中的非線性分類器的效果差,但是圖7的分類器的泛化能力強。這是因為分類器沒有把樣本數據的噪聲和異常也進行學習。另一方面說,使用更少的特征,維度災難就能避免,就不會出現對訓練樣本過擬合的現象。
圖8用不同的方式解釋上面的內容。假設我們只使用一個特征來訓練分類器,1D特征值的範圍限定在0到1之間,且每只貓和狗對應的特征值是唯一的。如果我們希望訓練樣本的特征值占特征值範圍的20%,那麽訓練樣本的數量就要達到總體樣本數的20%。現在,如果增加第二個特征,也就是從直線變為平面2D特征空間,這種情況下,如果要覆蓋特征值範圍的20%,那麽訓練樣本數量就要達到總體樣本數的45%(0.45*0.45=0.2)。而在3D空間中,如果要覆蓋特征值範圍的20%,就需要訓練樣本數量達到總體樣本數的58%(0.58*0.58*0.58=0.2)。
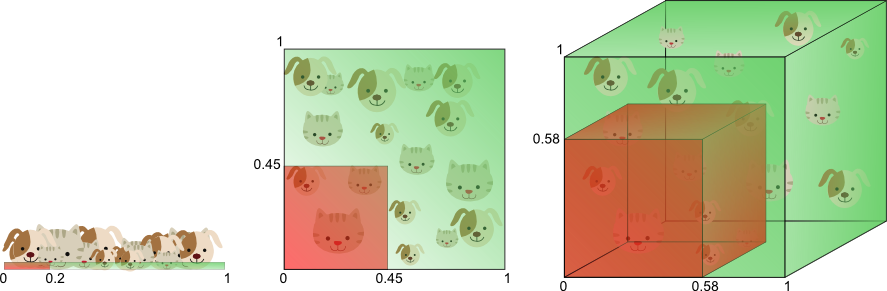
圖8. 覆蓋特征值範圍20%所需的訓練樣本數量隨著維度增加呈指數型增長
換句話說,如果可用的訓練樣本數量是固定的,那麽如果增加特征維度的話,過擬合就會發生。另一方面,如果增加特征維度,為了覆蓋同樣的特征值範圍、防止過擬合,那麽所需的訓練樣本數量就會成指數型增長。
在上面的例子中,我們展示了維度災難會引起訓練數據的稀疏化。使用的特征越多,數據就會變得越稀疏,從而導致分類器的分類效果就會越差。維度災難還會造成搜索空間的數據稀疏程度分布不均。事實上,圍繞原點的數據(在超立方體的中心)比在搜索空間的角落處的數據要稀疏得多。這可以用下面這個例子來解釋:
想象一個單位正方形代表了2D的特征空間,特征空間的平均值位於這個單位正方形的中心處,距中心處單位距離的所有點構成了正方形的內接圓。沒有落在單位圓的訓練樣本距離搜索空間的角落處比距離中心處更近,而這些樣本由於特征值差異很大(樣本分布在正方形角落處),所有難以分類。因此,如果大部分樣本落在單位內接圓裏,就會更容易分類。如圖9所示:

圖9. 落在單位圓之外的訓練樣本位於特征空間角落處,比位於特征空間中心處的樣本更難進行分類。
一個有趣的問題是當我們增加特征空間的維度時,隨著正方形(超立方體)的體積變化,圓形(超球體)的體積是如何變化的?無論維度如何變化,超立方體的體積都是1,圖10展示了隨著維度d的增加,半徑為0.5的超球面的體積是如何變化的:
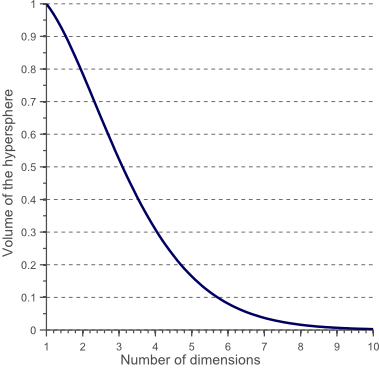
圖10. 維度d很大時,超球面的體積趨於零
這表明了隨著維度變得越來越大,超球體的體積趨於零,而超立方體的體積是不變的。這種令人驚訝的反直覺發現部分解釋了在分類中維度災難的問題:在高維空間中,大部分的訓練數據分布在定義為特征空間的超立方體的角落處。就像之前提到的,特征空間角落處的樣本比超球體內的樣本更加難以進行正確分類。圖11分別從2D、3D和可視化的8D超立方體(256個角落)的例子論證了這個結論。
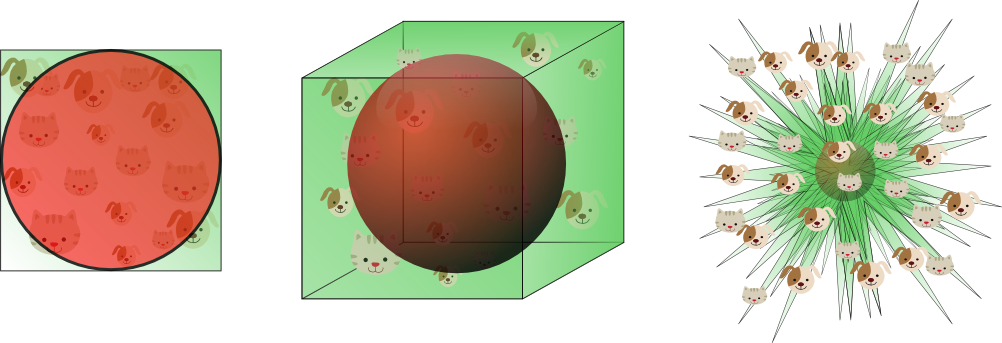
圖11. 隨著維度增加,大部分數量數據分布在角落處
對於8維的超球體,大約98%的數據集中在它256個角落處。其結果是,當特征空間的維度變得無限大時,從樣本點到質心的最大、最小歐氏距離的差值與其最小歐式距離的比值趨於零:
因此,距離測量在高維空間中逐漸變得無效。因為分類器是基於這些距離測量的(例如Euclidean距離、Mahalanobis距離、Manhattan距離),所以低維空間特征更少,分類更加容易。同樣地,在高維空間的高斯分布會變平坦且尾巴更長。
三、如何避免維度災難
圖1展示了隨著維度變得很大,分類器的性能是下降的。那麽問題是“很大”意味著什麽?過擬合如何避免?很遺憾,在分類問題中,沒有固定的規則來指定應該使用多少特征。事實上,這依賴於訓練樣本的數量、決策邊界的復雜性和使用的是哪個分類器。
如果理論上訓練樣本時無限多的,那麽維度災難不會發生,我們可以使用無限多的特征來獲得一個完美的分類器。訓練數據越少,使用的特征就要越少。如果N個訓練樣本覆蓋了1D特征空間的範圍,那麽在2D中,覆蓋同樣密度就需要N*N個數據,同樣在3D中,就需要N*N*N個數據。也就是說,隨著維度增加,訓練樣本的數量要求隨指數增加。
此外,那些非線性決策邊界的分類器(例如神經網絡、KNN分類器、決策樹等)分類效果好但是泛化能力差且容易發生過擬合。因此,當使用這些分類器的時候,維度不能太高。如果使用泛化能力好的分類器(例如貝葉斯分類器、線性分類器),可以使用更多的特征,因為分類器模型並不復雜。圖6展示了高維中的簡單分類器對應於地位空間的復雜分類器。
因此,過擬合只在高維空間中預測相對少的參數和低維空間中預測多參數這兩種情況下發生。舉個例子,高斯密度函數有兩類參數:均值和協方差矩陣。在3D空間中,協方差矩陣是3x3的對稱陣,總共有6個值(3個主對角線值和3個非對角線值),還有3個均值,加在一起,一共要求9個參數;而在1D,高斯密度函數只要求2個參數(1個均值,1個方差);在2D中,高斯密度函數要求5個參數(2個均值,3個協方差參數)。我們可以發現,隨著維度增加,參數數量呈平方式增長。
在之前的文章裏我們發現,如果參數數量增加,那麽參數的方差就會增大(前提是估計偏差和訓練樣本數量保持不變)。這就意味著,如果圍度增加,估計的參數方差增大,導致參數估計的質量下降。分類器的方差增大意味著出現過擬合。
另一個有趣的問題是:應該選擇哪些特征。如果有N個特征,我們應該如何選取M個特征?一種方法是在圖1曲線中找到性能最佳的位置。但是,由於很難對所有的特征組合進行訓練和測試,所以有一些其他辦法來找到最佳選擇。這些方法稱之為特征選擇算法,經常用啟發式方法(例如貪心算法、best-first方法等)來定位最佳的特征組合和數量。
還有一種方法是用M個特征替換N個特征,M個特征由原始特征組合而成。這種通過對原始特征進行優化的線性或非線性組合來減少問題維度的算法稱為特征提取。一個著名的維度降低技術是主成分分析法(PCA),它去除不相關維度,對N個原始特征進行線性組合。PCA算法試著找到低維的線性子空間,保持原始數據的最大方差。然而,數據方差最大不一定代表數據最顯著的分類信息。
最後,一項非常有用的被用來測試和避免過擬合的技術是交叉驗證。交叉驗證將原始訓練數據分成多個訓練樣本子集。在分類器進行訓練過程中,一個樣本子集被用來測試分類器的準確性,其他樣本用來進行參數估計。如果交叉驗證的結果與訓練樣本子集得到的結果不一致,那麽就表示發生了過擬合。如果訓練樣本有限,那麽可以使用k折法或者留一發進行交叉驗證。
四、結論
這篇文章我們討論了特征選擇、特征提取、交叉驗證的重要性,以及避免由維度災難導致的過擬合。通過一個過擬合的簡單例子,我們復習了維度災難的重要影響。
原文出處:
http://www.visiondummy.com/2014/04/curse-dimensionality-affect-classification/
轉自:https://blog.csdn.net/liudongdong19/article/details/80958503
維度災難與過擬合(轉)