
機器學習比賽—殺入Kaggle Top 1%
最近準備參加一個演算法比賽,想把自己所學的知識拿來用一用,在比賽初始自己沒一點思路,突然看到知乎上有一個大神寫了一篇博文,非常適合我這種剛入門的小白。
不知道你有沒有這樣的感受,在剛剛入門機器學習的時候,我們一般都是從MNIST、CIFAR-10這一類知名公開資料集開始快速上手,復現別人的結果,但總覺得過於簡單,給人的感覺太不真實。因為這些資料太“完美”了(乾淨的輸入,均衡的類別,分佈基本一致的測試集,還有大量現成的參考模型),要成為真正的資料科學家,光在這些資料集上跑模型卻是遠遠不夠的。而現實中你幾乎不可能遇到這樣的資料(現實資料往往有著殘缺的輸入,類別嚴重不均衡,分佈不一致甚至隨時變動的測試集,幾乎沒有可以參考的論文),這往往讓剛進入工作的同學手忙腳亂,無所適從。
Kaggle則提供了一個介於“完美”與真實之間的過渡,問題的定義基本良好,卻夾著或多或少的難點,一般沒有完全成熟的解決方案。在參賽過程中與論壇上的其他參賽者互動,能不斷地獲得啟發,受益良多。即使對於一些學有所成的高手乃至大牛,參加Kaggle也常常會獲得很多啟發,與來著世界各地的隊伍進行廝殺的刺激更讓人慾罷不能。更重要的是,Kaggle是業界普遍承認的競賽平臺,能從Kaggle上的一些高質量競賽獲取好名次,是對自己實力極好的證明,還能給自己的履歷添上光輝的一筆。如果能獲得金牌,殺入獎金池,那更是名利兼收,再好不過。
1 比賽篇
為了方便,我們先定義幾個名詞:
- Feature 特徵變數,也叫自變數,是樣本可以觀測到的特徵,通常是模型的輸入。
- Label 標籤,也叫目標變數,需要預測的變數,通常是模型的標籤或者輸出。
- Train Data 訓練資料,有標籤的資料,由舉辦方提供。
- Train Set 訓練集,從Train Data中分割得到的,用於訓練模型(常用於交叉驗證)。
- Valid Set 驗證集,從Train Data中分割得到的,為了能找出效果最佳的模型,使用各個模型對驗證集資料進行預測,並記錄模型準確率。選出效果最佳的模型所對應的引數,即用來調整模型引數(常用於交叉驗證)。
- Test Data 測試資料,通過訓練集和驗證集得出最優模型後,使用測試集進行模型預測。用來衡量該最優模型的效能和分類能力,標籤未知,是比賽用來評估得分的資料,由舉辦方提供。
1.1 分析題目
拿到賽題以後,第一步就是要破題,我們需要將問題轉化為相應的機器學習問題。其中,Kaggle最常見的機器學習問題型別有:
- 迴歸問題
- 分類問題(二分類、多分類、多標籤) 多分類只需從多個類別中預測一個類別,而多標籤則需要預測出多個類別。
比如Quora的比賽就是二分類問題,因為只需要判斷兩個問句的語義是否相似。
1.2 資料分析(Data Exploration)
所謂資料探勘,當然是要從資料中去挖掘我們想要的東西,我們需要通過人為地去分析資料,才可以發現數據中存在的問題和特徵。我們需要在觀察資料的過程中思考以下幾個問題:
- 資料應該怎麼清洗和處理才是合理的?
- 根據資料的型別可以挖掘怎樣的特徵?
- 資料中的哪些特徵會對標籤的預測有幫助?
1.2.1 統計分析
對於數值類變數(Numerical Variable),我們可以得到min,max,mean,meduim,std等統計量,用pandas可以方便地完成,結果如下:

從上圖中可以觀察Label是否均衡,如果不均衡則需要進行over sample少數類,或者down sample多數類。我們還可以統計Numerical Variable之間的相關係數,用pandas就可以輕鬆獲得相關係數矩陣:

觀察相關係數矩陣可以讓你找到高相關的特徵,以及特徵之間的冗餘度。而對於文字變數,可以統計詞頻(TF),TF-IDF,文字長度等等,更詳細的內容可以參考這裡。
1.2.2 視覺化
人是視覺動物,更容易接受圖形化的表示,因此可以將一些統計資訊通過圖表的形式展示出來,方便我們觀察和發現。比如用直方圖展示問句的頻數:

或者繪製相關係數矩陣:

常用的視覺化工具有 matplotlib 和 seaborn。當然,你也可以跳過這一步,因為視覺化不是解決問題的重點。
1.3 資料預處理(Data Preprocessing)
剛拿到手的資料會出現噪聲,缺失,髒亂等現象,我們需要對資料進行清洗與加工,從而方便進行後續的工作。針對不同型別的變數,會有不同的清洗和處理方法:
- 數值型變數(Numerical Variable),需要處理 離群點,缺失值,異常值 等情況,儘管動手去試,numerical填充max ,min,mean ,median std、離散化、Hash分桶,categorical 填充眾數,都拿去訓練 看看哪個效果好。
- 類別型變數(Categorical Variable),可以轉化為 one-hot 編碼。
- 文字資料 ,是較難處理的資料型別,文字中會有垃圾字元,錯別字(詞),數學公式,不統一單位和日期格式等。我們還需要處理標點符號,分詞,去停用詞,對於英文文字可能還要 詞性還原(lemmatize),抽取詞幹(stem)等等。
- 資料取樣,一般用 隨機取樣,和 分層取樣 的辦法。如果正樣本多於負樣本,且量都挺大,則可以採用下采樣(downsampling)。如果正樣本大於負樣本,但量不大,則可以採集更多的資料,或者上取樣 oversampling(比如影象識別中的映象和旋轉),以及修改損失函式/loss function的辦法來處理正負樣本不平衡的問題。
- 資料歸一化,可以提高梯度下降法求最優解速度,否則很難收斂或不收斂;還可提高模型的精度。資料如何進行歸一化?
1.4 特徵工程(Feature Engineering)
都說 特徵為王,特徵是決定效果最關鍵的一環。我們需要通過探索資料,利用人為先驗知識,從資料中總結出特徵。
1.4.1 特徵抽取(Feature Extraction)
我們應該儘可能多地抽取特徵,只要你認為某個特徵對解決問題有幫助,它就可以成為一個特徵。特徵抽取需要不斷迭代,是最為燒腦的環節,它會在整個比賽週期折磨你,但這是比賽取勝的關鍵,它值得你耗費大量的時間。
那問題來了,怎麼去發現特徵呢?光盯著資料集肯定是不行的。如果你是新手,可以先耗費一些時間在Forum上,看看別人是怎麼做Feature Extraction的,並且多思考。雖然 Feature Extraction 特別講究經驗,但其實還是有章可循的:
- 對於Numerical Variable,可以通過線性組合、多項式組合來發現新的Feature。
- 對於文字資料,有一些常規的Feature。比如,文字長度,詞頻,Embeddings,TF-IDF,LDA,LSI等,你甚至可以用深度學習提取文字特徵(隱藏層)。
- 如果你想對資料有更深入的瞭解,可以通過思考資料集的構造過程來發現一些 magic feature,這些特徵有可能會大大提升效果。在Quora這次比賽中,就有人公佈了一些 magic feature。
- 通過錯誤分析也可以發現新的特徵(見1.5.2小節)。
1.4.2 特徵選擇(Feature Selection)
在做特徵抽取的時候,我們是儘可能地抽取更多的Feature,但過多的 Feature 會造成 冗餘(部分特徵的相關度太高了,消耗計算效能),噪聲(部分特徵是對預測結果有負影響),容易過擬合等問題,因此我們需要進行 特徵篩選。特徵選擇可以加快模型的訓練速度,甚至還可以提升效果。
特徵選擇的方法多種多樣,最簡單的是相關度係數(Correlation coefficient),它主要是衡量兩個變數之間的線性關係,數值在[-1.0, 1.0]區間中。數值越是接近0,兩個變數越是線性不相關。但是數值為0,並不能說明兩個變數不相關,只是線性不相關而已;也可用 互資訊、距離相關度來計算。
我們通過一個例子來學習一下怎麼分析相關係數矩陣:

相關係數矩陣是一個對稱矩陣,所以只需要關注矩陣的左下角或者右上角。我們可以拆成兩點來看:
- Feature 和 Label 的相關度可以看作是該Feature的重要度,越接近1或-1就越好。
- Feature 和 Feature 之間的相關度要低,如果兩個Feature的相關度很高,就有可能存在冗餘。
除此之外,還可以訓練模型來篩選特徵,比如帶L1或L2懲罰項的Linear Model、Random Forest、GBDT等,它們都可以輸出特徵的重要度。在這次比賽中,我們對上述方法都進行了嘗試,將不同方法的 平均重要度 作為最終參考指標,篩選掉得分低的特徵。
如何進行特徵選擇,可點選這
1.5 建模(Modeling)
終於來到機器學習了,在這一章,我們需要開始煉丹了。
1.5.1 模型
機器學習模型有很多,建議均作嘗試,不僅可以測試效果,還可以學習各種模型的使用技巧。其實,幾乎每一種模型都有迴歸和分類兩種版本,常用模型有:
- KNN
- SVM
- Linear Model(帶懲罰項)
- ExtraTree
- RandomForest
- Gradient Boost Tree
- Neural Network
幸運的是,這些模型都已經有現成的工具(如scikit-learn、XGBoost、LightGBM等)可以使用,不用自己重複造輪子。但是我們應該要知道各個模型的原理,這樣在調參的時候才會遊刃有餘。當然,你也使用PyTorch/Tensorflow/Keras等深度學習工具來定製自己的Deep Learning模型,玩出自己的花樣。
1.5.2 錯誤分析
人無完人,每個模型不可能都是完美的,它總會犯一些錯誤。為了解某個模型在犯什麼錯誤,我們可以觀察被模型誤判的樣本,總結它們的共同特徵,我們就可以再訓練一個效果更好的模型。這種做法有點像後面 Ensemble 時提到的 Boosting,但是我們是人為地觀察錯誤樣本,而Boosting是交給了機器。通過 錯誤分析->發現新特徵->訓練新模型->錯誤分析,可以不斷地迭代出更好的效果,並且這種方式還可以培養我們對資料的嗅覺。
舉個例子,這次比賽中,我們在錯誤分析時發現,某些樣本的兩個問句表面上很相似,但是句子最後提到的地點不一樣,所以其實它們是語義不相似的,但我們的模型卻把它誤判為相似的。比如這個樣本:
- Question1: Which is the best digital marketing institution in banglore?
- Question2: Which is the best digital marketing institute in Pune?
為了讓模型可以處理這種樣本,我們將兩個問句的 最長公共子串(Longest Common Sequence)去掉,用剩餘部分訓練一個新的深度學習模型,相當於告訴模型看到這種情況的時候就不要判斷為相似的了。因此,在加入這個特徵後,我們的效果得到了一些提升。
1.5.3 調參
在訓練模型前,我們需要預設一些引數來確定模型結構(比如樹的深度)和優化過程(比如學習率),這種引數被稱為超參(Hyper-parameter),不同的引數會得到的模型效果也會不同。總是說調參就像是在“煉丹”,像一門“玄學”,但是根據經驗,還是可以找到一些章法的:
- 根據經驗,選出對模型效果 影響較大的超參。
- 按照經驗設定超參的搜尋空間,比如 學習率 的搜尋空間為[0.001,0.1]。
- 選擇搜尋演算法,比如Random Search、Grid Search和一些啟發式搜尋的方法。
- 驗證模型的泛化能力(詳見下一小節)。
1.5.4 模型驗證(Validation)
在Test Data的標籤未知的情況下,我們需要自己構造測試資料來驗證模型的泛化能力,因此把Train Data分割成Train Set和Valid Set兩部分,Train Set用於訓練,Valid Set用於驗證。
- 簡單分割
將Train Data按一定方法分成兩份,比如隨機取其中70%的資料作為Train Set,剩下30%作為Valid Set,每次都固定地用這兩份資料分別訓練模型和驗證模型。這種做法的缺點很明顯,它沒有用到整個訓練資料,所以驗證效果會有偏差。通常只會在訓練資料很多,模型訓練速度較慢的時候使用。
- 交叉驗證
交叉驗證是將整個訓練資料隨機分成K份,訓練K個模型,每次取其中的K-1份作為Train Set,留出1份作為Valid Set,因此也叫做K-fold。至於這個K,你想取多少都可以,但一般選在3~10之間。我們可以用 K 個模型得分的 mean 和 std,來評判模型得好壞(mean體現模型的能力,std體現模型是否容易過擬合),並且用K-fold的驗證結果通常會比較可靠。
如果資料出現 Label 不均衡情況,可以使用 Stratified K-fold,分層取樣,確保訓練集,測試集中各類別樣本的比例與原始資料集中相同),這樣得到的 Train Set 和 Test Set 的 Label 比例是大致相同。
1.6 模型整合(Ensemble)
曾經聽過一句話,”Feature為主,Ensemble為後”。Feature決定了模型效果的上限,而Ensemble就是讓你更接近這個上限。Ensemble講究“好而不同”,不同是指模型的學習到的側重面不一樣。舉個直觀的例子,比如數學考試,A的函式題做的比B好,B的幾何題做的比A好,那麼他們合作完成的分數通常比他們各自單獨完成的要高。
1.6.1 Bagging
Bagging是將多個模型(基學習器)的預測結果簡單地 加權平均 或者 投票。Bagging的好處在於可以 並行 地訓練基學習器,其中 Random Forest 就用到了Bagging的思想。舉個通俗的例子,如下圖:

老師出了兩道加法題,A同學和B同學答案的加權要比A和B各自回答的要精確。
Bagging通常是沒有一個明確的優化目標的,但是有一種叫Bagging Ensemble Selection的方法,它通過 貪婪演算法 來Bagging多個模型來優化目標值。在這次比賽中,我們也使用了這種方法。
1.6.2 Boosting
Boosting的思想有點像知錯能改,每訓練一個基學習器,是為了彌補上一個基學習器所犯的錯誤。其中著名的演算法有 AdaBoost,Gradient Boost。Gradient Boost Tree 就用到了這種思想。
我在1.2.3節(錯誤分析)中提到 Boosting,錯誤分析->抽取特徵->訓練模型->錯誤分析,這個過程就跟Boosting很相似。
1.6.3 Stacking
Stacking是用 新的模型(次學習器)去學習怎麼組合那些基學習器,它的思想源自於Stacked Generalization這篇論文。如果把Bagging看作是多個基分類器的線性組合,那麼Stacking就是多個基分類器的非線性組合。Stacking可以很靈活,它可以將學習器一層一層地堆砌起來,形成一個網狀的結構,如下圖:

舉個更直觀的例子,還是那兩道加法題:
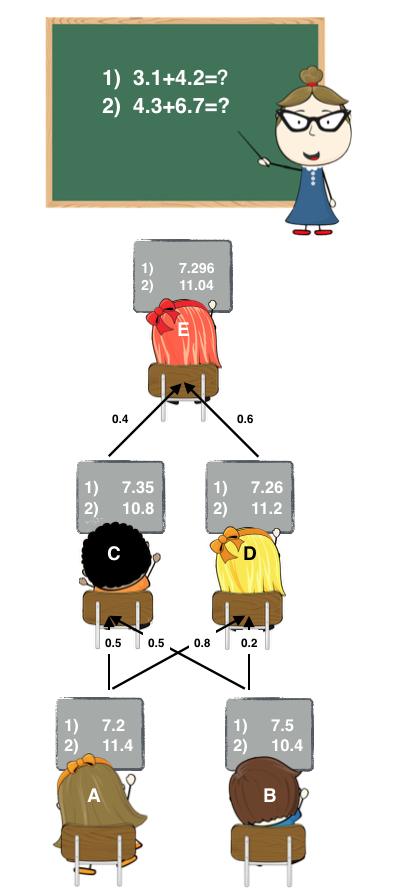

這裡A和B可以看作是基學習器,C、D、E都是次學習器。
- Stage1: A和B各自寫出了答案。
- Stage2: C和D偷看了A和B的答案,C認為A和B一樣聰明,D認為A比B聰明一點。他們各自結合了A和B的答案後,給出了自己的答案。
- Stage3: E偷看了C和D的答案,E認為D比C聰明,隨後E也給出自己的答案作為最終答案。
在實現 Stacking 時,要注意的一點是,避免標籤洩漏(Label Leak)。在訓練次學習器時,需要上一層學習器對 Train Data 的測試結果作為特徵,如果我們在Train Data上訓練,然後在Train Data上預測,就會造成Label Leak。為了避免Label Leak,需要對每個學習器使用K-fold,將K個模型對Valid Set的預測結果拼起來,作為下一層學習器的輸入。如下圖:

由圖可知,我們還需要對Test Data做預測。這裡有兩種選擇,可以將K個模型對Test Data的預測結果求平均,也可以用所有的Train Data重新訓練一個新模型來預測Test Data。所以在實現過程中,我們最好把每個學習器對Train Data和對Test Data的測試結果都儲存下來,方便訓練和預測。
對於Stacking還要注意一點,固定 K-fold 可以儘量避免Valid Set過擬合,也就是全域性共用一份K-fold,如果是團隊合作,組員之間也是共用一份K-fold。如果想具體瞭解 為什麼需要固定K-fold,請看這裡。
1.6.4 Blending
Blending 與 Stacking 很類似,它們的區別可以參考這裡
1.7 後處理
有些時候在確認沒有過擬合的情況下,驗證集上做校驗時效果挺好,但是將測試結果提交後的分數卻不如人意,這時候就有可能是訓練集的分佈與測試集的分佈不一樣而導致的。這時候為了提高LeaderBoard的分數,還需要對測試結果進行分佈調整。
比如這次比賽,訓練資料中正類的佔比為0.37,那麼預測結果中正類的比例也在0.37左右,然後Kernel上有人通過測試知道了測試資料中正類的佔比為0.165,所以我們也對預測結果進行了調整,得到了更好的分數。具體可以看這裡。
2 經驗篇
2.1 我們的方案(33th)
深度學習具有很好的模型擬合能力,使用深度學習可以較快得獲取一個不錯的Baseline,對這個問題整體的難度有一個初始的認識。雖然使用深度學習可以免去繁瑣的手工特徵,但是它也有能力上限,所以提取傳統手工特徵還是很有必要的。我們嘗試Forum上別人提供的方法,也嘗試自己思考去抽取特徵。總結一下,我們抽取的手工特徵可以分為以下4種:
- Text Mining Feature,比如 句子長度;兩個句子的 文字相似度,如 N-gram的編輯距離,Jaccard距離等;兩個句子共同的名詞,動詞,疑問詞等。
- Embedding Feature,預訓練好的 詞向量 相加求出 句子向量,然後求兩個句子向量的距離,比如 餘弦相似度、歐式距離等等。
- Vector Space Feature,用 TF-IDF矩陣 來表示句子,求相似度。
- Magic Feature,是Forum上一些選手通過思考資料集構造過程而發現的Feature,這種 Feature 往往與 Label 有強相關性,可以大大提高預測效果。
- 我們的系統整體上使用了Stacking的框架,如下圖:

- Stage1: 將兩個問句與Magic Feature輸入Deep Learning中,將其輸出作為下一層的特徵(這裡的Deep Learning相當於特徵抽取器)。我們一共訓練了幾十個Deep Learning Model。
- Stage2: 將 Deep Learning特徵 與 手工抽取的幾百個傳統特徵 拼接在一起,作為輸入。在這一層,我們訓練各種模型,有成百上千個(通過改變引數麼得到不同種類模型,用hyperopt的預設策略來搜尋引數空間,將中間結果全保留下來)。
- Stage3: 上一層的輸出進行Ensemble Selection。
比賽中發現的一些深度學習的侷限:
通過對深度學習產生的結果進行錯誤分析,並且參考論壇上別人的想法,我們發現深度學習沒辦法學到的特徵大概可以分為兩類:
- 對於一些資料的Pattern,在 Train Data 中出現的頻數不足以讓深度學習學到對應的特徵,所以我們需要通過手工提取這些特徵。
- 由於 Deep Learning 對樣本做了獨立同分布假設(iid),一般只能學習到每個樣本的特徵,而學習到資料的全域性特徵,比如 TF-IDF 這一類需要統計全域性詞頻才能獲取的特徵,因此也需要手工提取這些特徵。
傳統的機器學習模型和深度學習模型之間也存在表達形式上的不同。雖然傳統模型的表現未必比深度學習好,但它們學到的Pattern可能不同,通過Ensemble來取長補短,也能帶來效能上的提升。因此,同時使用傳統模型也是很有必要的。
2.2 第一名的解決方案
比賽結束不久,第一名也放出了他們的解決方案,我們來看看他們的做法。他們的特徵總結為三個類別:
- Embedding Feature
- Text Mining Feature
- Structural Feature(他們自己挖掘的 Magic Feature)
並且他們也使用了 Stacking 的框架,並且使用 固定的k-fold:
- Stage1: 使用了 Deep Learning,XGBoost,LightGBM,ExtraTree,Random Forest,KNN等300個模型。
- Stage2: 用了 手工特徵 和 第一層的預測 和 深度學習模型的隱藏層,並且訓練了150個模型。
- Stage3: 使用了分別是帶有 L1 和 L2 的兩種線性模型。
- Stage4: 將第三層的結果 加權平均。
我們模型存在不足:
- 對比以後發現我們沒有做 LDA、LSI 等特徵
- N-gram 的粒度沒有那麼細(他們用了8-gram),還有他們對 Magic Feature的挖掘更加深入。
- 還有一點是他們的 Deep Learning 模型設計更加合理,他們將篩選出來的 手工特徵 也輸入到深度學習模型當中,我覺得這也是他們取得好效果的關鍵。因為顯式地將手工特徵輸入給深度學習模型,相當於告訴“它你不用再學這些特徵了,你去學其他的特徵吧”,這樣模型就能學到更多的語義資訊。所以,我們跟他們的差距還是存在的。
3. 工具篇
工欲善其事,必先利其器。
Kaggle 的上常工具除了大家耳熟能詳的XGBoost之外, 這裡要著重推薦的是一款由微軟推出的LightGBM,這次比賽中我們就用到了。LightGBM的用法與XGBoost相似,兩者使用的區別是XGBoost調整的一個重要引數是樹的高度,而LightGBM調整的則是葉子的數目。與XGBoost 相比, 在模型訓練時速度快, 單模型的效果也略勝一籌。
調參也是一項重要工作,調參的工具主要是Hyperopt,它是一個使用搜索演算法來優化目標的通用框架,目前實現了Random Search和Tree of Parzen Estimators (TPE)兩個演算法。
對於 Stacking,Kaggle 的一位名為Μαριος Μιχαηλιδης的GrandMaster使用Java開發了一款集成了各種機器學習演算法的工具包StackNet,據說在使用了它以後你的效果一定會比原來有所提升,值得一試。
以下總結了一些常用的工具:
- Numpy | 必用的科學計算基礎包,底層由C實現,計算速度快。
- Pandas | 提供了高效能、易用的資料結構及資料分析工具。
- NLTK | 自然語言工具包,集成了很多自然語言相關的演算法和資源。
- Stanford CoreNLP | Stanford的自然語言工具包,可以通過NLTK呼叫。
- Gensim | 主題模型工具包,可用於訓練詞向量,讀取預訓練好的詞向量。
- scikit-learn | 機器學習Python包 ,包含了大部分的機器學習演算法。
- XGBoost/LightGBM | Gradient Boosting 演算法的兩種實現框架。
- StackNet | 準備好特徵之後,可以直接使用的Stacking工具包。
- Hyperopt | 通用的優化框架,可用於調參。
4. 總結與建議
- 在參加某個比賽前,要先衡量自己的機器資源能否足夠支撐你完成比賽。比如一個有幾萬張影象的比賽,而你的視訊記憶體只有2G,那很明顯你是不適合參加這個比賽的。當你選擇了一個比賽後,可以先“熱熱身”,稍微熟悉一下資料,粗略地跑出一些簡單的模型,看看自己在榜上的排名,然後再去慢慢迭代。
- Kaggle有許多大牛分享Kernel, 有許多Kernel有對於資料精闢的分析,以及一些baseline 模型, 對於初學者來說是很好的入門資料。在打比賽的過程中可以學習別人的分析方法,有利於培養自己資料嗅覺。甚至一些Kernel會給出一些data leak,會對於比賽提高排名有極大的幫助。
- 其次是Kaggle已經舉辦了很多比賽, 有些比賽有類似之處, 比如這次的Quora比賽就與之前的Home Depot Product Search Relevance 有相似之處,而之前的比賽前幾名已經放出了比賽的 idea 甚至 程式碼,這些都可以借鑑。
- 另外,要足夠地重視 Ensemble,這次我們組的最終方案實現了paper " Ensemble Selection from Libraries of Models" 的想法,所以有些比賽可能還需要讀一些paper,尤其對於深度學習相關的比賽,最新paper,最新模型的作用就舉足輕重了。
- 而且,將比賽程式碼的流程自動化,是提高比賽效率的一個關鍵,但是往往初學者並不能很好地實現自己的自動化系統。我的建議是初學者不要急於構建自動化系統,當你基本完成整個比賽流程後,自然而然地就會在腦海中形成一個框架,這時候再去構建你的自動化系統會更加容易。
- 最後,也是最重要的因素之一就是時間的投入,對於這次比賽, 我們投入了差不多三個多月,涉及到了對於各種能夠想到的方案的嘗試。尤其最後一個月,基本上每天除了睡覺之外的時間都在做比賽。所以要想在比賽中拿到好名次,時間的投入必不可少。另外對於國外一些介紹 kaggle比賽的部落格(比如官方部落格)也需要了解學習,至少可以少走彎路,本文的結尾列出了一些參考文獻,都值得細細研讀。
- 最後的最後,請做好心理準備,這是一場持久戰。因為比賽會給你帶來壓力,也許過了一晚,你的排名就會一落千丈。還有可能造成出現失落感,焦慮感,甚至失眠等症狀。但請你相信,它會給你帶來意想不到的驚喜,認真去做,你會覺得這些都是值得的。
解答
1. 請問在Stacking中,你們如何得知可以這樣組合? 以及如何驗證其效果跟正確度呢?
對於這個問題我們第一時間想到的是用deep learning,然後再抽手工特徵,這就組成了stage1,在stage2的時候想要發揮stack的能力當然是要上非線性模型,然後在進入stage3,而stack層數越深,所用的模型需要更簡單,不然很容易過擬合,因此用了bagging ensemble selection,當然你也可以像第一名的做法,去訓練帶懲罰項的線性模型。至於magic feature為什麼要放在deeplearning的輸入,那是因為我們發現deep learning會容易過擬合到某些特徵,加入magic feature可以顯式地告訴它“你已經有這些特徵了,你可以去挖掘其他的語義特徵”,其實你甚至可以把所有的 手工特徵 也加入deeplearning的輸入,這樣效果可能會更好,第一名就是這麼做的。
如何驗證stacking的效果,很簡單啊,用那份固定的kfold做交叉驗證。但是要注意,stacking有過擬合到 valid set 的風險,所以最好的評判當然是leaderborad啦。
2. stage2中的非線性模型,是任何的非線性模型皆可嗎? 還是需要數學驗證呢?
使用 Ensemble 的時候祕訣就是多嘗試,不能吊死在一棵樹上,如果你認為xgboost是裡面表現最好的,不需要嘗試其他模型了,那就太可惜了。我們不能保證一種模型一定能夠學習到所有的方面,所以需要去嘗試其他模型,儘量讓學出來的模型好而不同,這樣可以讓各種模型發揮自己的長處。所以,不僅僅是非線性模型可以,就算是線性模型也可以,當然我們還要考慮時間、資源等因素進行一些取捨。
如果我們追求的只是實用性和準確性,只要實驗的效果出色即可,如果要嚴謹地用數學證明再去使用,說不定等你證明完比賽已經結束了。
每次學習感覺都醍醐灌頂,在此感謝知乎大神分享
參考文獻:
相關推薦
機器學習比賽—殺入Kaggle Top 1%
最近準備參加一個演算法比賽,想把自己所學的知識拿來用一用,在比賽初始自己沒一點思路,突然看到知乎上有一個大神寫了一篇博文,非常適合我這種剛入門的小白。 不知道你有沒有這樣的感受,在剛剛入門機器學習的時候,我們一般都是從MNIST、CIFAR-10這一類知名公開資料集開始
機器學習-常見問題積累【1】
屬性。 積累 兩種 所在 哪些 異常 缺失值 問題 推導 1、python和R在做數據分析時各有自己得擅長得領域,如python做時域分析得難度就遠遠比R大,因為R有非常成熟得Package! 2、數據處理:如何處理缺失數據?各種處理方法得的利弊? 3、數據處理:如何將類別
從零開始機器學習比賽經驗(bird分享)
競爭力 aca 新的 ast 成績 ats span boosting https 視頻地址:https://pan.baidu.com/s/1b25yNG 機器學習比賽入門條件 1.過的去的code能力:Leetcode平臺 leetcode平臺可以幫助我們提高基本的算法
機器學習 周誌華 第1章習題
空間 ont 概念 ron 裏的 strong 機器學習 排列組合 可能 習題1.1 做這道題要弄青版本空間和假設空間的概念 我的理解是假設空間就是所有屬性值的可能組合到一起,這道題就是 3 * 3 * 3 + 1 = 28種 假設空間書上給的定義是:可能有多個
HIT機器學習期末復習(1)——機器學習簡介及決策樹
決策樹 開始 矩陣 improve 節點 policy heat red program 劉楊的機器學習終於上完了惹,下周就要考試了,趕緊復習ing...... 趁機做個總結,就當是復習了惹...... 機器學習簡介 1、什麽是機器學習 簡單來說,就是一個三元組<P
[吳恩達機器學習筆記]16推薦系統1-2基於內容的推薦系統
16.推薦系統 Recommender System 覺得有用的話,歡迎一起討論相互學習~Follow Me 16.1 問題形式化Problem Formulation 推薦系統的改善
機器學習中的評價指標--1[F,P,R]
機器學習中的評價指標 關於這一部分,我將在遇到的時候,進行簡要的說明和介紹,之講解最重點的部分,其它的可以查閱相關文獻和博主的文章。 1.關於 P、R 值 這應該是機器學習中最常用的兩個統計量了,我們要計算它,無非就要計算混淆矩陣,最簡化的版本是下面的4項版本
【機器學習系列文章】第1部分:為什麼機器學習很重要 ?
目錄 路線圖 關於作者 簡單,簡單的解釋,附有數學,程式碼和現實世界的例子。 這個系列是一本完整的電子書!在這裡下載。免費下載,貢獻讚賞(paypal.me/ml4h) 路線圖 第1部分:為什麼機器學習很重要。人工智慧和機器學習的大
李巨集毅機器學習PTT的理解(1)深度學習的介紹
深度學習的介紹 機器學習就像是尋找一個合適的函式,我們輸入資料就可以得到想要的結果,比如: 在語音識別中,我們輸入一段語音,函式的輸出值就是識別的結果;在影象識別中,輸入一張照片,函式可以告訴我們分類
吳裕雄 python 機器學習-KNN算法(1)
files action ets %s set digits size ret src import numpy as np import operator as op from os import listdir def classify0(inX, dataSet,
機器學習演算法 - 時間序列系1 -時序模式概念
時序模式 1 時間序列演算法 2 時間序列的預處理 2.1 平穩性檢驗 2.2 純隨機性檢驗 3 平穩時間序列分析 3.1 AR模型 3.2 MA模型 3.3 ARMA模型 3.4 平穩
【吳恩達機器學習筆記】week3:1/2邏輯迴歸
第三週 六、邏輯迴歸(Logistic Regression) 這裡首先區分一下線性迴歸和邏輯迴歸,線性迴歸就是擬合,邏輯迴歸是分類。 6.2 假說表式(Hypothesis Representation) 下面一個部分主要講的是假設函式h(x)在分類問題中輸出只能是0/
今天開始學模式識別與機器學習(PRML),章節5.1,Neural Networks神經網路-前向網路。
今天開始學模式識別與機器學習Pattern Recognition and Machine Learning (PRML),章節5.1,Neural Networks神經網路-前向網路。 話說上一次寫這個筆記是13年的事情了···那時候忙著實習,找工作,畢業什麼的就沒寫下去
【機器學習】加州理工學院公開課——機器學習與資料探勘 1.學習問題
一、概念形式化 輸入:x 輸出:y 目標函式:F:x → y 資料:(x1, y1), (x2, y2), …, (xN, yN) 假設函式:g:x → y 假設集:H={h}, G∈H (假設集有助於理解是否用這個演算法及用這個演
《機器學習實戰》——讀書筆記1
前言 在大學裡,最好的方面不是你研修的課程或從事的研究,而是一些外圍活動:與人會面、參加研討會、加入組織、旁聽課程,以及學習未知的知識。 一個機構會僱傭一些理論家(思考者)以及一些做實際工作的人(執行者)。前者可能會將大部分時間花在學術工作上,他們的日常工作就是基於論文產
機器學習實戰-基本演算法總結1
機器學習基本演算法總結 ☞監督學習——分類 程式碼在這,基於python3(原書程式碼是python2) 這裡只是一個總結,原書已經講解很清楚了,不清楚的直接看程式碼,或者李航的統計學習方法也有公式推導。 目錄1 =======
Stanford機器學習課程(Andrew Ng) Week 1 Parameter Learning --- 線性迴歸中的梯度下降法
本節將梯度下降與代價函式結合,並擬合到線性迴歸的函式中 這是我們上兩節課得到的函式,包括: 梯度下降的公式 用於擬合的線性假設和h(x) 平方誤差代價函式 J
Stanford機器學習課程(Andrew Ng) Week 1 Model and Cost Function --- 第二節 Cost Function
Cost Function 在學習線性迴歸之前,我們有必要補充代價函式的知識,來幫助我們弄清楚如何把最有可能的直線和我們的資料相擬合。 還是上節課的資料集,而假設函式也是這樣的一個最基本的線性函式形式 我們把θi稱為模型引數,而且
機器學習——SVM演算法原理(1)
(1)線性可分支援向量機與硬間隔最大化 考慮一個二分類問題,假設輸入空間與特徵空間為兩個不同的空間,輸入空間為歐式空間或離散集合,特徵空間為歐式空間或希伯特空間。線性支援向量機假設這兩個空間的元素一一
Python機器學習實戰與kaggle實戰
https://mlnote.wordpress.com/2015/12/16/python%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0%E5%AE%9E%E8%B7%B5%E4%B8%8Ekaggle%E5%AE%9E%E6%88%98-machine-learning-for