
python爬蟲之音樂下載
使用爬蟲實現音樂下載
需要用到以下幾點內容
- requests請求
- 檔案操作
- 一點點正則表示式
首先,分析我們要爬取的網站,這裡用到的是 好聽輕音樂網,
- 第一步,選擇任意一首歌點選加號,新增到列表。
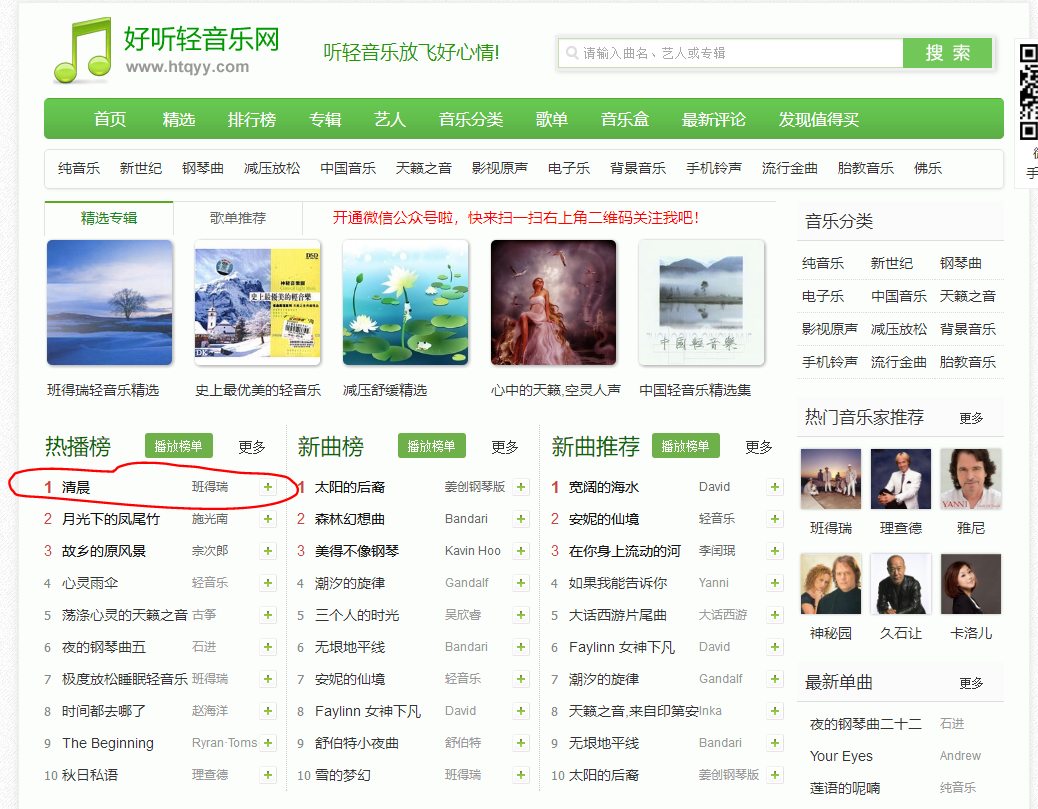
2.第二步,多新增幾首,開啟開發者工具,播放下一首,會發現,network中多了一個5的資源包
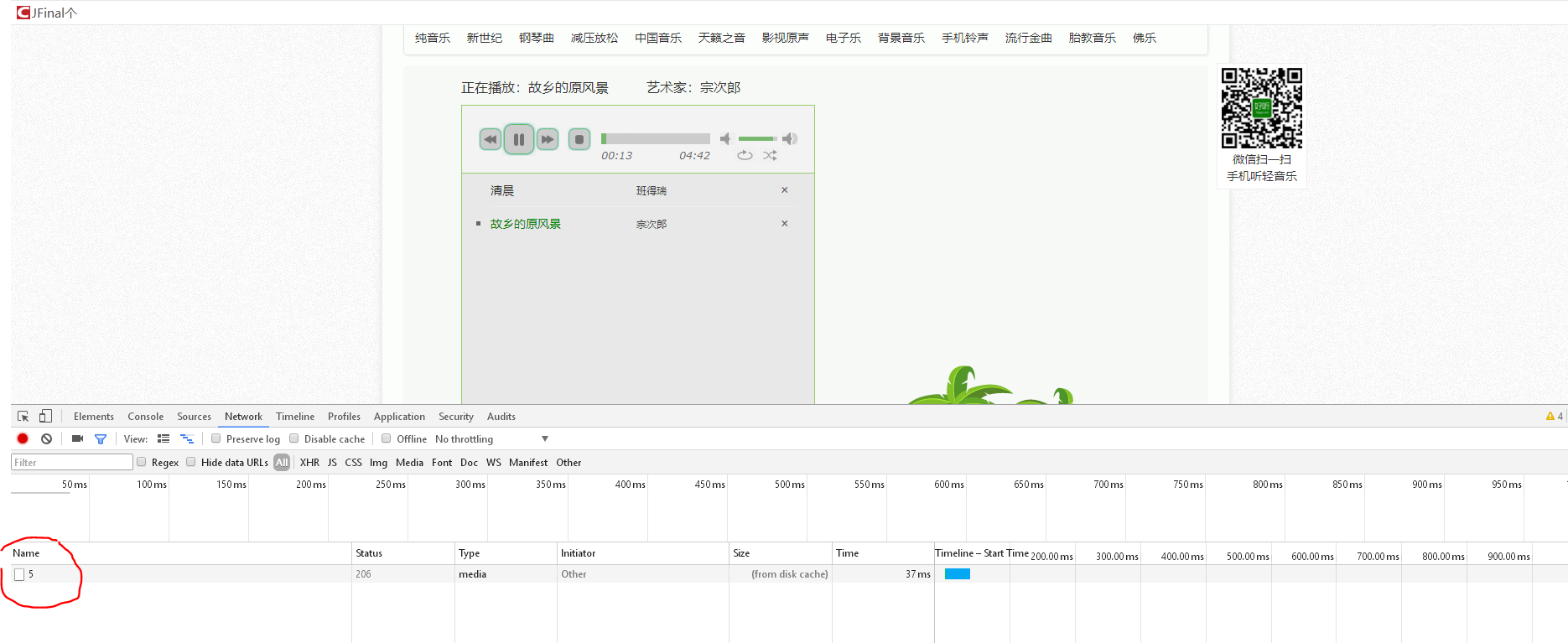
3. 滑鼠右鍵點選這個資源包,copy->copy link dress, 在新視窗中開啟,發現這個就是那個音樂。
我這得到的是這個url地址,http://f2.htqyy.com/play7/55/mp3/5, 再切換另一首歌曲,得到http://f2.htqyy.com/play7/261/mp3/5。發現規律沒有,http://f2.htqyy.com/play7/{ }
4.在首頁,點選熱播榜更多(這裡舉例)

發現這裡有很多很多頁,如果想把這幾頁都下載下來怎麼辦,開啟開發者工具,點選第二頁,發現network裡多了一個資源包
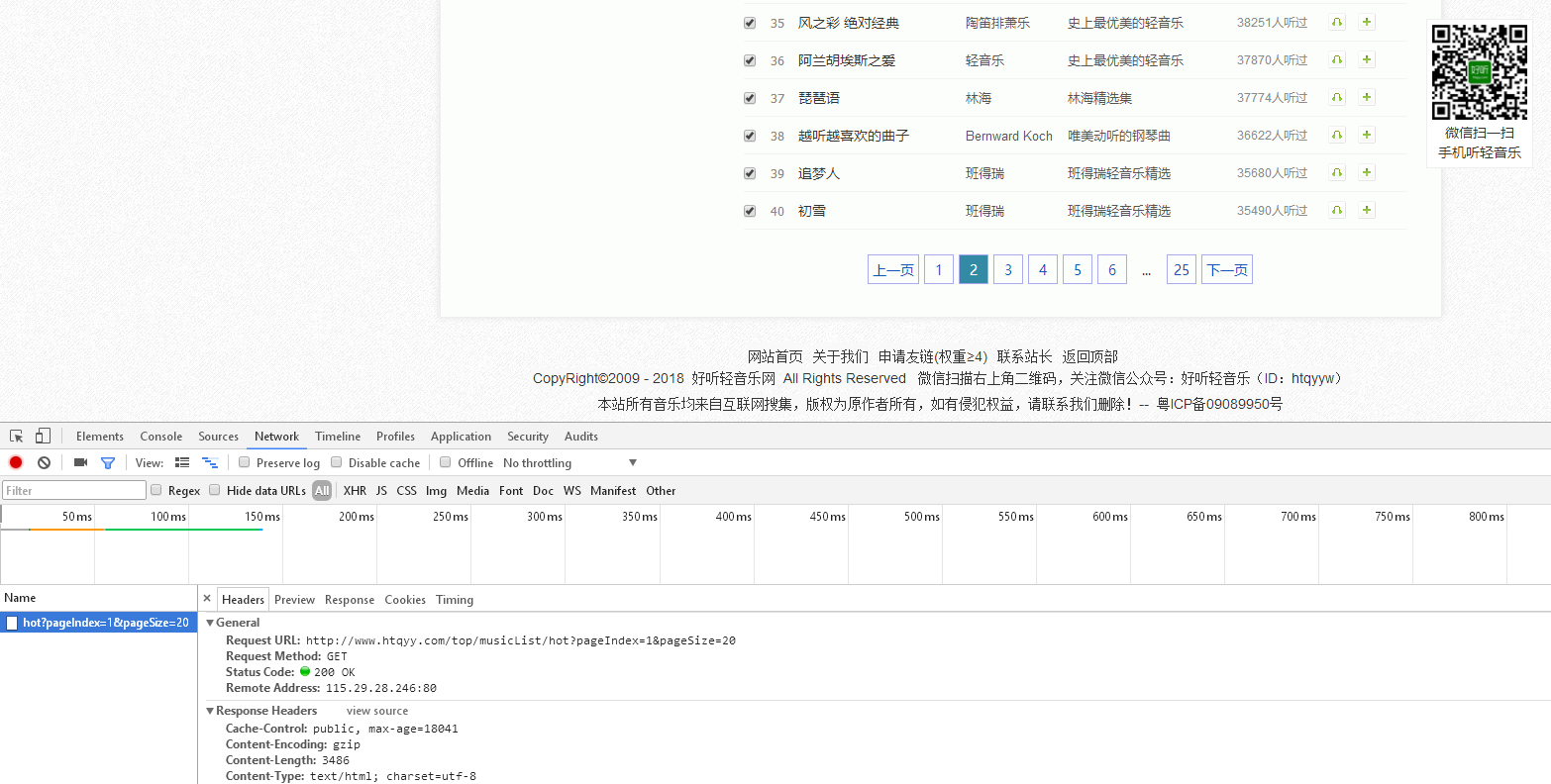
滑鼠右鍵點選這個資源包,copy->copy link dress, 在新視窗中開啟,點選紅色圈中的部分,然後點選歌名,可以看到 每首歌對應的數字 sid=‘4’例如水邊的阿狄麗娜對應的是http://f2.htqyy.com/play7/4/mp3/5。得到了每首歌的url。

5. 得到每一頁的url ,開啟第二頁的url為
http://www.htqyy.com/top/musicList/hot?pageIndex=1&pageSize=20
開啟第一頁的url為,
http://www.htqyy.com/top/musicList/hot?pageIndex=0&pageSize=20
得到通式:http://www.htqyy.com/top/musicList/hot?pageIndex={ }&pageSize=20
黑色部分為頁碼從0開始
通過以上分析,得知如果想下載音樂的話必須先找到其對應的url,然後再進行二進位制檔案的寫操作
程式碼如下:
有什莫疑問,咱們可以一起探討,敬請留言import re # python 的正則庫 import requests # python 的requests庫 songId = [] # 用來儲存每首歌對應的數字 songName = [] # 用來儲存每首歌的名字 # 這裡先下載5頁的歌曲 for n in range(0, 5): # 字串的格式化 n 代替 {} url = 'http://www.htqyy.com/top/musicList/hot?pageIndex={}&pageSize=20'.format(n) print(url, end='\n') # 模擬瀏覽器請求,拿到html程式碼 html = requests.get(url) # 用正則表示式捕獲 數字, ()內為捕獲的內容 .*? 為任何內容 resultId = re.findall('sid="(.*?)">', html.text) # 用正則表示式捕獲 歌名 resultName = re.findall('<a href=".*?" target="play" title="(.*?)" sid=".*?">', html.text) # 存進陣列 songId.extend(resultId) songName.extend(resultName) print(songId) print(songName) for m in range(0, len(songId)): # 字串的格式化 m 代替 {} songUrl = 'http://f2.htqyy.com/play7/{}/mp3/5'.format(songId[m]) print(songUrl, end='\n') print('正在下載第{}首。。。'.format(m+1)) # 得到返回資源的內容 response = requests.get(songUrl).content # 以二進位制的形式寫入檔案中 f = open('E:\\music\\{}.mp3'.format(songName[m]), 'wb') f.write(response) f.close()
