
Hadoop之MapReduce

摘要:MapReduce是Hadoop的又一核心模組,從MapReduce是什麼,MapReduce能做什麼以及MapReduce的工作機制三方面認識MapReduce。
關鍵詞:Hadoop MapReduce 分散式處理
面對大資料,大資料的儲存和處理,就好比一個人的左右手,顯得尤為重要。Hadoop比較適合解決大資料問題,很大程度上依賴其大資料儲存系統,即HDFS和大資料處理系統,即MapReduce。關於HDFS,可以參閱作者寫的《Hadoop之HDFS》文章。而對於MapReduce,我們從如下三個問題來認識MapReduce。
問題一:MapReduce是什麼?
問題二:MapReduce能做什麼?
問題三:MapReduce工作機制?
對於第一個問題,我們引用Apache Foundation對MapReduce的介紹“Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
認識了MapReduce 是什麼,關於第二個問題,也就清晰了。MapReduce能做什麼?簡單地講,可以做大資料處理。所謂大資料處理,即以價值為導向,對大資料加工、挖掘和優化等各種處理。
MapReduce擅長處理大資料,它為什麼具有這種能力呢?這可由MapReduce的設計思想發覺。MapReduce的思想就是“分而治之”。Mapper負責“分”,即把複雜的任務分解為若干個“簡單的任務”來處理。“簡單的任務”包含三層含義:一是資料或計算的規模相對原任務要大大縮小;二是就近計算原則,即任務會分配到存放著所需資料的節點上進行計算;三是這些小任務可以平行計算,彼此間幾乎沒有依賴關係。Reducer負責對map階段的結果進行彙總。至於需要多少個Reducer,使用者可以根據具體問題,通過在mapred-site.xml配置檔案裡設定引數mapred.reduce.tasks的值,預設值為1。
MapReduce是如何來處理大資料呢?使用者可以通過編MapReduce應用程式來實現對大資料的操作。既然是用MapReduce程式處理大資料,那麼MapReduce程式怎樣工作呢?這就是第三個問題,即MapReduce的工作機制。
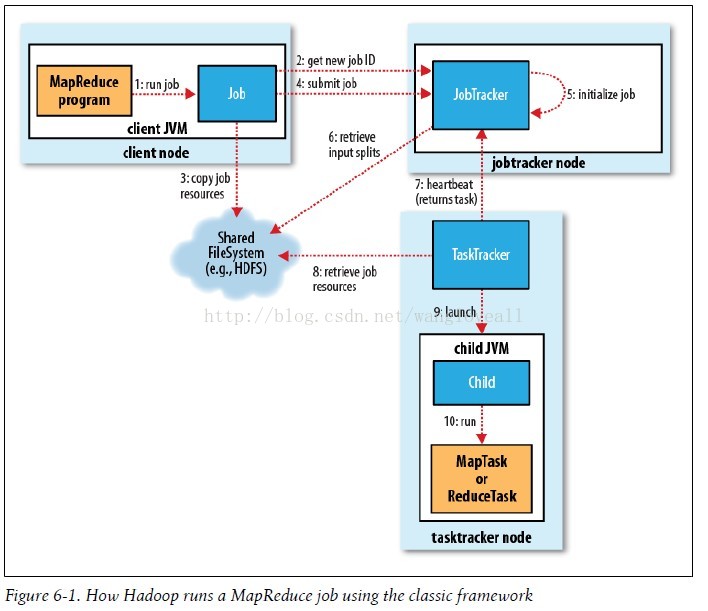
MapReduce的整個工作過程如上圖所示,它包含如下4個獨立的實體。
實體一:客戶端,用來提交MapReduce作業。
實體二:jobtracker,用來協調作業的執行。
實體三:tasktracker,用來處理作業劃分後的任務。
實體四:HDFS,用來在其它實體間共享作業檔案。
通過審閱MapReduce工作流程圖,可以看出MapReduce整個工作過程有序地包含如下工作環節。
環節一:作業的提交
環節二:作業的初始化
環節三:任務的分配
環節四:任務的執行
環節五:程序和狀態的更新
環節六:作業的完成
關於每一個環節裡具體做什麼事情,可以參讀《Hadoop權威指南》的第六章MapReduce工作機制的內容。
對於使用者來說,若是想使用MapReduce來處理大資料,就需要根據需求編寫MapReduce應用程式。因而,如何利用MapReduce框架開發程式,是需要深入思考和不斷實踐的事情。
Source:
4 煉數成金《Hadoop資料分析平臺》課程
5《Hadoop權威指南(第二版)》第六章MapReduce工作機制