
Hadoop之MapReduce程式設計模型
一、MapReduce程式設計模型
MapReduce將作業的整個執行過程分為兩個階段:Map階段和Reduce階段
Map階段由一定數量的Map Task組成
輸入資料格式解析:InputFormat
輸入資料處理:Mapper
資料分組:Partitioner
Reduce階段由一定數量的Reduce Task組成
資料遠端拷貝
資料按照key排序
資料處理:Reducer
資料輸出格式:OutputFormat
二、MapReduce工作原理圖

三、MapReduce程式設計模型—內部邏輯

四、MapReduce程式設計模型—外部物理結構
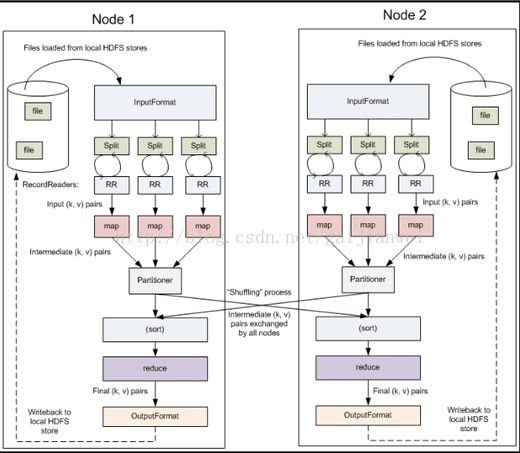
五、MapReduce程式設計模型—InputFormat
5.1 InputFormat API

5.2 InputFormat 負責處理MR的輸入部分.
有三個作用:
1驗證作業的輸入是否規範.
2把輸入檔案切分成InputSplit. (處理跨行問題)
3提供RecordReader 的實現類,把InputSplit讀到Mapper中進行處理.
5.3 InputFormat類的層次結構
六、MapReduce程式設計模型—Split與Block
6.1 Split與Block簡介
Block: HDFS中最小的資料儲存單位,預設是64MB
Spit: MapReduce中最小的計算單元,預設與Block一一對應
Block與Split: Split與Block是對應關係是任意的,可由使用者控制.
6.2 InputSplit
在執行mapreduce之前,原始資料被分割成若干split,每個split作為一個map任務的輸入,在map執行過程中split會被分解成一個個記錄(key-value對),map會依次處理每一個記錄。
1.FileInputFormat只劃分比HDFS block大的檔案,所以FileInputFormat劃分的結果是這個檔案或者是這個檔案中的一部分.
2.如果一個檔案的大小比block小,將不會被劃分,這也是Hadoop處理大檔案的效率要比處理很多小檔案的效率高的原因。
3. 當Hadoop處理很多小檔案(檔案大小小於hdfs block大小)的時候,由於FileInputFormat不會對小檔案進行劃分,所以每一個小檔案都會被當做一個split並分配一個map任務,導致效率底下。例如:一個1G的檔案,會被劃分成16個64MB的split,並分配16個map任務處理,而10000個100kb的檔案會被10000個map任務處理。
七、TextInputFormat
1.TextInputformat是預設的處理類,處理普通文字檔案。
2.檔案中每一行作為一個記錄,他將每一行在檔案中的起始偏移量作為key,每一行的內容作為value。
3.預設以\n或回車鍵作為一行記錄。
4.TextInputFormat繼承了FileInputFormat。
八、其他輸入類
◆ CombineFileInputFormat
相對於大量的小檔案來說,hadoop更合適處理少量的大檔案。
CombineFileInputFormat可以緩解這個問題,它是針對小檔案而設計的。
◆ KeyValueTextInputFormat
當輸入資料的每一行是兩列,並用tab分離的形式的時候,KeyValueTextInputformat處理這種格式的檔案非常適合。
◆ NLineInputformat
NLineInputformat可以控制在每個split中資料的行數。
◆ SequenceFileInputformat
當輸入檔案格式是sequencefile的時候,要使用SequenceFileInputformat作為輸入。
九、自定義輸入格式
1)繼承FileInputFormat基類。
2)重寫裡面的getSplits(JobContext context)方法。
3)重寫createRecordReader(InputSplit split,TaskAttemptContext context)方法。
【研究下原始碼】
十、MapReduce程式設計模型—Combiner

1 每一個map可能會產生大量的輸出,combiner的作用就是在map端對輸出先做一次合併,以減少傳輸到reducer的資料量。
2 combiner最基本是實現本地key的歸併,combiner具有類似本地的reduce功能,合併相同的key對應的value(wordcount例子),通常與Reducer邏輯一樣。
3 如果不用combiner,那麼,所有的結果都是reduce完成,效率會相對低下。使用combiner,先完成的map會在本地聚合,提升速度。
好處:①減少Map Task輸出資料量(磁碟IO)②減少Reduce-Map網路傳輸資料量(網路IO)
【注意:Combiner的輸出是Reducer的輸入,如果Combiner是可插拔(可有可無)的,新增Combiner絕不能改變最終的計算結果。所以Combiner只應該用於那種Reduce的輸入key/value與輸出key/value型別完全一致,且不影響最終結果的場景。比如累加,最大值等。】
十一、MapReduce程式設計模型—Partitioner
1.Partitioner決定了Map Task輸出的每條資料交給哪個Reduce Task處理
2.預設實現:HashPartitioner是mapreduce的預設partitioner。計算方法是 reducer=(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks,得到當前的目的reducer。(hash(key) mod R 其中R是Reduce Task數目)
3.允許使用者自定義
很多情況需自定義Partitioner比如“hash(hostname(URL)) mod R”確保相同域名的網頁交給同一個Reduce Task處理
十二、Reduce的輸出
◆ TextOutputformat
預設的輸出格式,key和value中間值用tab隔開的。
◆ SequenceFileOutputformat
將key和value以sequencefile格式輸出。
◆ SequenceFileAsOutputFormat
將key和value以原始二進位制的格式輸出。
◆ MapFileOutputFormat
將key和value寫入MapFile中。由於MapFile中的key是有序的,所以寫入的時候必須保證記錄是按key值順序寫入的。
◆ MultipleOutputFormat
預設情況下一個reducer會產生一個輸出,但是有些時候我們想一個reducer產生多個輸出,MultipleOutputFormat和MultipleOutputs可以實現這個功能。(還可以自定義輸出格式,序列化會說到)
十三、MapReduce程式設計模型總結
1.Map階段
InputFormat(預設TextInputFormat)
Mapper
Combiner(local reducer)
Partitioner
2.Reduce階段
Reducer
OutputFormat(預設TextOutputFormat)