
預測數值型資料:迴歸(二)
上次我們留了個兩個問題沒有仔細說明,一個是區域性加權線性迴歸,另一個是嶺迴歸。今天依次對這兩種演算法進行說明。
一、區域性加權線性迴歸
欠擬合這種問題是僅僅憑藉一條直線來對資料點進行擬合的線性迴歸演算法所無法避免的,而解決這種欠擬合問題的方法中,有一種最為簡便,稱之為區域性加權線性迴歸。顧名思義,區域性加權線性迴歸就是指給被預測點周圍的資料點賦以不同的權重,讓預測更加註重區域性上的趨勢而不是整體上的趨勢,這樣的操作一旦不注意就會造成過擬合,所以應用的時候要特別注意。
該演算法對應的迴歸係數矩陣計算方法如下:
其中
權重的計算方式有很多種,其主要目標就是賦予待遇測點周圍的資料點相對更高的權重,一般採用高斯核函式來實現這個目標,高斯核函式的形式如下:
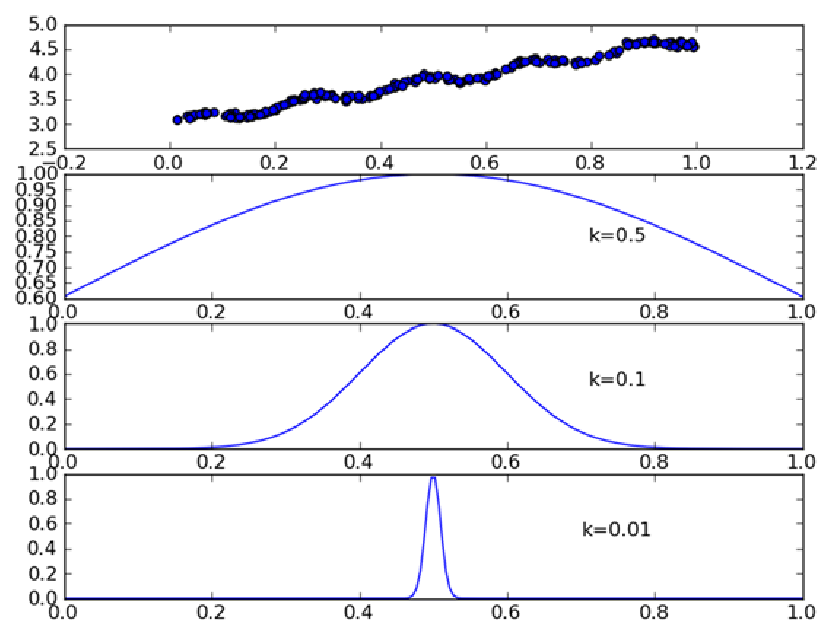
我們可以注意到,
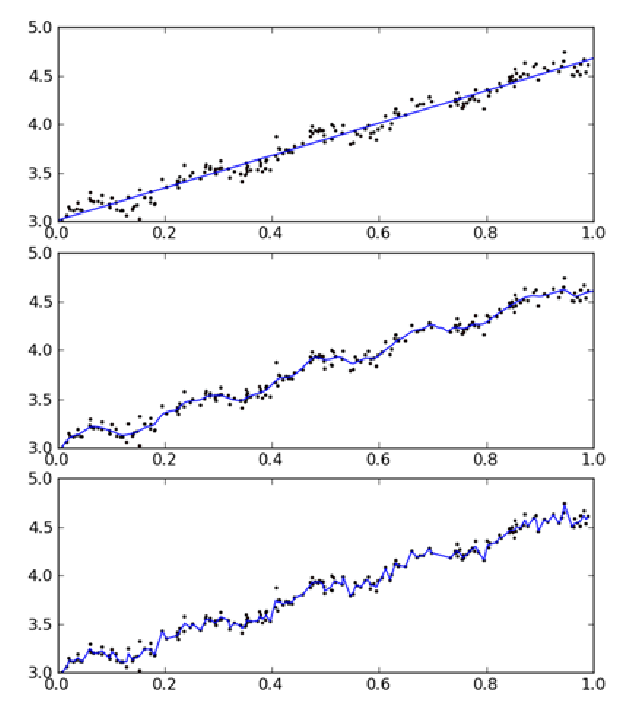
這種方法有助於避免簡單線性迴歸所帶來的欠擬合的問題,然而它可能會帶來過擬合的問題,如下圖所示:
從上圖可以看出,中間的那張明顯比剩下的兩張更加合理一些,基本模擬出了資料的趨勢,而圖三就是
除了容易出現過擬合的問題外,區域性加權線性迴歸的計算量也相當大,因為它對每個待遇測點做預測時都必須遍歷整個資料集才能得出迴歸係數向量,使用時要加以注意。
二、嶺迴歸
使用線性迴歸的一個前提是矩陣
在這種情況下,我們引入嶺迴歸,迴歸係數的計算公式變為:
嶺迴歸演算法通過引入
可以看到,嶺迴歸是在簡單線性迴歸的目標函式後面加了一個二範數懲罰項,其目的在於限制迴歸係數矩陣的取值,減少不必要的引數。顯然,對於不同的
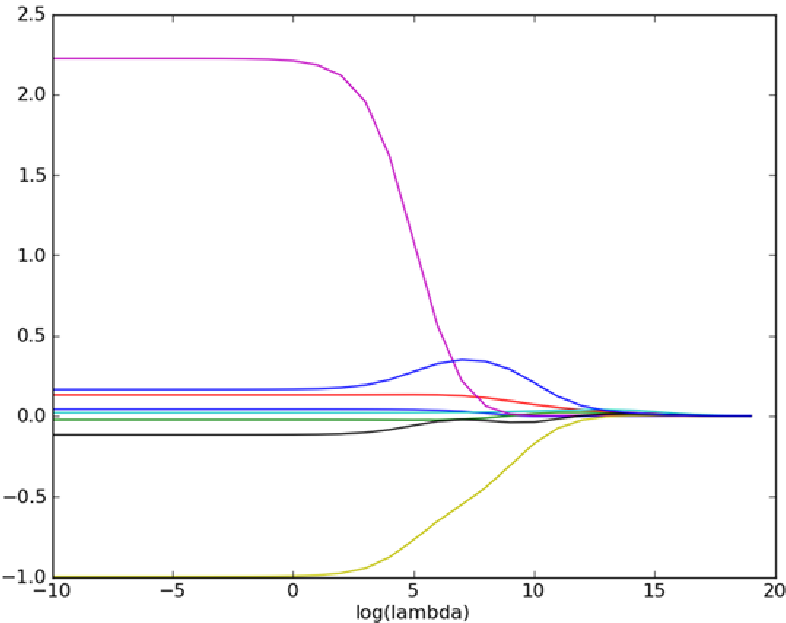
可以看到當
簡而言之,嶺迴歸用於處理自變數之間高度相關的情形。線性迴歸的計算用的是最小二乘估計法,當自變數之間高度相關時,最小二乘迴歸估計的引數估計值會不穩定,這時如果在公式里加點東西,讓它變得穩定,那就解決了這一問題了。嶺迴歸就是這個思想。