David Silver深度強化學習第1課- intro-RL
阿新 • • 發佈:2019-01-22
David Silver深度強化學習第1課 intro-RL

Agent(我們建立的演算法)
演算法就是一個從history對映到action的過程,其中history:
由於history包含了太多冗長的資訊,因此我們用state代替history。
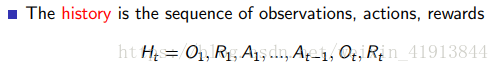
State
state is a function of history
兩種形式的state
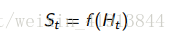
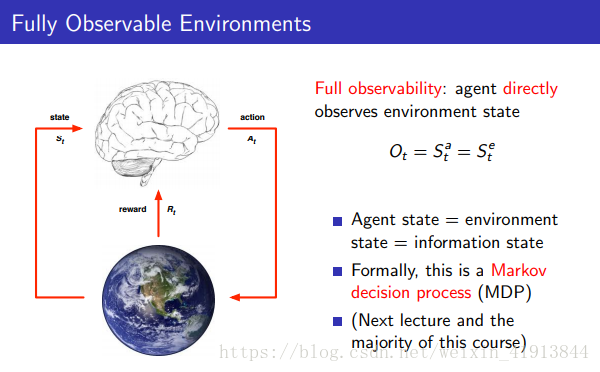
- environment state(環境狀態)
是環境資訊的展示,通常不可視,即使可見也會包含不相關資訊 - agent state
也是數字形式。whatever information the agent uses to pick the
next action
以上兩種狀態的數學形式是Markov狀態。 Markov狀態具有Markov性質:將來的狀態St+1只與現在的狀態St有關,而與過去的狀態無關。(狀態表示法)。現在的狀態St決定了未來所有的觀測、狀態、獎勵、行動。
使用RL時,我們的主要任務即在完全可觀測環境下建立agent狀態,並以此決定下一步的policy。