
David Silver《強化學習RL》第三講 動態規劃尋找最優策略
本講著重講解了利用動態規劃來進行強化學習,具體是進行強化學習中的“規劃”,也就是在已知模型的基礎上判斷一個策略的價值函式,並在此基礎上尋找到最優的策略和最優價值函式,或者直接尋找最優策略和最優價值函式。本講是整個強化學習課程核心內容的引子。
簡介 Introduction
動態規劃演算法是解決複雜問題的一個方法,演算法通過把複雜問題分解為子問題,通過求解子問題進而得到整個問題的解。在解決子問題的時候,其結果通常需要儲存起來被用來解決後續複雜問題。當問題具有下列特性時,通常可以考慮使用動態規劃來求解:第一個特性是:一個複雜問題的最優解由數個小問題的最優解構成,可以通過尋找子問題的最優解來得到複雜問題的最優解;第二個特性是:子問題在複雜問題內重複出現,使得子問題的解可以被儲存起來重複利用。
馬爾科夫決定過程(MDP)具有上述兩個屬性:Bellman方程把問題遞迴為求解子問題,價值函式就相當於儲存了一些子問題的解,可以複用。因此可以使用動態規劃來求解MDP。
我們用動態規劃演算法來求解一類稱為“規劃”的問題。“規劃”指的是在瞭解整個MDP的基礎上求解最優策略,也就是清楚模型結構的基礎上:包括狀態行為空間、轉換矩陣、獎勵等。這類問題不是典型的強化學習問題,我們可以用規劃來進行預測和控制。
具體的數學描述是這樣:
預測:給定一個MDP 和策略
控制:給定一個MDP ,要求確定最優價值函式
迭代法策略評估Iterative Policy Evaluation
- 理論
問題:評估一個給定的策略π,也就是解決“預測”問題。
解決方案:反向迭代應用Bellman期望方程
具體方法:同步反向迭代,即在每次迭代過程中,對於第 次迭代,所有的狀態s的價值用
![]() 計算並更新該狀態第
計算並更新該狀態第 次迭代中使用的價值
![]() ,其中s’是s的後繼狀態。
,其中s’是s的後繼狀態。
此種方法通過反覆迭代最終將收斂至 。
也可以非同步反向迭代,即在第k次迭代使用當次迭代的狀態價值來更新狀態價值。
公式為:

即:一次迭代內,狀態s的價值等於前一次迭代該狀態的即時獎勵與所有s的下一個可能狀態s' 的價值與其概率乘積的和,如圖示:
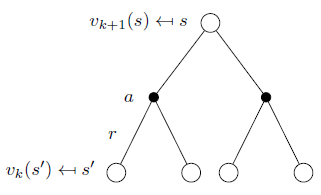
公式的矩陣形式是:
![]()
- 示例——方格世界
已知:
狀態空間S:如圖。S1 - S14非終止狀態,ST終止狀態,下圖灰色方格所示兩個位置;
行為空間A:{n, e, s, w} 對於任何非終止狀態可以有東南西北移動四個行為;
轉移概率P:任何試圖離開方格世界的動作其位置將不會發生改變,其餘條件下將100%地轉移到動作指向的狀態;
即時獎勵R:任何在非終止狀態間的轉移得到的即時獎勵均為-1,進入終止狀態即時獎勵為0;
衰減係數γ:1;
當前策略π:Agent採用隨機行動策略,在任何一個非終止狀態下有均等的機率採取任一移動方向這個行為,即π(n|•) = π(e|•) = π(s|•) = π(w|•) = 1/4。
問題:評估在這個方格世界裡給定的策略。
該問題等同於:求解該方格世界在給定策略下的(狀態)價值函式,也就是求解在給定策略下,該方格世界裡每一個狀態的價值。
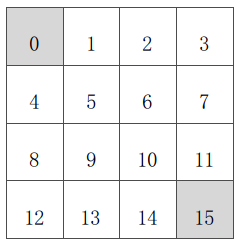
迭代法求解(迭代法進行策略評估)

對於上圖的補充:


狀態價值在第153次迭代後收斂
在實踐環節,我們將使用Python對此問題進行求解演示。
- 如何改善策略
通過方格世界的例子,我們得到了一個優化策略的辦法,分為兩步:首先我們在一個給定的策略下迭代更新價值函式:
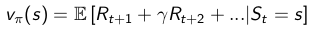
隨後,在當前策略基礎上,貪婪地選取行為,使得後繼狀態價值增加最多:
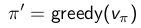
在剛才的格子世界中,基於給定策略的價值迭代最終收斂得到的策略就是最優策略,但通過一個回合的迭代計算價值聯合策略改善就能找到最優策略不是普遍現象。通常,還需在改善的策略上繼續評估,反覆多次。不過這種方法總能收斂至最優策略 。
這就是接下來要介紹的策略迭代。
策略迭代 Policy Iteration
在當前策略上迭代計算v值,再根據v值貪婪地更新策略,如此反覆多次,最終得到最優策略 和最優狀態價值函式
。
貪婪 指的是僅採取那個(些)使得狀態價值得到最大的行為。

- 示例——連鎖汽車租賃
舉了一個汽車租賃的例子,說明如何在給定策略下得到基於該策略的價值函式,並根據更新的價值函式來調整策略,直至得到最優策略和最優價值函式。
一個連鎖汽車租賃公司有兩個地點提供汽車租賃,由於不同的店車輛租賃的市場條件不一樣,為了能夠實現利潤最大化,該公司需要在每天下班後在兩個租賃點轉移車輛,以便第二天能最大限度的滿足兩處汽車租賃服務。
已知
狀態空間:2個地點,每個地點最多20輛車供租賃
行為空間:每天下班後最多轉移5輛車從一處到另一處;
即時獎勵:每租出1輛車獎勵10元,必須是有車可租的情況;不考慮在兩地轉移車輛的支出。
轉移概率:求租和歸還是隨機的,但是滿足泊松分佈 。第一處租賃點平均每天租車請求3次,歸還3次;第二處租賃點平均每天租車4次,歸還2次。
衰減係數 :0.9;
問題:怎樣的策略是最優策略?
求解方法:從一個確定的策略出發進行迭代,該策略可以是較為隨意的,比如選擇這樣的策略:不管兩地租賃業務市場需求,不移動車輛。以此作為給定策略進行價值迭代,當迭代收斂至一定程度後,改善策略,隨後再次迭代,如此反覆,直至最終收斂。
在這個問題中,狀態用兩個地點的汽車存量來描述,比如分別用c1,c2表示租賃點1,2兩處的可租汽車數量,可租汽車數量同時參與決定夜間可轉移汽車的最大數量。
解決該問題的核心就是依據泊松分佈確定狀態<c1,c2>的即時獎勵,進而確定每一個狀態的價值。

- 策略改善——理論證明
1. 考慮一個確定的策略:
2. 通過貪婪計算優化策略:
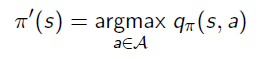
3. 這會用1步迭代改善狀態s的q值,即在當前策略下,狀態s在動作π’(s)下得到的q值等於當前策略下狀態s所有可能動作得到的q值中的最大值。這個值一般不小於使用當前策略得到的行為所的得出的q值,因而也就是該狀態的狀態價值。
4. 如果q值不再改善,則在某一狀態下,遵循當前策略採取的行為得到的q值將會是最優策略下所能得到的最大q值,上述表示就滿足了Bellman最優方程,說明當前策略下的狀態價值就是最優狀態價值。
5. 因而此時的策略就是最優策略。
注:以下為數學公式證明。


思考:很多時候,策略的更新較早就收斂至最優策略,而狀態價值的收斂要慢很多,是否有必要一定要迭代計算直到狀態價值得到收斂呢?
- 修飾過的策略迭代 Modified Policy Iteration
有時候不需要持續迭代至最優價值函式,可以設定一些條件提前終止迭代,比如設定一個Ɛ,比較兩次迭代的價值函式平方差;直接設定迭代次數;以及每迭代一次更新一次策略等。
價值迭代 Value Iteration
- 優化原則 Principle of Optimality
一個最優策略可以被分解為兩部分:從狀態s到下一個狀態s’採取了最優行為 ;在狀態s’時遵循一個最優策略。
定理:一個策略能夠使得狀態s獲得最優價值,當且僅當:對於從狀態s可以到達的任何狀態s’,該策略能夠使得狀態s’的價值是最優價值:

- 確定性的價值迭代 Deterministic Value Iteration:
在前一個定理的基礎上,如果我們清楚地知道我們期望的最終(goal)狀態的位置以及反推需要明確的狀態間關係,那麼可以認為是一個確定性的價值迭代。此時,我們可以把問題分解成一系列的子問題,從最終目標狀態開始分析,逐漸往回推,直至推至所有狀態。
- 示例——最短路徑

問題:如何在一個4*4的方格世界中,找到任一一個方格到最左上角方格的最短路徑
解決方案1:確定性的價值迭代
簡要思路:在已知左上角為最終目標的情況下,我們可以從與左上角相鄰的兩個方格開始計算,因為這兩個方格是可以僅通過1步就到達目標狀態的狀態,或者說目標狀態是這兩個狀態的後繼狀態。最短路徑可以量化為:每移動一步獲得一個-1的即時獎勵。為此我們可以更新與目標方格相鄰的這兩個方格的狀態價值為-1。如此依次向右下角倒推,直至所有狀態找到最短路徑。
解決方案2:價值迭代
簡要思路:並不確定最終狀態在哪裡,而是根據每一個狀態的最優後續狀態價值來更新該狀態的最佳狀態價值,這裡強調的是每一個。多次迭代最終收斂。這也是根據一般適用性的價值迭代。在這種情況下,就算不知道目標狀態在哪裡,這套系統同樣可以工作。
- 價值迭代 value iteration
問題:尋找最優策略π
解決方案:從初始狀態價值開始同步迭代計算,最終收斂,整個過程中沒有遵循任何策略。
注意:與策略迭代不同,在值迭代過程中,演算法不會給出明確的策略,迭代過程其間得到的價值函式,不對應任何策略。
價值迭代雖然不需要策略參與,但仍然需要知道狀態之間的轉移概率,也就是需要知道模型。
- 小結 - 動態規劃

預測問題:在給定策略下迭代計算價值函式。控制問題:策略迭代尋找最優策略問題則先在給定或隨機策略下計算狀態價值函式,根據狀態函式貪婪更新策略,多次反覆找到最優策略;單純使用價值迭代,全程沒有策略參與也可以獲得最優策略,但需要知道狀態轉移矩陣,即狀態s在行為a後到達的所有後續狀態及概率。
使用狀態價值函式或行為價值函式兩種價值迭代的演算法時間複雜度都較大,為 或
。一種改進方案是使用非同步動態規劃,其他的方法即放棄使用動態規劃,隨後的幾講中將詳細講解其他方法。
動態規劃的一些擴充套件
- 非同步動態規劃 Asynchronous Dynamic Programming
幾個可能改進的點子
原位動態規劃(In-place dynamic programming):直接原地更新下一個狀態的v值,而不像同步迭代那樣需要額外儲存新的v值。在這種情況下,按何種次序更新狀態價值有時候會比較有意義。

重要狀態優先更新(Priortised Sweeping):對那些重要的狀態優先更新。
使用Bellman error:
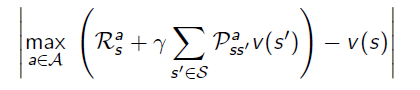
來確定哪些狀態是比較重要的。Bellman error 反映的是當前的狀態價值與更新後的狀態價值差的絕對值。Bellman error越大,越有必要優先更新。對那些Bellman error較大的狀態進行備份。這種演算法使用優先順序佇列能夠較得到有效的實現。
Real-time dynamic programming:更新那些僅與個體關係密切的狀態,同時使用個體的經驗來知道更新狀態的選擇。有些狀態雖然理論上存在,但在現實中幾乎不會出現。利用已有現實經驗。
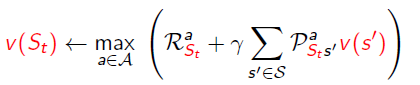
St是實際與Agent相關或者說Agent經歷的狀態,可以省去關於那些僅存在理論上的狀態的計算。
- 取樣更新 Sample Backups
動態規劃使用full-width backups。意味著使用DP演算法,對於每一次狀態更新,都要考慮到其所有後繼狀態及所有可能的行為,同時還要使用MDP中的狀態轉移矩陣、獎勵函式(資訊)。DP解決MDP問題的這一特點決定了其對中等規模(百萬級別的狀態數)的問題較為有效,對於更大規模的問題,會帶來Bellman維度災難。
因此在面對大規模MDP問題是,需要尋找更加實際可操作的演算法,主要的思想是Sample Backups,後續會詳細介紹。這類演算法的優點是不需要完整掌握MDP的條件(例如獎勵機制、狀態轉移矩陣等),通過Sampling(舉樣)可以打破維度災難,反向更新狀態函式的開銷是常數級別的,與狀態數無關。
- 近似動態規劃 Approximate Dynamic Programming
使用其他技術手段(例如神經網路)建立一個引數較少,消耗計算資源較少、同時雖然不完全精確但卻夠用的近似價值函式:

注:本講的內容主要還是在於理解強化學習的基本概念,各種Bellman方程,在實際應用中,很少使用動態規劃來解決大規模強化學習問題。