
kafka的offset是個什麼鬼。。
轉:http://blog.csdn.net/looklook5/article/details/42008079
之前在做Kafka 整合Storm的時候,因為對Kafka 不是很熟,考慮過這樣的一個場景問題,針對一個Topic,Kafka訊息日誌中有個offset資訊來標註訊息的位置,Storm每次從kafka 消費資料,都是通過zookeeper儲存的資料offset,來判斷需要獲取訊息在訊息日誌裡的起始位置。
那麼我們想,這個Offset 是訊息在日誌裡是一個什麼樣的位置,是絕對位置還是相對位置?而Kafla 有個引數log.retention.hours會根據設定的小時,來清理日誌檔案。這樣就可能會有這樣的一個問題,針對一個Topic,Kafka 生產資料後,消費者消費資訊後,此時的訊息的offset是一個高位,比如100,消費者在消費完會記錄這個offset準備下個數據的獲取。而當系統時間達到引數log.retention.hours
所以做了一個針對性測試。
將log.retention.hours設定為1個小時,然後重啟kafka,建立一個測試Topic,然後往這個Topic裡生產點資料,然後消費者那邊也有輸出,保證程式通順正常。觀察引數log.dirs=/tmp/kafka-logs目錄下對應的話題目錄。
下圖是Topic下面的訊息日誌。

然後等一個小時後,繼續觀察日誌
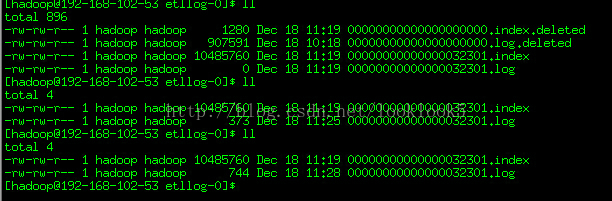
我們發現之前的訊息日誌被打上deleted 標誌,然後並生成了新的日誌。且日誌名稱改變了。
這個時候我們再生產資料會發現Kafka消費者還是能夠正常輸出資料的。那麼之前假設offset是訊息日誌的絕對位置是不成立的。
下面是我是摘錄的。
- 日誌
- 如果一個topic的名稱為"my_topic",它有2個partitions,那麼日誌將會儲存在my_topic_0和my_topic_1兩個目錄中;日誌檔案中儲存了一序列"log entries"(日誌條目),每個log entry格式為"4個位元組的數字N表示訊息的長度" + "N個位元組的訊息內容";每個日誌都有一個offset來唯一的標記一條訊息,offset的值為8個位元組的數字,表示此訊息在此partition中所處的起始位置..每個partition在物理儲存層面,有多個log file組成(稱為segment).segment file的命名為"最小offset".kafka.例如"00000000000.kafka";其中"最小offset"表示此segment中起始訊息的offset.
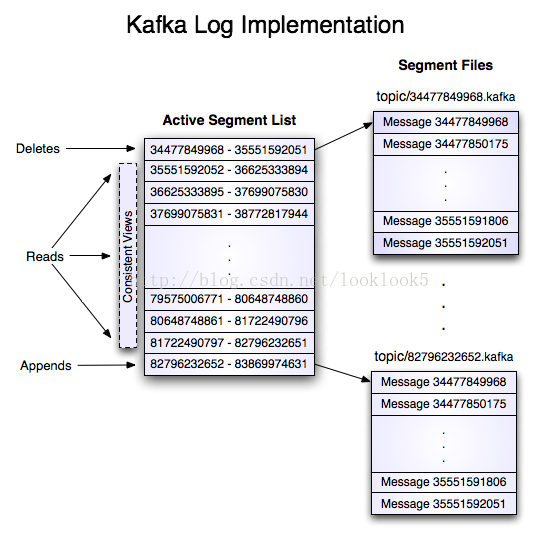
- 其中每個partiton中所持有的segments列表資訊會儲存在zookeeper中.
- 當segment檔案尺寸達到一定閥值時(可以通過配置檔案設定,預設1G),將會建立一個新的檔案;當buffer中訊息的條數達到閥值時將會觸發日誌資訊flush到日誌檔案中,同時如果"距離最近一次flush的時間差"達到閥值時,也會觸發flush到日誌檔案.如果broker失效,極有可能會丟失那些尚未flush到檔案的訊息.因為server意外失敗,仍然會導致log檔案格式的破壞(檔案尾部),那麼就要求當server啟動時需要檢測最後一個segment的檔案結構是否合法並進行必要的修復.
- 獲取訊息時,需要指定offset和最大chunk尺寸,offset用來表示訊息的起始位置,chunk size用來表示最大獲取訊息的總長度(間接的表示訊息的條數).根據offset,可以找到此訊息所在segment檔案,然後根據segment的最小offset取差值,得到它在file中的相對位置,直接讀取輸出即可.
- 日誌檔案的刪除策略非常簡單:啟動一個後臺執行緒定期掃描log file列表,把儲存時間超過閥值的檔案直接刪除(根據檔案的建立時間).為了避免刪除檔案時仍然有read操作(consumer消費),採取copy-on-write方式.
從文章中可以看出,訊息日誌名是最小offset位置,訊息所在位置加上檔名的offset就是訊息的offset位置,而系統沒生成一個新的日誌後會就將最後的offset作為新日誌檔案的檔名。我們可以認為kafka 訊息日誌裡的offset實際就相當於是一個增量序列索引。那樣我們就不用糾結消費資料的時候會不會丟失,而可以安心關注Storm的業務問題了