
Kafka的深度解析
一個典型的kafka叢集中包含若干producer(可以是web前端產生的page view,或者是伺服器日誌,系統CPU、memory等),若干broker(Kafka支援水平擴充套件,一般broker數量越多,叢集吞吐率越高),若干consumer group,以及一個Zookeeper叢集。Kafka通過Zookeeper管理叢集配置,選舉leader,以及在consumer group發生變化時進行rebalance。producer使用push模式將訊息釋出到broker,consumer使用pull模式從broker訂閱並消費訊息。
背景介紹
Kafka簡介
Kafka是一種分散式的,基於釋出/訂閱的訊息系統。主要設計目標如下:
- 以時間複雜度為O(1)的方式提供訊息持久化能力,即使對TB級以上資料也能保證常數時間的訪問效能
- 高吞吐率。即使在非常廉價的商用機器上也能做到單機支援每秒100K條訊息的傳輸
- 支援Kafka Server間的訊息分割槽,及分散式消費,同時保證每個partition內的訊息順序傳輸
- 同時支援離線資料處理和實時資料處理
為什麼要用Message Queue
-
解耦
在專案啟動之初來預測將來專案會碰到什麼需求,是極其困難的。訊息佇列在處理過程中間插入了一個隱含的、基於資料的介面層,兩邊的處理過程都要實現這一介面。這允許你獨立的擴充套件或修改兩邊的處理過程,只要確保它們遵守同樣的介面約束 -
冗餘
有些情況下,處理資料的過程會失敗。除非資料被持久化,否則將造成丟失。訊息佇列把資料進行持久化直到它們已經被完全處理,通過這一方式規避了資料丟失風險。在被許多訊息佇列所採用的”插入-獲取-刪除”正規化中,在把一個訊息從佇列中刪除之前,需要你的處理過程明確的指出該訊息已經被處理完畢,確保你的資料被安全的儲存直到你使用完畢。 -
擴充套件性
因為訊息佇列解耦了你的處理過程,所以增大訊息入隊和處理的頻率是很容易的;只要另外增加處理過程即可。不需要改變程式碼、不需要調節引數。擴充套件就像調大電力按鈕一樣簡單。 -
靈活性 & 峰值處理能力
在訪問量劇增的情況下,應用仍然需要繼續發揮作用,但是這樣的突發流量並不常見;如果為以能處理這類峰值訪問為標準來投入資源隨時待命無疑是巨大的浪費。使用訊息佇列能夠使關鍵元件頂住突發的訪問壓力,而不會因為突發的超負荷的請求而完全崩潰。 -
可恢復性
當體系的一部分元件失效,不會影響到整個系統。訊息佇列降低了程序間的耦合度,所以即使一個處理訊息的程序掛掉,加入佇列中的訊息仍然可以在系統恢復後被處理。而這種允許重試或者延後處理請求的能力通常是造就一個略感不便的使用者和一個沮喪透頂的使用者之間的區別。 -
送達保證
訊息佇列提供的冗餘機制保證了訊息能被實際的處理,只要一個程序讀取了該佇列即可。在此基礎上,IronMQ提供了一個”只送達一次”保證。無論有多少程序在從佇列中領取資料,每一個訊息只能被處理一次。這之所以成為可能,是因為獲取一個訊息只是”預定”了這個訊息,暫時把它移出了佇列。除非客戶端明確的表示已經處理完了這個訊息,否則這個訊息會被放回佇列中去,在一段可配置的時間之後可再次被處理。
-
順序保證
在大多使用場景下,資料處理的順序都很重要。訊息佇列本來就是排序的,並且能保證資料會按照特定的順序來處理。IronMO保證訊息通過FIFO(先進先出)的順序來處理,因此訊息在佇列中的位置就是從佇列中檢索他們的位置。 -
緩衝
在任何重要的系統中,都會有需要不同的處理時間的元素。例如,載入一張圖片比應用過濾器花費更少的時間。訊息佇列通過一個緩衝層來幫助任務最高效率的執行—寫入佇列的處理會盡可能的快速,而不受從佇列讀的預備處理的約束。該緩衝有助於控制和優化資料流經過系統的速度。 -
理解資料流
在一個分散式系統裡,要得到一個關於使用者操作會用多長時間及其原因的總體印象,是個巨大的挑戰。訊息系列通過訊息被處理的頻率,來方便的輔助確定那些表現不佳的處理過程或領域,這些地方的資料流都不夠優化。 -
非同步通訊
很多時候,你不想也不需要立即處理訊息。訊息佇列提供了非同步處理機制,允許你把一個訊息放入佇列,但並不立即處理它。你想向佇列中放入多少訊息就放多少,然後在你樂意的時候再去處理它們。
常用Message Queue對比
-
RabbitMQ
RabbitMQ是使用Erlang編寫的一個開源的訊息佇列,本身支援很多的協議:AMQP,XMPP, SMTP, STOMP,也正因如此,它非常重量級,更適合於企業級的開發。同時實現了Broker構架,這意味著訊息在傳送給客戶端時先在中心佇列排隊。對路由,負載均衡或者資料持久化都有很好的支援。 -
Redis
Redis是一個基於Key-Value對的NoSQL資料庫,開發維護很活躍。雖然它是一個Key-Value資料庫儲存系統,但它本身支援MQ功能,所以完全可以當做一個輕量級的佇列服務來使用。對於RabbitMQ和Redis的入隊和出隊操作,各執行100萬次,每10萬次記錄一次執行時間。測試資料分為128Bytes、512Bytes、1K和10K四個不同大小的資料。實驗表明:入隊時,當資料比較小時Redis的效能要高於RabbitMQ,而如果資料大小超過了10K,Redis則慢的無法忍受;出隊時,無論資料大小,Redis都表現出非常好的效能,而RabbitMQ的出隊效能則遠低於Redis。 -
ZeroMQ
ZeroMQ號稱最快的訊息佇列系統,尤其針對大吞吐量的需求場景。ZMQ能夠實現RabbitMQ不擅長的高階/複雜的佇列,但是開發人員需要自己組合多種技術框架,技術上的複雜度是對這MQ能夠應用成功的挑戰。ZeroMQ具有一個獨特的非中介軟體的模式,你不需要安裝和執行一個訊息伺服器或中介軟體,因為你的應用程式將扮演了這個服務角色。你只需要簡單的引用ZeroMQ程式庫,可以使用NuGet安裝,然後你就可以愉快的在應用程式之間傳送訊息了。但是ZeroMQ僅提供非永續性的佇列,也就是說如果宕機,資料將會丟失。其中,Twitter的Storm 0.9.0以前的版本中預設使用ZeroMQ作為資料流的傳輸(Storm從0.9版本開始同時支援ZeroMQ和Netty作為傳輸模組)。 -
ActiveMQ
ActiveMQ是Apache下的一個子專案。 類似於ZeroMQ,它能夠以代理人和點對點的技術實現佇列。同時類似於RabbitMQ,它少量程式碼就可以高效地實現高階應用場景。 -
Kafka/Jafka
Kafka是Apache下的一個子專案,是一個高效能跨語言分散式釋出/訂閱訊息佇列系統,而Jafka是在Kafka之上孵化而來的,即Kafka的一個升級版。具有以下特性:快速持久化,可以在O(1)的系統開銷下進行訊息持久化;高吞吐,在一臺普通的伺服器上既可以達到10W/s的吞吐速率;完全的分散式系統,Broker、Producer、Consumer都原生自動支援分散式,自動實現複雜均衡;支援Hadoop資料並行載入,對於像Hadoop的一樣的日誌資料和離線分析系統,但又要求實時處理的限制,這是一個可行的解決方案。Kafka通過Hadoop的並行載入機制來統一了線上和離線的訊息處理。Apache Kafka相對於ActiveMQ是一個非常輕量級的訊息系統,除了效能非常好之外,還是一個工作良好的分散式系統。
Kafka解析
Terminology
-
Broker
Kafka叢集包含一個或多個伺服器,這種伺服器被稱為broker -
Topic
每條釋出到Kafka叢集的訊息都有一個類別,這個類別被稱為topic。(物理上不同topic的訊息分開儲存,邏輯上一個topic的訊息雖然保存於一個或多個broker上但使用者只需指定訊息的topic即可生產或消費資料而不必關心資料存於何處) -
Partition
parition是物理上的概念,每個topic包含一個或多個partition,建立topic時可指定parition數量。每個partition對應於一個資料夾,該資料夾下儲存該partition的資料和索引檔案 -
Producer
負責釋出訊息到Kafka broker -
Consumer
消費訊息。每個consumer屬於一個特定的consuer group(可為每個consumer指定group name,若不指定group name則屬於預設的group)。使用consumer high level API時,同一topic的一條訊息只能被同一個consumer group內的一個consumer消費,但多個consumer group可同時消費這一訊息。
Kafka架構
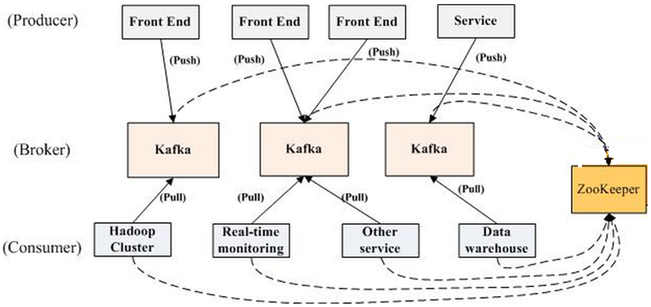
如上圖所示,一個典型的kafka叢集中包含若干producer(可以是web前端產生的page view,或者是伺服器日誌,系統CPU、memory等),若干broker(Kafka支援水平擴充套件,一般broker數量越多,叢集吞吐率越高),若干consumer group,以及一個Zookeeper叢集。Kafka通過Zookeeper管理叢集配置,選舉leader,以及在consumer group發生變化時進行rebalance。producer使用push模式將訊息釋出到broker,consumer使用pull模式從broker訂閱並消費訊息。
Push vs. Pull
作為一個messaging system,Kafka遵循了傳統的方式,選擇由producer向broker push訊息並由consumer從broker pull訊息。一些logging-centric system,比如Facebook的Scribe和Cloudera的Flume,採用非常不同的push模式。事實上,push模式和pull模式各有優劣。
push模式很難適應消費速率不同的消費者,因為訊息傳送速率是由broker決定的。push模式的目標是儘可能以最快速度傳遞訊息,但是這樣很容易造成consumer來不及處理訊息,典型的表現就是拒絕服務以及網路擁塞。而pull模式則可以根據consumer的消費能力以適當的速率消費訊息。
Topic & Partition
Topic在邏輯上可以被認為是一個在的queue,每條消費都必須指定它的topic,可以簡單理解為必須指明把這條訊息放進哪個queue裡。為了使得Kafka的吞吐率可以水平擴充套件,物理上把topic分成一個或多個partition,每個partition在物理上對應一個資料夾,該資料夾下儲存這個partition的所有訊息和索引檔案。

每個日誌檔案都是“log entries”序列,每一個log entry包含一個4位元組整型數(值為N),其後跟N個位元組的訊息體。每條訊息都有一個當前partition下唯一的64位元組的offset,它指明瞭這條訊息的起始位置。磁碟上儲存的消費格式如下:
message length : 4 bytes (value: 1+4+n)
“magic” value : 1 byte
crc : 4 bytes
payload : n bytes
這個“log entries”並非由一個檔案構成,而是分成多個segment,每個segment名為該segment第一條訊息的offset和“.kafka”組成。另外會有一個索引檔案,它標明瞭每個segment下包含的log entry的offset範圍,如下圖所示。
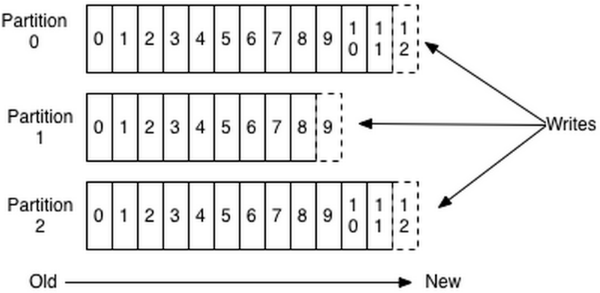
因為每條訊息都被append到該partition中,是順序寫磁碟,因此效率非常高(經驗證,順序寫磁碟效率比隨機寫記憶體還要高,這是Kafka高吞吐率的一個很重要的保證)。
每一條訊息被髮送到broker時,會根據paritition規則選擇被儲存到哪一個partition。如果partition規則設定的合理,所有訊息可以均勻分佈到不同的partition裡,這樣就實現了水平擴充套件。(如果一個topic對應一個檔案,那這個檔案所在的機器I/O將會成為這個topic的效能瓶頸,而partition解決了這個問題)。在建立topic時可以在$KAFKA_HOME/config/server.properties中指定這個partition的數量(如下所示),當然也可以在topic建立之後去修改parition數量。
- # The default number of log partitions per topic. More partitions allow greater
- # parallelism for consumption, but this will also result in more files across
- # the brokers.
- num.partitions=3
在傳送一條訊息時,可以指定這條訊息的key,producer根據這個key和partition機制來判斷將這條訊息傳送到哪個parition。paritition機制可以通過指定producer的paritition. class這一引數來指定,該class必須實現kafka.producer.Partitioner介面。本例中如果key可以被解析為整數則將對應的整數與partition總數取餘,該訊息會被髮送到該數對應的partition。(每個parition都會有個序號)
- import kafka.producer.Partitioner;
- import kafka.utils.VerifiableProperties;
- publicclass JasonPartitioner<T> implements Partitioner {
- public JasonPartitioner(VerifiableProperties verifiableProperties) {}
- @Override
- publicint partition(Object key, int numPartitions) {
- try {
- int partitionNum = Integer.parseInt((String) key);
- return Math.abs(Integer.parseInt((String) key) % numPartitions);
- } catch (Exception e) {
- return Math.abs(key.hashCode() % numPartitions);
- }
- }
- }
如果將上例中的class作為partition.class,並通過如下程式碼傳送20條訊息(key分別為0,1,2,3)至topic2(包含4個partition)。
- publicvoid sendMessage() throws InterruptedException{
- for(int i = 1; i <= 5; i++){
- List messageList = new ArrayList<KeyedMessage<String, String>>();
- for(int j = 0; j < 4; j++){
- messageList.add(new KeyedMessage<String, String>("topic2", j+"", "The " + i + " message for key " + j));
- }
- producer.send(messageList);
- }
- producer.close();
- }
則key相同的訊息會被髮送並存儲到同一個partition裡,而且key的序號正好和partition序號相同。(partition序號從0開始,本例中的key也正好從0開始)。如下圖所示。

對於傳統的message queue而言,一般會刪除已經被消費的訊息,而Kafka叢集會保留所有的訊息,無論其被消費與否。當然,因為磁碟限制,不可能永久保留所有資料(實際上也沒必要),因此Kafka提供兩種策略去刪除舊資料。一是基於時間,二是基於partition檔案大小。例如可以通過配置$KAFKA_HOME/config/server.properties,讓Kafka刪除一週前的資料,也可通過配置讓Kafka在partition檔案超過1GB時刪除舊資料,如下所示。
- ############################# Log Retention Policy #############################
- # The following configurations control the disposal of log segments. The policy can
- # be set to delete segments after a period of time, or after a given size has accumulated.
- # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
- # from the end of the log.
- # The minimum age of a log file to be eligible for deletion
- log.retention.hours=168
- # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining
- # segments don't drop below log.retention.bytes.
- #log.retention.bytes=1073741824
- # The maximum size of a log segment file. When this size is reached a new log segment will be created.
- log.segment.bytes=1073741824
- # The interval at which log segments are checked to see if they can be deleted according
- # to the retention policies
- log.retention.check.interval.ms=300000
- # By default the log cleaner is disabled and the log retention policy will default to
- #just delete segments after their retention expires.
- # If log.cleaner.enable=true is set the cleaner will be enabled and individual logs
- #can then be marked for log compaction.
- log.cleaner.enable=false
這裡要注意,因為Kafka讀取特定訊息的時間複雜度為O(1),即與檔案大小無關,所以這裡刪除檔案與Kafka效能無關,選擇怎樣的刪除策略只與磁碟以及具體的需求有關。另外,Kafka會為每一個consumer group保留一些metadata資訊—當前消費的訊息的position,也即offset。這個offset由consumer控制。正常情況下consumer會在消費完一條訊息後線性增加這個offset。當然,consumer也可將offset設成一個較小的值,重新消費一些訊息。因為offet由consumer控制,所以Kafka broker是無狀態的,它不需要標記哪些訊息被哪些consumer過,不需要通過broker去保證同一個consumer group只有一個consumer能消費某一條訊息,因此也就不需要鎖機制,這也為Kafka的高吞吐率提供了有力保障。
Replication & Leader election
Kafka從0.8開始提供partition級別的replication,replication的數量可在$KAFKA_HOME/config/server.properties中配置。
- default.replication.factor = 1
該 Replication與leader election配合提供了自動的failover機制。replication對Kafka的吞吐率是有一定影響的,但極大的增強了可用性。預設情況下,Kafka的replication數量為1。每個partition都有一個唯一的leader,所有的讀寫操作都在leader上完成,leader批量從leader上pull資料。一般情況下partition的數量大於等於broker的數量,並且所有partition的leader均勻分佈在broker上。follower上的日誌和其leader上的完全一樣。
和大部分分散式系統一樣,Kakfa處理失敗需要明確定義一個broker是否alive。對於Kafka而言,Kafka存活包含兩個條件,一是它必須維護與Zookeeper的session(這個通過Zookeeper的heartbeat機制來實現)。二是follower必須能夠及時將leader的writing複製過來,不能“落後太多”。
leader會track“in sync”的node list。如果一個follower宕機,或者落後太多,leader將把它從”in sync” list中移除。這裡所描述的“落後太多”指follower複製的訊息落後於leader後的條數超過預定值,該值可在$KAFKA_HOME/config/server.properties中配置
- #If a replica falls more than this many messages behind the leader, the leader will remove the follower from ISR and treat it as dead
- replica.lag.max.messages=4000
- #If a follower hasn't sent any fetch requests for this window of time, the leader will remove the follower from ISR (in-sync replicas) and treat it as dead
- replica.lag.time.max.ms=10000
需要說明的是,Kafka只解決”fail/recover”,不處理“Byzantine”(“拜占庭”)問題。
一條訊息只有被“in sync” list裡的所有follower都從leader複製過去才會被認為已提交。這樣就避免了部分資料被寫進了leader,還沒來得及被任何follower複製就宕機了,而造成資料丟失(consumer無法消費這些資料)。而對於producer而言,它可以選擇是否等待訊息commit,這可以通過request.required.acks來設定。這種機制確保了只要“in sync”
list有一個或以上的flollower,一條被commit的訊息就不會丟失。
這裡的複製機制即不是同步複製,也不是單純的非同步複製。事實上,同步複製要求“活著的”follower都複製完,這條訊息才會被認為commit,這種複製方式極大的影響了吞吐率(高吞吐率是Kafka非常重要的一個特性)。而非同步複製方式下,follower非同步的從leader複製資料,資料只要被leader寫入log就被認為已經commit,這種情況下如果follwer都落後於leader,而leader突然宕機,則會丟失資料。而Kafka的這種使用“in sync” list的方式則很好的均衡了確保資料不丟失以及吞吐率。follower可以批量的從leader複製資料,這樣極大的提高複製效能(批量寫磁碟),極大減少了follower與leader的差距(前文有說到,只要follower落後leader不太遠,則被認為在“in sync” list裡)。
上文說明了Kafka是如何做replication的,另外一個很重要的問題是當leader宕機了,怎樣在follower中選舉出新的leader。因為follower可能落後許多或者crash了,所以必須確保選擇“最新”的follower作為新的leader。一個基本的原則就是,如果leader不在了,新的leader必須擁有原來的leader commit的所有訊息。這就需要作一個折衷,如果leader在標明一條訊息被commit前等待更多的follower確認,那在它die之後就有更多的follower可以作為新的leader,但這也會造成吞吐率的下降。