
Spark優化及總結
轉自:http://blog.csdn.net/ljj657137723/article/details/52134962
本篇文章是關於我在學習Spark過程中遇到的一些問題及總結,分為Spark優化、RDD join問題、遇到的問題、總結、參考資料幾個部分。
一:Spark優化
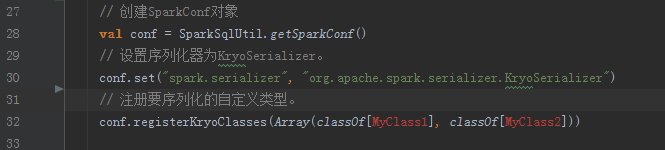
1、設定序列化器為KryoSerializer
Spark預設使用的是Java序列化機制,但是Spark也支援使用Kryo序列化庫,Kryo序列化機制比Java序列化機制效能高10倍左右
2、壓縮機制
如果資料量很大,在序列化的同時可以考慮使用壓縮,lzf的壓縮效率要高很多, 當然如果使用了壓縮,也會消耗CPU和記憶體資源

3、TDW 表寫入禁止覆蓋
最終寫入TDW的RDD可能是多個,因此需要設定TDW表寫入禁止覆蓋,這樣就可以避免使用RDD UNION操作

4、啟用Spark推測機制

5、reduceByKey代替groupByKey
groupByKey會將所有的計算放在reduce階段進行,會導致全量資料在節點間傳輸,而reduceByKey會在map端對本地資料進行聚合,之後將計算的結果進行shuffle,因此可以大量的減少shuffle的資料,減少網路IO,提高執行效率,在reduceByKey的函式中,還可以去實現某個欄位的sum,max,min,count等操作
6、map和mapPartitions
mapPartitions是針對Partitiion進行操作,那麼操作中的很多物件和變數都可以複用,比如廣播變數等
map是處理partitiion中的一條資料,因此mapPartition的效率要高一些,但是mapPartitions也存在缺陷,由於一次處理一個partitiion的資料,在記憶體不足的時候會因此OOM
7、foreach和foreachPartitions
類似與map和mapPartitions的關係,前者是針對partition中的資料一條條進行處理,後者是針對一個partition進行處理,後者適合在和外部資料庫互動操作時使用,比如MySQL,通過這種方法可以避免頻繁的建立和銷燬連結,還可以進行批處理,比如使用JDBC在mysql資料庫中批量插入,同樣也存在缺陷,會遇到OOM
8、cache和persist
如果需要重複使用RDD,可以考慮使用快取操作,cache是將RDD快取到記憶體中,適合資料量比較小的RDD,對於persist而言,可以根據不同的業務場景選擇不同的持久化級別。
二:RDD join 問題
程式RDD 的join問題的一些總結:A表join B表,對B表進行更新問題,都可以把錶轉換成(k,v)的形式(k可以由多個欄位拼接而成,v可以是一個物件,也可以是一個欄位),最終問題轉化為A(k,v) join B(k,v) on A.k = B.k
1、full join
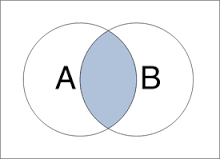
使用場景:A表和B表進行full join,並且A表比B表的資料量不在一個數量級,如果在一個數量級,則直接使用full out join運算元執行
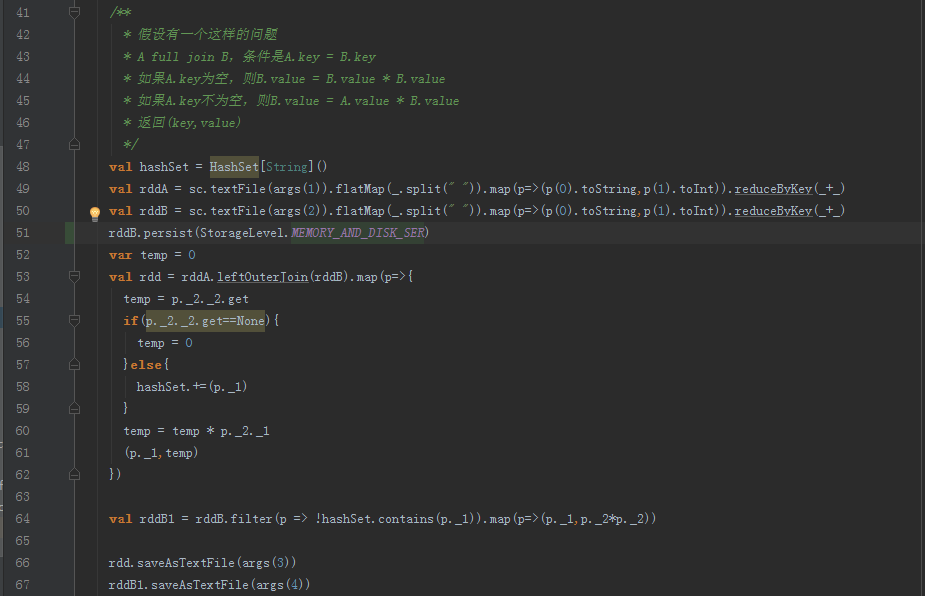
方案:
①把full out join轉化為A表left out join B表
②之後進行map操作,根據A對B進行更新
③map操作中用HashSet記錄A 和B交集的key
④根據③中得到的HashSet對B進行filter操作,過濾掉已經left out join的記錄,然後對B中剩下的記錄進行foreach遍歷更新
⑤呼叫TDW介面把RDD分別寫入檔案中
程式碼:
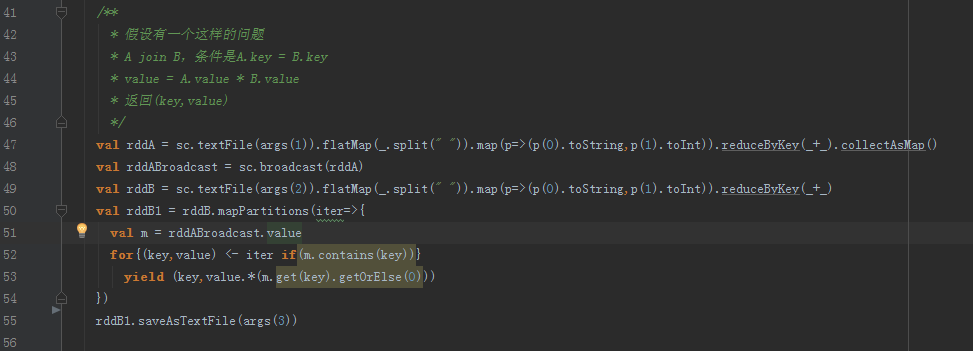
2、小表join大表
使用場景:
一個小表A和一個大表B的連線操作,小表指檔案足夠小,可以載入到記憶體中,該演算法可以將join運算元執行在Map端,無需經歷shuffe和reduce等階段,因此效率很高
方案:
①把A(k,v)進行廣播
②在Map端對B進行過濾和更新
③把更新後的RDD寫入檔案中
程式碼:
3、大表join大表
使用場景:
當兩個表資料量非常大,其中任何一個都不能夠放到記憶體中,可以使用Spark的join運算元,通過該運算元實現reduce-side-join
概念:RDD依賴關係
在spark中如何表示RDD之間的依賴關係分為兩類:
①窄依賴:每個父RDD的分割槽都至多被一個子RDD的分割槽使用,即為OneToOneDependecies;
②寬依賴:多個子RDD的分割槽依賴一個父RDD的分割槽,即為OneToManyDependecies。
例如,map操作是一種窄依賴,而join操作是一種寬依賴(除非父RDD已經基於Hash策略被劃分過了)
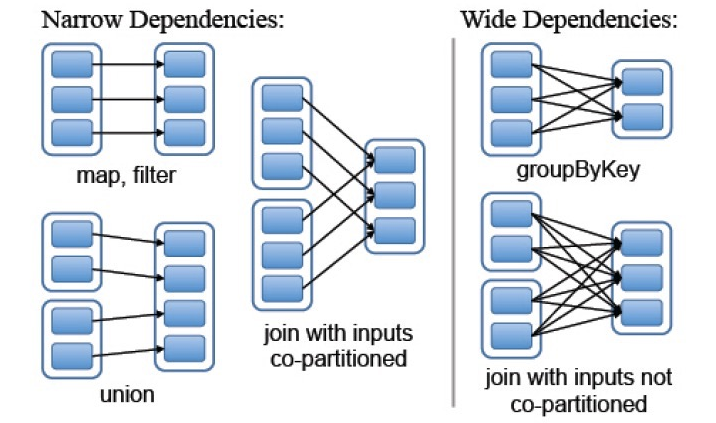
圖:寬依賴和窄依賴
方案:
由上圖可知,join分為寬依賴和窄依賴,如果RDD有相同的partitioner,那麼將不會引起shuffle,因此我們可以對RDD進行Hash分割槽。分別對A和B用同一個函式進行Partition,比如按照首字母進行Partition,那麼A和B都可以分成26個Partition,並且A1只需要和B1進行join,A1不需要和B剩下的25個Partition進行join,這樣就大大的減少了join次數,最好的辦法是對錶進行分割槽,每次只取兩個對應分割槽的資料進行join操作。具體的Hash Partition函式需要根據具體的應用場景實現,比如:如果key是URL,那麼就可以根據域名進行分割槽。分割槽大小需要根據task-nums、num-executors以及executor-cores確定。
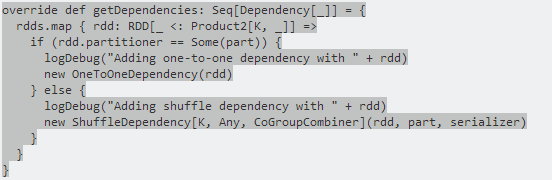
圖:Spark中CoGroupedRDD.scala原始碼
程式碼:
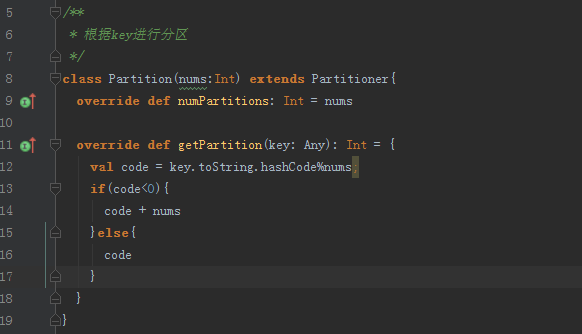
圖:分割槽函式

圖:對RDD進行分割槽
4、RDD join引起 shuffle問題
請參考《Spark效能優化指南》系列,裡邊詳細講解了引起shuffle的原因,以及不通場景的解決辦法,強烈推薦。
三:遇到的問題
列出我在寫Spark程式遇到的兩個問題:
1、RDD的API所引用的所有物件,都必須是可序列化的

圖:RDD中引用物件
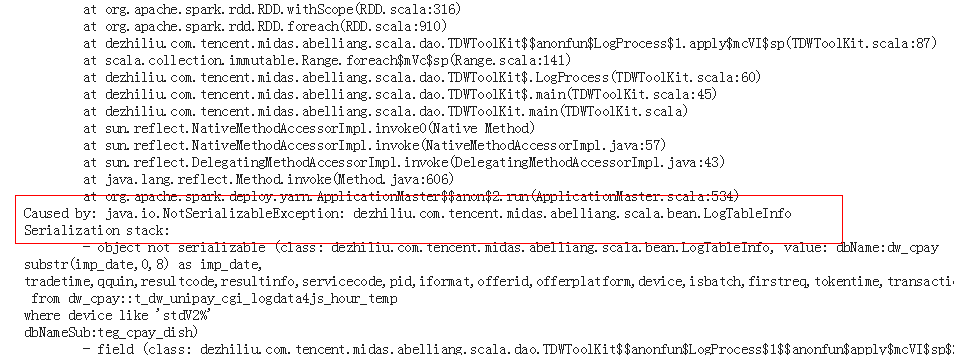
圖:報錯資訊
在RDD的API裡所引用的在RDD的API裡所引用的所有物件,都必須是可序列化的,因為RDD分佈在多臺機器是,程式碼和所引用的物件會序列化,然後複製到多臺機器,所以凡是被引用的資料,都必須是可序列化的。否則會報java.lang.NotSerializableException: scala.util.Random 異常,解決辦法就是把引用物件序列化 extends Serializable或者使用kryo序列化。
在一個RDD的api裡不可以引用另外一個RDD
SPARK-5063 in spark,Spark does not support nested RDDs or performing Spark actions inside of transformations; this usually leads to NullPointerExceptions (seeSPARK-718 as one example). The confusing NPE is one of the most common sources of Spark questions on StackOverflow:
上邊英文大致意思是:Spark的transformation運算元中不支援巢狀RDD,會導致空指標,如果其中一個RDD資料量不大,則可以用文章中提高的廣播變數解決這個問題,如果資料量很大使用廣播變數會導致OOM,那麼就要從其他方面進行優化或者從業務邏輯進行出發。
四:總結
這一個月我的主要工作是把Sql轉化成Spark程式,以及去不斷的去優化,提高效率。在把Sql轉化成Spark程式有很多可以優化的點,我選擇了其中一個點進行了總結,總結的有不妥的地方,歡迎拍磚,一起交流。
時間過的很快,在這裡已經實習一個月了,在導師dezhiliu和小組成員的幫助下 ,自己成長了很多,也學到了很多東西,不僅僅是Spark相關的。特別的感謝我的導師和我的小夥伴們。
如果您喜歡我寫的博文,讀後覺得收穫很大,不妨小額贊助我一下,讓我有動力繼續寫出高質量的博文,感謝您的讚賞!!!
