
聚類算法分類及總結
版權聲明:本文為博主原創文章,未經博主允許不得轉載,或者轉載的時候標出源文章網址。
一、原型聚類

1.k均值聚類(k-means聚類)

其算法流程如下;


下面我們對西瓜數據進行分析,和舉例,讓我們比較容易的理解K-means聚類算法;

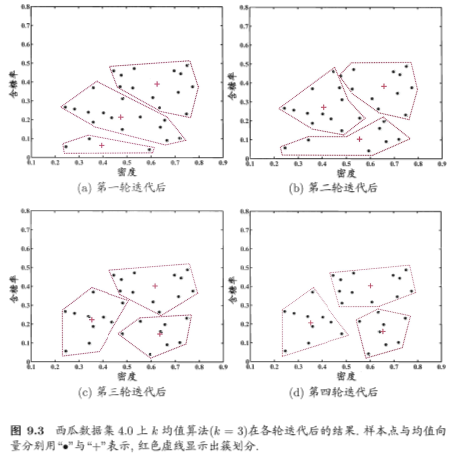
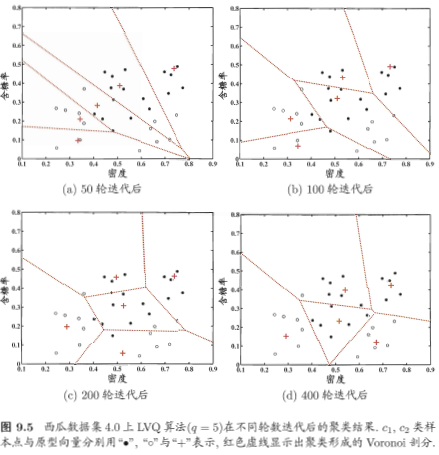
2.學習向量化

算法思想如下:





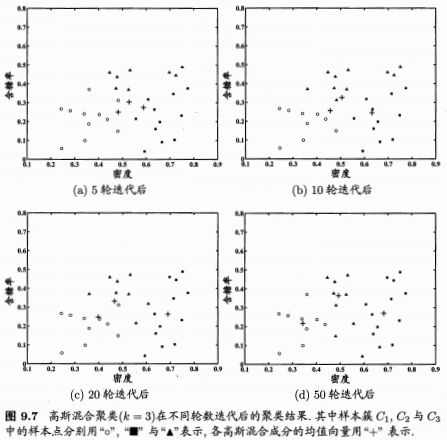
3.高斯混合聚類








下面還是一個列子:說實話前面一連串的理論知識也沒很看懂。迷迷糊糊,列子還是很清楚的。

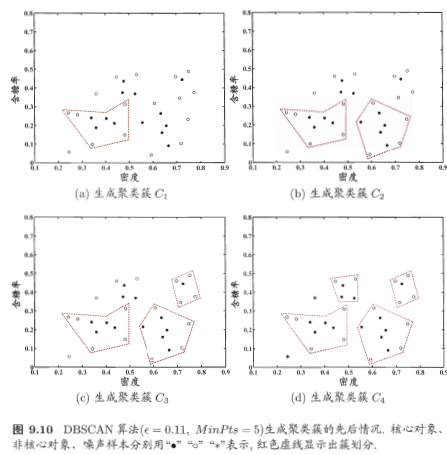
二、密度聚類-這裏主要介紹DBSCAN算法

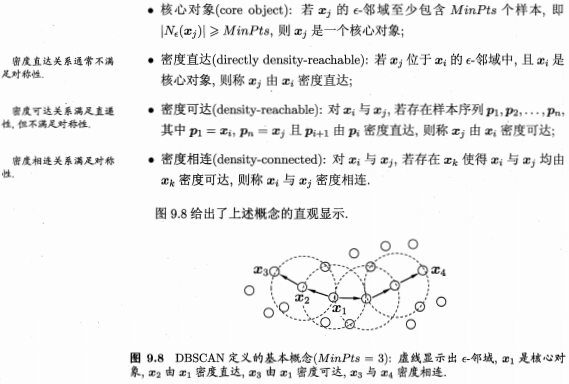

其算法思想如下:


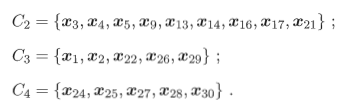
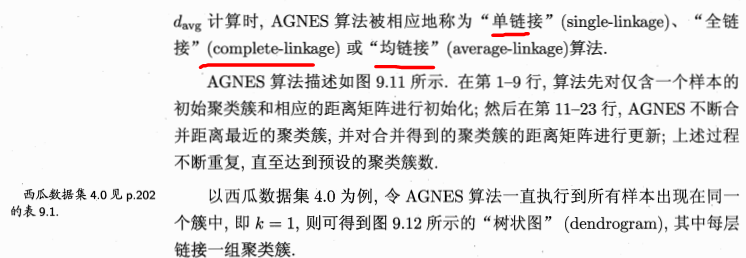
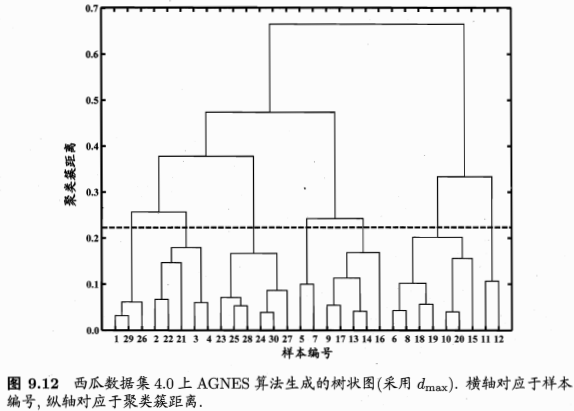
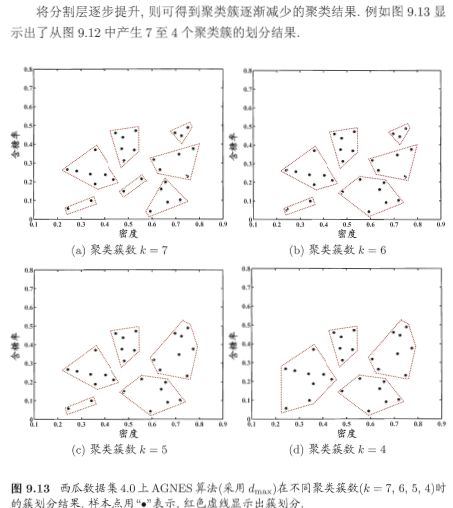
三、層次聚類-主要講解AGNES


基本思想如下:


聚類算法分類及總結
相關推薦
聚類算法分類及總結
理解 迷糊 舉例 分享 mean 容易 9.png 文章 sca 版權聲明:本文為博主原創文章,未經博主允許不得轉載,或者轉載的時候標出源文章網址。 一、原型聚類 1.k均值聚類(k-means聚類) 其算法流程如下; 下面我們對西瓜
機器學習:Python實現聚類算法(三)之總結
.fig ask class ted ssi 缺點 處理 blob ron 考慮到學習知識的順序及效率問題,所以後續的幾種聚類方法不再詳細講解原理,也不再寫python實現的源代碼,只介紹下算法的基本思路,使大家對每種算法有個直觀的印象,從而可以更好的理解函數中
聚類算法和分類算法總結
特點 實際應用 內容 target 利用 很好 次數 超過 得到 原文:http://blog.chinaunix.net/uid-10289334-id-3758310.html 聚類算法的種類:基於劃分聚類算法(partition clustering)
通過IDEA及hadoop平臺實現k-means聚類算法
綜合 tle tostring html map apache cnblogs cos textfile 有段時間沒有操作過,發現自己忘記一些步驟了,這篇文章會記錄相關步驟,並隨時進行補充修改。 1 基礎步驟,即相關環境部署及數據準備 數據文件類型為.csv文件,excel
【譜聚類算法總結】
logs 缺點 文字檢測 什麽 spa 公司 聚類 16px 總結 前言:以前只是調用過譜聚類算法,我也不懂為什麽各家公司都問我一做文字檢測的這個算法具體咋整的,沒整明白還給我掛了哇擦嘞?訊飛和百度都以這個理由刷本寶,今天一怒把它給整吧清楚了,下次誰再問來!說不暈你算我輸!
Canopy聚類算法
數據預處理 stage border 虛線 其他 重復 str ati 通過 一、概念 與傳統的聚類算法(比如K-means)不同,Canopy聚類最大的特點是不需要事先指定k值(即clustering的個數),因此具有很大的實際應用價值。與其他聚類算法相比,Can
K均值聚類算法的MATLAB實現
均值 選擇 自己 eps 隨機生成 工具 images num step 1.K-均值聚類法的概述 之前在參加數學建模的過程中用到過這種聚類方法,但是當時只是簡單知道了在matlab中如何調用工具箱進行聚類,並不是特別清楚它的原理。最近因為在學模式識別,又重新接觸了這
【機器學習】DBSCAN Algorithms基於密度的聚類算法
多次 使用 缺點 有效 結束 基於 需要 att 共享 一、算法思想: DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一個比較有代表性的基於密度的聚
基於K-means Clustering聚類算法對電商商戶進行級別劃分(含Octave仿真)
fprintf highlight 初始 load ogre max init 金額 定時 在從事電商做頻道運營時,每到關鍵時間節點,大促前,季度末等等,我們要做的一件事情就是品牌池打分,更新所有店鋪的等級。例如,所以的商戶分入SKA,KA,普通店鋪,新店鋪這4個級別,對於
mahout in Action2.2-聚類介紹-K-means聚類算法
過程 swing 浪漫 res cto 等等 算法 結合 -m 聚類介紹 本章包含 1 實戰操作了解聚類 2.了解相似性概念 3 使用mahout執行一個簡單的聚類實例 4.用於聚類的各種不同的
ML: 聚類算法R包-K中心點聚類
logs lib str ini rac 缺點 criterion spa mea K-medodis與K-means比較相似,但是K-medoids和K-means是有區別的,不一樣的地方在於中心點的選取,在K-means中,我們將中心點取為當前clust
ML: 聚類算法R包 - 密度聚類
images 另一個 plot 鄰居 一個 lib note packages pac 密度聚類 fpc::dbscan fpc::dbscan DBSCAN核心思想:如果一個點,在距它Eps的範圍內有不少於MinPts個點,則該點就是核心點。核心和它Eps
ML: 聚類算法R包 - 模型聚類
ref 獲取 rar 算法 users 分類樹 html hat _id 模型聚類 mclust::Mclust RWeka::Cobweb mclust::Mclust EM算法也稱為期望最大化算法,在是使用該算法聚類時,將數據集看作一個有隱形變量的概率模型,並
ML: 聚類算法R包-模糊聚類
應用 type with 概念 all cluster summary 傳統 需要 1965年美國加州大學柏克萊分校的紮德教授第一次提出了‘集合’的概念。經過十多年的發展,模糊集合理論漸漸被應用到各個實際應用方面。為克服非此即彼的分類缺點,出現了以模糊集合論為
ML: 聚類算法R包-對比
rar spl stat ecs ror .cn cnblogs add run 測試驗證環境 數據: 7w+ 條,數據結構如下圖: > head(car.train) DV DC RV RC SOC HV LV HT
利用譜聚類算法解決非完全圖的聚類
out img 通過 ctr 技術 href 是我 sta 選擇 在處理非完全圖的聚類時候,很難找到一個有效的聚類算法去做聚類。 對於下圖來說,10號點和15號點的位置相隔並不是那麽近,如用普通聚類算法對下圖做聚類,通常會把10號點和15號點聚在一個類上,所以一般的
K-均值(K-means)聚類算法
簡單 read 原理 包含 append 添加 url 學習 readlines 聚類是一種無監督的學習,它將相似的對象歸到同一個簇中。 這篇文章介紹一種稱為K-均值的聚類算法,之所以稱為K-均值是因為它可以發現k個不同的簇,且每個簇的中心采用簇中所含值的均值計算而成。 聚
聚類算法學習-kmeans,kmedoids,GMM
org 文本分類 文本 sof cnblogs 還會在 targe soft zip GMM參考這篇文章:Link 簡單地說,k-means 的結果是每個數據點被 assign 到其中某一個 cluster 了,而 GMM 則給出這些數據點被 assign 到每個 cl
K-Means 聚類算法原理分析與代碼實現
oat 得到 ssi targe fan readline txt __name__ 輸出 轉自穆晨 閱讀目錄 前言 現實中的聚類分析問題 - 總統大選 K-Means 聚類算法 K-Means性能優化 二分K-Means算法 小結 回到頂部 前言 在