
【Java原始碼】集合類-JDK1.8 雜湊表-紅黑樹-HashMap總結
阿新 • • 發佈:2019-07-02
JDK 1.8 HashMap是陣列+連結串列+紅黑樹實現的,在閱讀HashMap的原始碼之前先來回顧一下大學課本資料結構中的雜湊表和紅黑樹。
什麼是雜湊表?
- 在儲存結構中,關鍵值key通過一種關係f和唯一的儲存位置相對應,關係f即雜湊函式,Hash(k)=f(k)。按這個思想建立的表就是雜湊表。
- 當有兩個不相等的關鍵字key1和key2,但f(key1)=f(key2)這兩個key地址相同,就發生了衝突現象。
- 衝突不能避免只能減少,通過設計均勻的雜湊函式來減少。
常用雜湊函式?
1. 直接定址法
Hash(key) = a*key + b (a,b為常數)
取關鍵字的某種線性關係,實際中使用較少。
2. 初留餘數法
Hash(key) = key mod p (p,整數)
即關鍵字key除以p的餘數作為地址。
3.數字分析法,平方取中法,摺疊法
處理衝突的方法?
處理衝突就是為這個關鍵字找到另一個空的雜湊地址。
1.開放地址法
- 線性探測法
- 二次探測法
- 雙雜湊函式探測法
2.拉鍊法
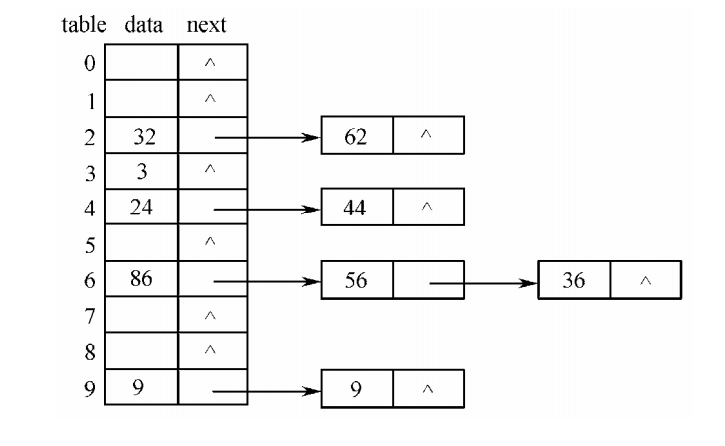
- 拉鍊法的基本思想是,根據關鍵字k,將資料元素存放在雜湊基表中的i=hash(k)位置上。如果產生衝突,則建立一個結點存放該資料元素,並將該結點插入到一個連結串列中。這種由衝突的資料元素構成的連結串列稱為雜湊連結串列。一個雜湊基表與若干條雜湊連結串列相連。
- 例如,對於如下的關鍵字序列:{9,9,24,44,32,86,36,3,62,56}設雜湊函式 hash(k) = k % 10,hash(k)對應雜湊基表 table 的下標值 i,採用拉鍊法的雜湊表結構如圖:
紅黑樹
紅黑樹本質上就是一棵二叉查詢樹(二叉排序樹),紅黑樹的查詢、插入、刪除的時間複雜度最壞為O(log n)。
什麼是二叉查詢樹(二叉排序樹)?
二叉查詢樹(Binary Search Tree)也就是二叉排序樹。特徵性質:
- 任意結點的左子樹不空,則左子樹上所有結點的值均小於它的根結點的值;
- 任意結點的右子樹不空,則右子樹上所有結點的值均大於它的根結點的值;
- 左、右子樹也為二叉查詢樹。
- 按中序遍歷可以得到有序序列。
什麼是紅黑樹?
維基百科定義:https://zh.wikipedia.org/wiki/%E7%BA%A2%E9%BB%91%E6%A0%91
紅黑樹(英語:Red–black tree)是一種自平衡二叉查詢樹,是在電腦科學中用到的一種資料結構,典型的用途是實現關聯陣列。它在1972年由魯道夫·貝爾發明,被稱為"對稱二叉B樹",它現代的名字源於Leo J. Guibas和Robert Sedgewick於1978年寫的一篇論文。紅黑樹的結構複雜,但它的操作有著良好的最壞情況執行時間,並且在實踐中高效:它可以在log n時間內完成查詢,插入和刪除,這裡的n是樹中元素的數目。
特徵性質:
- 節點是紅色或黑色。
- 根結點是黑的。
- 所有葉子都是黑色(葉子是NIL節點)。
- 每個紅色節點必須有兩個黑色的子節點。(從每個葉子到根的所有路徑上不能有兩個連續的紅色節點。)
- 對於任一結點而言,其到葉結點的每一條路徑都包含相同數目的黑結點

JDK 1.8 Map介面
public interface Map<K,V> {
int size(); //返回Map中鍵值對的個數
boolean isEmpty(); //檢查map是否為空
boolean containsKey(Object key); //檢視map是否包含某個鍵
boolean containsValue(Object value); //檢視map是否包含某個值
V put(K key, V value); //儲存,若原來有這個key則覆蓋並返回原來的值
V get(Object key); //根據key獲取值, 若沒找到,則返回null
V remove(Object key); //根據key刪除, 返回key原來的值,若不存在,則返回null
void putAll(Map<? extends K, ? extends V> m); //將m中的所有鍵值對到當前的Map
void clear(); //清空Map
Set<K> keySet(); //返回Map中所有鍵
Collection<V> values(); //返回Map中所有值
Set<Map.Entry<K, V>> entrySet(); //返回Map中所有鍵值對
//內部介面,表示一個鍵值對
interface Entry<K,V> {
K getKey(); //返回鍵
V getValue(); //返回值
V setValue(V value); //setvalue
}
}HashMap特點
- 根據鍵的hashCode值儲存資料,大多數情況下可以直接定位到它的值,因而具有很快的訪問速度,但遍歷順序卻是不確定的。
- HashMap最多隻允許一條記錄的鍵為null,允許多條記錄的值為null。
- HashMap非執行緒安全,即任一時刻可以有多個執行緒同時寫HashMap,可能會導致資料的不一致。如果需要滿足執行緒安全,可以用Collections的synchronizedMap方法使HashMap具有執行緒安全的能力,或者使用ConcurrentHashMap。
- 負載因子可以修改,也可以大於1,建議不要輕易修改,除非特殊情況。
內部資料結構:
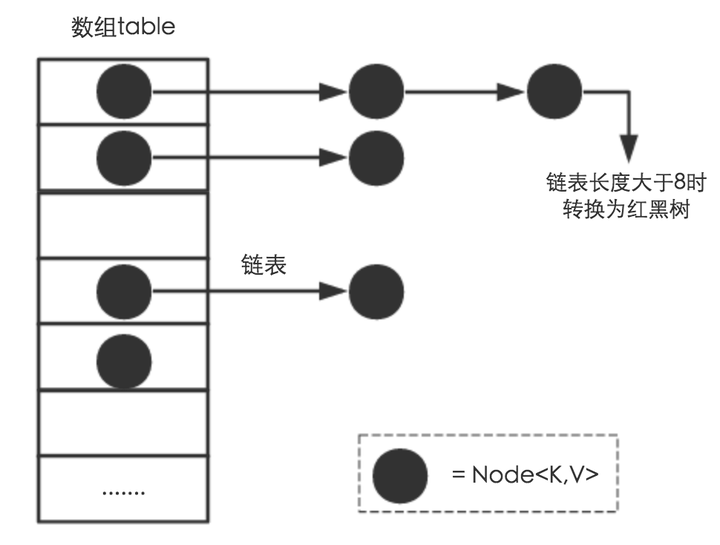
HashMap 類屬性
transient Node<k,v>[] table; 這個類屬性就是雜湊桶陣列
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 序列號
private static final long serialVersionUID = 362498820763181265L;
// 預設的初始容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 預設的負載因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 當桶(bucket)上的結點數大於這個值時會轉成紅黑樹
static final int TREEIFY_THRESHOLD = 8;
// 當桶(bucket)上的結點數小於這個值時樹轉連結串列
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中結構轉化為紅黑樹對應的table的最小大小
static final int MIN_TREEIFY_CAPACITY = 64;
// 儲存元素的陣列,總是2的冪次倍(雜湊桶陣列)
transient Node<k,v>[] table;
// 存放具體元素的集
transient Set<map.entry<k,v>> entrySet;
// 存放元素的個數,注意這個不等於陣列的長度。
transient int size;
// 每次擴容和更改map結構的計數器
transient int modCount;
// 臨界值 當實際大小(容量*填充因子)超過臨界值時,會進行擴容
int threshold;
// 負載因子
final float loadFactor;
}內部類Node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
......
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
....
}
public final boolean equals(Object o) {
......
}
}建構函式
- 無參建構函式預設長度16,負載因子0.75
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}- 指定容量,負載因子0.75
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}- 指定容量和指定負載因子
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}重要函式
內部hash方法(獲得的hash值用於putVal方法中確定雜湊桶陣列索引位置)
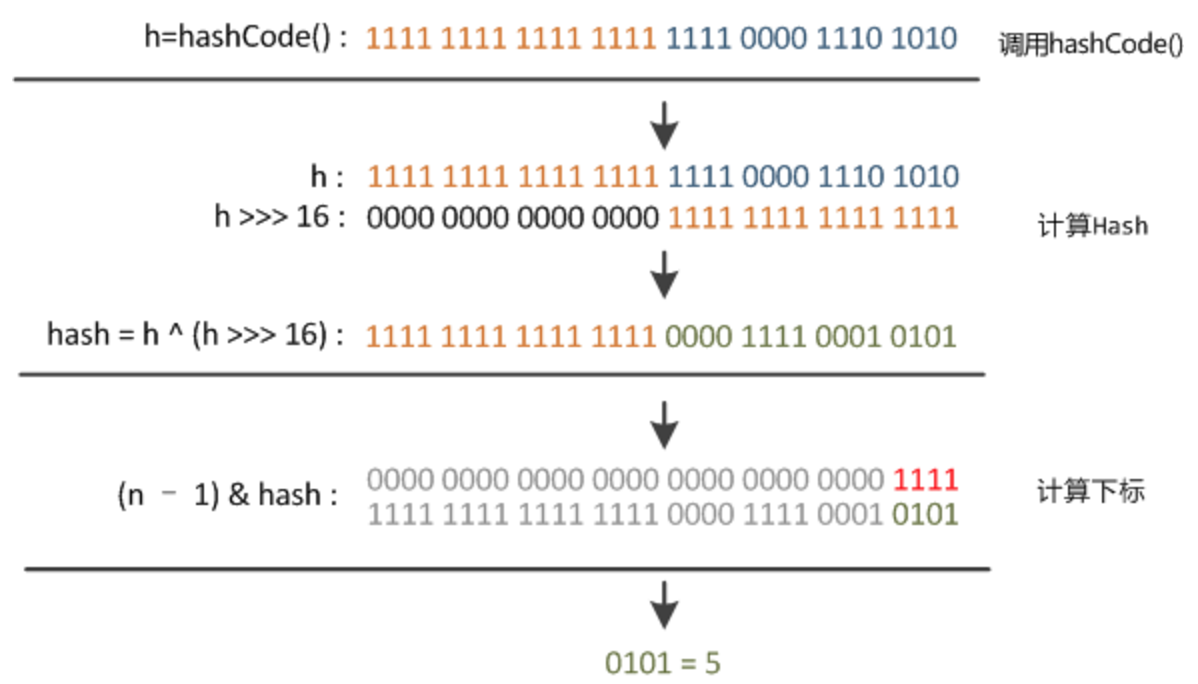
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}- 第一步呼叫object的hashCode:h = key.hashCode() 取hashCode值
- h ^ (h >>> 16) 首先進行無符號右移(>>>)運算,再通過異或運算(^)得到hash值。
put方法,put內部呼叫的是putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//首先確定table是不是為空,如果為空進行擴容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//取模運算,確定雜湊桶陣列索引位置
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//節點key存在,直接覆蓋value
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//判斷是否是紅黑樹
else if (p instanceof TreeNode)
//如果是紅黑樹,則直接在樹中插入鍵值對
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//為連結串列
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//判斷連結串列長度是否大於8,大於8把連結串列轉換為紅黑樹
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//key已經存在直接覆蓋value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//判斷實際存在的鍵值對數量size是否超多了最大容量threshold,如果超過,進行擴容。
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}- i = (n - 1) & hash;通過取模運算,確定雜湊桶陣列索引位置。位運算(&)效率要比取模運算(%)高很多,主要原因是位運算直接對記憶體資料進行操作,不需要轉成十進位制,因此處理速度非常快。
注意:a % b == a & (b - 1) 前提:b 為 2^n
- 下面是hash到確定陣列位置的過程圖:
HashMap 如何進行擴容
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超過最大值就不再擴充
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 沒超過最大值,擴充為原來的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 計算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每個bucket都移動到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 連結串列優化重hash的程式碼塊
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket裡
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket裡
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}注意事項
擴容是一個特別耗效能的操作,所以當使用HashMap的時候,估算map的大小,初始化的時候給一個大致的數值,避免map進行頻繁的擴容。
參考:
- JDK1.8 原始碼
- 《資料結構與演算法》
- 維基百科
- 美團:Java 8系列之重新認識HashMap