
Keras---序貫模型
快速開始序貫(Sequential)模型
序貫模型是多個網路層的線性堆疊,也就是“一條路走到黑”。
可以通過向Sequential模型傳遞一個layer的list來構造該模型:
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([
Dense(32, units=784), # 程式碼感覺有誤,應該是input_shape=(784,)
Activation('relu'),
Dense(10),
Activation('softmax'),
])
也可以通過.add()方法一個個的將layer加入模型中:
model = Sequential()
model.add(Dense(32, input_shape=(784,)))
model.add(Activation('relu'))
指定輸入資料的shape
模型需要知道輸入資料的shape,因此,Sequential的第一層需要接受一個關於輸入資料shape的引數,後面的各個層則可以自動的推匯出中間資料的shape,因此不需要為每個層都指定這個引數。有幾種方法來為第一層指定輸入資料的shape
-
傳遞一個
input_shape的關鍵字引數給第一層,input_shape是一個tuple型別的資料,其中也可以填入None,如果填入None則表示此位置可能是任何正整數。資料的batch大小不應包含在其中。 -
有些2D層,如
Dense,支援通過指定其輸入維度input_dim來隱含的指定輸入資料shape。一些3D的時域層支援通過引數input_dim和input_length來指定輸入shape。 -
如果你需要為輸入指定一個固定大小的batch_size(常用於stateful RNN網路),可以傳遞
batch_size引數到一個層中,例如你想指定輸入張量的batch大小是32,資料shape是(6,8),則你需要傳遞batch_size=32和input_shape=(6,8)。
model = Sequential()
model.add(Dense(32 model = Sequential()
model.add(Dense(32, input_shape=784))
編譯
在訓練模型之前,我們需要通過compile來對學習過程進行配置。compile接收三個引數:
-
優化器optimizer:該引數可指定為已預定義的優化器名,如
rmsprop、adagrad,或一個Optimizer類的物件,詳情見optimizers -
損失函式loss:該引數為模型試圖最小化的目標函式,它可為預定義的損失函式名,如
categorical_crossentropy、mse,也可以為一個損失函式。詳情見losses -
指標列表metrics:對分類問題,我們一般將該列表設定為
metrics=['accuracy']。指標可以是一個預定義指標的名字,也可以是一個使用者定製的函式.指標函式應該返回單個張量,或一個完成metric_name - > metric_value對映的字典.請參考效能評估
# For a multi-class classification problem
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# For a binary classification problem
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# For a mean squared error regression problem
model.compile(optimizer='rmsprop',
loss='mse')
# For custom metrics
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy', mean_pred])
訓練
Keras以Numpy陣列作為輸入資料和標籤的資料型別。訓練模型一般使用fit函式,該函式的詳情見這裡。下面是一些例子。
# For a single-input model with 2 classes (binary classification):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# Generate dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# Train the model, iterating on the data in batches of 32 samples
model.fit(data, labels, epochs=10, batch_size=32)
# For a single-input model with 10 classes (categorical classification):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Generate dummy data
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(10, size=(1000, 1))
# Convert labels to categorical one-hot encoding
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
# Train the model, iterating on the data in batches of 32 samples
model.fit(data, one_hot_labels, epochs=10, batch_size=32)
例子
這裡是一些幫助你開始的例子
在Keras程式碼包的examples資料夾中,你將找到使用真實資料的示例模型:
- CIFAR10 小圖片分類:使用CNN和實時資料提升
- IMDB 電影評論觀點分類:使用LSTM處理成序列的詞語
- Reuters(路透社)新聞主題分類:使用多層感知器(MLP)
- MNIST手寫數字識別:使用多層感知器和CNN
- 字元級文字生成:使用LSTM ...
基於多層感知器的softmax多分類:
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import SGD
# Generate dummy data
import numpy as np
x_train = np.random.random((1000, 20))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10)
x_test = np.random.random((100, 20))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
model = Sequential()
# Dense(64) is a fully-connected layer with 64 hidden units.
# in the first layer, you must specify the expected input data shape:
# here, 20-dimensional vectors.
model.add(Dense(64, activation='relu', input_dim=20))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy',
optimizer=sgd,
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)
MLP的二分類:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout
# Generate dummy data
x_train = np.random.random((1000, 20))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 20))
y_test = np.random.randint(2, size=(100, 1))
model = Sequential()
model.add(Dense(64, input_dim=20, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train,
epochs=20,
batch_size=128)
score = model.evaluate(x_test, y_test, batch_size=128)
類似VGG的卷積神經網路:
import numpy as np
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras.optimizers import SGD
# Generate dummy data
x_train = np.random.random((100, 100, 100, 3))
y_train = keras.utils.to_categorical(np.random.randint(10, size=(100, 1)), num_classes=10)
x_test = np.random.random((20, 100, 100, 3))
y_test = keras.utils.to_categorical(np.random.randint(10, size=(20, 1)), num_classes=10)
model = Sequential()
# input: 100x100 images with 3 channels -> (100, 100, 3) tensors.
# this applies 32 convolution filters of size 3x3 each.
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(100, 100, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd)
model.fit(x_train, y_train, batch_size=32, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=32)
使用LSTM的序列分類
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import LSTM
model = Sequential()
model.add(Embedding(max_features, output_dim=256))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)
使用1D卷積的序列分類
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.layers import Embedding
from keras.layers import Conv1D, GlobalAveragePooling1D, MaxPooling1D
model = Sequential()
model.add(Conv1D(64, 3, activation='relu', input_shape=(seq_length, 100)))
model.add(Conv1D(64, 3, activation='relu'))
model.add(MaxPooling1D(3))
model.add(Conv1D(128, 3, activation='relu'))
model.add(Conv1D(128, 3, activation='relu'))
model.add(GlobalAveragePooling1D())
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=16, epochs=10)
score = model.evaluate(x_test, y_test, batch_size=16)
用於序列分類的棧式LSTM
在該模型中,我們將三個LSTM堆疊在一起,是該模型能夠學習更高層次的時域特徵表示。
開始的兩層LSTM返回其全部輸出序列,而第三層LSTM只返回其輸出序列的最後一步結果,從而其時域維度降低(即將輸入序列轉換為單個向量)
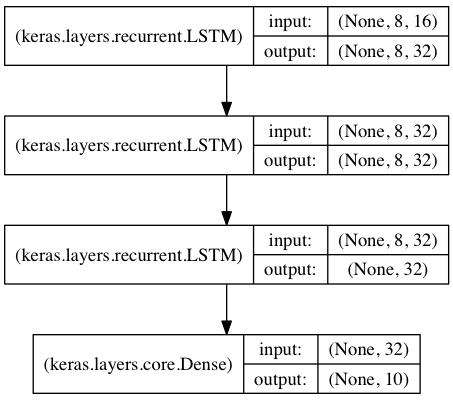
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
# expected input data shape: (batch_size, timesteps, data_dim)
model = Sequential()
model.add(LSTM(32, return_sequences=True,
input_shape=(timesteps, data_dim))) # returns a sequence of vectors of dimension 32
model.add(LSTM(32, return_sequences=True)) # returns a sequence of vectors of dimension 32
model.add(LSTM(32)) # return a single vector of dimension 32
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# Generate dummy training data
x_train = np.random.random((1000, timesteps, data_dim))
y_train = np.random.random((1000, num_classes))
# Generate dummy validation data
x_val = np.random.random((100, timesteps, data_dim))
y_val = np.random.random((100, num_classes))
model.fit(x_train, y_train,
batch_size=64, epochs=5,
validation_data=(x_val, y_val))
採用stateful LSTM的相同模型
stateful LSTM的特點是,在處理過一個batch的訓練資料後,其內部狀態(記憶)會被作為下一個batch的訓練資料的初始狀態。狀態LSTM使得我們可以在合理的計算複雜度內處理較長序列
from keras.models import Sequential
from keras.layers import LSTM, Dense
import numpy as np
data_dim = 16
timesteps = 8
num_classes = 10
batch_size = 32
# Expected input batch shape: (batch_size, timesteps, data_dim)
# Note that we have to provide the full batch_input_shape since the network is stateful.
# the sample of index i in batch k is the follow-up for the sample i in batch k-1.
model = Sequential()
model.add(LSTM(32, return_sequences=True, stateful=True,
batch_input_shape=(batch_size, timesteps, data_dim)))
model.add(LSTM(32, return_sequences=True, stateful=True))
model.add(LSTM(32, stateful=True))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# Generate dummy training data
x_train = np.random.random((batch_size * 10, timesteps, data_dim))
y_train = np.random.random((batch_size * 10, num_classes))
# Generate dummy validation data
x_val = np.random.random((batch_size * 3, timesteps, data_dim))
y_val = np.random.random((batch_size * 3, num_classes))
model.fit(x_train, y_train,
batch_size=batch_size, epochs=5, shuffle=False,
validation_data=(x_val, y_val))